Used Cars Data Scraping - R & Github Actions & AWS

silverstone
Posted on September 12, 2022
Project
It came up with the idea of how to combine Data Engineering with Cloud and automation. I needed to find a data source as it would be an automated pipeline, so I needed a dynamic source. At the same time, I wanted to find a site where I thought retrieving data would not be a problem and do practice with both rvest and dplyr. After I had no problems with my experiments with Carvago, I added the necessary data cleaning steps. Another thing I aimed for in the project was to keep the data in different ways in different environments. While raw (daily CSV) and processed data were written to the Github repo, I wrote the processed data to PostgreSQL on AWS RDS. In addition, I sync the raw and processed data to S3 to be able to use it with Athena. However, I have separated some stages for GitHub Actions to be a good practice. For example, in the first stage, I added synchronization with AWS S3 as a separate action while scraping data, cleaning, and printing fundamental analysis to a simple log file. If there is no error after all this, I added a report with RMarkdown and the action that will be published on github.io. Thus, I created an end-to-end data pipeline where the data from the source is made to offer basic reporting with simple processing.
In addition, I tried to create a pipeline that would keep the cost to a minimum and not reveal any security weaknesses. For this purpose, I added a Lambda function that runs the RDS service before Github Actions run. Likewise, I added another function that stops the DB after a while. Thus, since the DB does not work outside the specified hours, it does not cause an extra cost. At the same time, to prevent any possible external access to the DB, I created a user with limited privileges on the table where the data is written. Since it came with a random IP block from GitHub Actions, I had to allow the traffic rules (security groups) access to the DB everywhere. That's why I changed the default 5432 DB Port to a different one. Finally, I have defined a role for the user who accesses S3 only to access the bucket where it writes data and access only via CLI (programmatic access). I did not use any of them in the code, keeping all this information under Github Actions Secret.
Scraping
![]()
For the car listings to be scraped, the listings per page at carvago must be scraped. Thus, the URLs of each car will be scraped in the first stage. Then the details of the cars will be scraped by going to these URLs in the next stage. Biggest helper here was copy -> xpath. So I could directly access the div blocks with all the required data. So what is copy XPath?
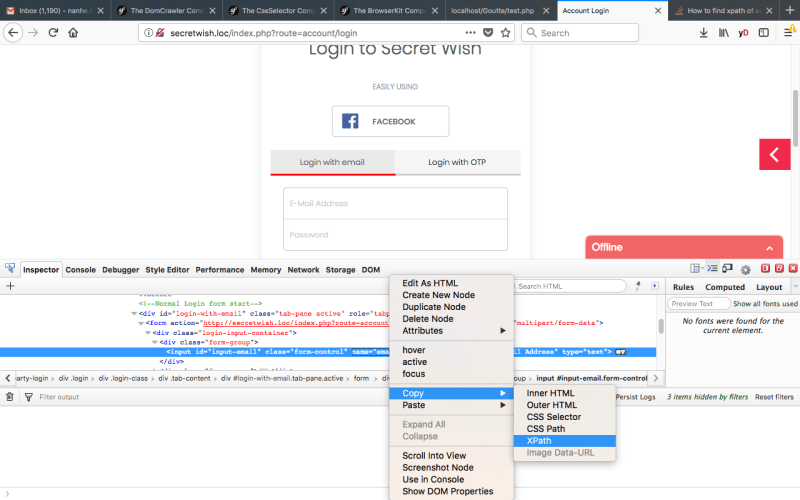
The car for sales listed with
gathererin utils are scraped from each page (there are 20 cars on each page). Thus, a data frame consisting of the title of the car listing, the listing's id, and the listing and the URL of the listing is scraped.With the
ads_to_dffunction in the utils, using the links in the data frame scraped in the first step, the page of the relevant car listings are accessed, and information such as the make, model, registration date (month/year), price, and km of the car are scraped. As I mentioned above, xpaths made my job incredibly easy. I could get the values directly from the div with the data with thehtml_textfunction without checking at different nodes inrvest. All the received information is assigned to a variable to be used later when creating the data frame. Finally, a data frame consisting of a single line of the car listing is created using these variables. The purpose of the function is to turn the information in a single URL into a data frame.
price <- data %>% html_nodes(xpath = '/html/body/div[1]/div/main/section[1]/div[2]/div[2]/div[1]/div/div[1]') %>% html_text()
- Another problem I should mention here is that there may be shifts between the divs because some information is not entered in some listings. Therefore, for example, 4x2 value corresponding to the traction type can be seen in the column where the fuel consumption should be x.y l/100km. For problems arising from this situation, I have set it up to fill with
NAusingifelseif the value of one of the divs is empty during the data frame creation phase. Again, in order to minimize the problem, in analysis.R I added some regex and rule-based fixes. However, while retrieving the data, too many spaces (such as\n) appear due to some characters (e.g. €). I solved this problem usingstri_replace_all_charclass(df$variable, "\\p{WHITE_SPACE}", "")before writing the data. Finally, I created a data frame using all the captured information 👇🏻
df <- data.frame(
make = ifelse(length(make!= 0, make, NA),
model = ifelse(length(model) != 0, model, NA),
...
)
- Finally,
df_makerin utils.R With the function, each of the listings scraped in step 1 is turned into a data frame combined with the for a loop. The detail here is that the function works intryCatch. Normally, if it is only in the loop, the loop breaks on the first 4xx/5xx error. stackoverflow 55937737#55937737) I implemented the solution I came across. In this way, even if the page is removed or there is an access problem, the final data frame is created by going to the next step. Finally, data is written to theraw_datafolder by adding the current date to the data name iny_m_dformat.
Analysis
After the car listings are scraped and written without problems, all the files in the folder are read and converted into a single data frame with the analysis.R script. After cleansing, such as date conversion and text cleaning are performed on the combined data, unique car listings are written to the processed folder. In addition, primitive reporting using the cat function is done. First, a report/daily_report.log file is created using sink, which is constantly overwritten. Thus, all content printed with cat is sent into this file. After writing unique listings is completed, values such as analysis time, total data size, and date range (min-max) in the data are printed. Then, descriptive statistics are calculated with simple groupings and written in tabular format with kable. An example code and table output is as follows;
kable(df %>% group_by(insertdate) %>% count(), format = "pipe")
|insertdate | n|
|:----------|---:|
|22/08/2022 | 99|
|23/08/2022 | 99|
|24/08/2022 | 198|
|25/08/2022 | 194|
|26/08/2022 | 198|
|27/08/2022 | 198|
The data is written to the DB with the df_t_db.R script. This straightforward code takes the name of the last file written in the processed/ folder, reads the latest cumulative data, and inserts this data into the DB.
# get name of the latest file
f <- file.info(list.files("processed/", full.names = T))
f <- rownames(f)[which.max(f$mtime)]
You can access logging file here or here.
Reporting with RMarkdown
Simple logging was done in the analysis part, which was the previous part. At this part, an HTML report page is created using RMarkdown and plots are created with ggplot2.
In addition to the fundamental analysis, the 10 most seen makes, the distribution of vehicles by years, average km, etc., plots are created. Also, a sample data set is provided at the end of the markdown in Data Table format after certain filters using the DT package. At the moment, the plots do not provide much information due to the relatively low number of data and the dominance of some makes, and I plan to make additions after a while.
You can access the report here.
Github Actions (GA)

You can run operating systems such as Ubuntu, Windows, and macOS within the GA flow. You can also use a Docker image where your code run. Therefore, I created an image of packages that may be required for the project. I have an image preparation pipeline, and I used Actions again. The image I use here installs both R and Python on Ubuntu and installs the packages I choose. Such an image naturally becomes quite large in size. To avoid this situation, I used the R image prepared by rocker. I installed required packages using version 4.0.5, which is the version I am developing. Finally, I uploaded it to Dockerhub so that the GA pipeline can be accessed.
Secrets for Actions
While writing the data to the DB, I used Secrets so that no host, username or password is entered in the code. After defining these secrets, which work with the environment variables logic in operating systems, in the repo settings, I specified them in the script where the data is written to the DB and in the actions workflow. You can see the code snippets below.
# df_2_db.R
db_host <- Sys.getenv("DB_HOST")
db_name <- Sys.getenv("DB_NAME")
db_pass <- Sys.getenv("DB_PASS")
db_user <- Sys.getenv("DB_USER")
db_port <- Sys.getenv("DB_PORT")
#workflow.yml
- name: Insert Data to DB
continue-on-error: true
# https://canovasjm.netlify.app/2021/01/12/github-secrets-from-python-and-r/#on-github-secrets
env:
DB_HOST: ${{ secrets.DB_HOST }}
DB_NAME: ${{ secrets.DB_NAME }}
DB_PASS: ${{ secrets.DB_PASS }}
DB_USER: ${{ secrets.DB_USER }}
DB_PORT: ${{ secrets.DB_PORT }}
run: Rscript codes/df_2_db.R
Actions Pipeline
Actions YAML includes Scraper, DataSync and finally rmarkdown jobs.
With Scraper, run_all.R and analysis.R codes are run, and raw & processed data is written. If there is no error after the data is written, pushed to the repo and written to the DB, the second stage, DataSync, is started. After reaching the repo content with actions/checkout@v2, data is written to the bucket with aws-actions/configure-aws-credentials@v1. After the data is written to the bucket, it goes to the 3rd stage, the rmarkdown stage. Unlike the first and second stages, it uses the image I created with cloud-first-initialization instead of the image I created in the part of the docker image. One of the reasons for this is that I do not want to enlarge the rocker image, and all the extra packages required for this stage (rmarkdown, ggplot2, DT etc.) are installed in the image I use.
Since the secrets are defined as I mentioned above, I added them in the secrets.SECRET_NAME format where necessary in the workflow. I stated that the previous stage should be completed with the needs argument. Thus, to proceed to the 2nd stage, no errors should be made in the first stage. The general structure of Workflow is as follows 👇🏻
name: Scraper & Data Sync & Markdown
on:
workflow_dispatch:
schedule:
- cron: "0 20 * * *"
jobs:
scraper:
runs-on: ubuntu-latest
container:
image: silverstone1903/rockerrr
...
datasync:
runs-on: ubuntu-latest
needs: scraper
...
rmarkdown:
runs-on: ubuntu-latest
container:
image: silverstone1903/pythonr
needs: datasync
...
AWS
![]()
Creating PostgreSQL DB on AWS RDS
PostgreSQL DB with free-tier features was created using RDS. Since the DB will be accessed via Github Actions, access from anywhere is defined for the allowed port under the security group. For this reason, a different port has been used instead of the 5432 port in order to prevent a possible vulnerability.
User creation and Granting
After creating a DB with AWS RDS, you can access it using a superuser. However, in a possible bad scenario, to prevent access to your DB with a user with all privileges, it is necessary to create a user that will only be used for writing, with limited privileges in the relevant table.
create user username with password 'pass';
grant select, insert, update on public.tablename to username;
Starting & Stopping RDS DB
Although the DB is free-tier, since I no longer benefit from free-tier, it creates a cost for the time it works and the storage space it uses. However, since there is no production database, it does not need to be in continuous operation. For this reason, I have set up two Lambda functions that will start the service without running the GitHub Actions script and stop it after the script is complete. I have already implemented the shared code example on AWS without thinking about how to do it. Accordingly, the function that will start the RDS is triggered at 22:50, while the function that will turn it off is triggered at 23:50. It can take more than 5 minutes and a similar time to turn off. It is helpful to keep the time long as the GA script may start with a delay. Amazon EventBridge rules manage scheduling.
Alternatively, by adding a code that will trigger Lambdas in GitHub Actions, these operations can be done at the start and end of the run. It should be noted that there should be a step in Actions to check this since the starting time takes 5 minutes (sleep, etc.).
Also, Amazon Aurora Serverless can be used as an alternative.
S3 Access
In addition to keeping the data in the repo and the DB, I also wanted to synchronize it on S3. I created a user with IAM to write data to S3. I defined the privilege to access this user only from the CLI and created a new role in S3 so that it can only access the bucket where it will write data. I have defined full authorization only for the relevant bucket with the policy and the details below. There is no need for the bucket to be public with this user.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetBucketLocation",
"s3:ListAllMyBuckets"
],
"Resource": "arn:aws:s3:::*"
},
{
"Effect": "Allow",
"Action": "s3:*",
"Resource": [
"arn:aws:s3:::bucket-name",
"arn:aws:s3:::bucket-name/*"
]
}
]
}
Currently, the Actions script is triggered at 23:00 Turkey time zone (GMT+3). 10 pages (200) of data are scraped daily. The pipeline takes about 6 minutes, including 2 docker images being pulled.
Those who want to access the data can only access it through the repo for now.
Repo: silverstone1903/used-car-scraper
Log: link
RMarkdown Report: link
Turkish Blog post: link
Resources
- https://canovasjm.netlify.app/2021/01/12/github-secrets-from-python-and-r/#on-github-secrets
- https://stackoverflow.com/a/67041362
- https://aws.amazon.com/blogs/database/schedule-amazon-rds-stop-and-start-using-aws-lambda/
- https://stackoverflow.com/questions/8093914/use-trycatch-skip-to-next-value-of-loop-upon-error/55937737#55937737
Posted on September 12, 2022
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.