Re-platforming to AWS Lambda container images

SEB
Posted on May 26, 2023
This is an attempt at how event-driven backend processing services can potentially be migrated with minimum changes from a container orchestration service to AWS Lambda powered by container images.
The driver for this story was one of my recent migration projects where a fleet of services running on an old EKS version had to be migrated to a brand-new environment running the latest versions of everything. During that journey, one of the weaknesses that got revealed in the architecture of the system in question was insufficient resistance to data loss due to the lack of loose coupling capabilities. That made me think… firstly, how a particular backend processing service can be redesigned accordingly, and secondly, whether we need EKS for this at all.
For the sake of this story let’s say the former has already been solved and so I’m going to focus on the latter as one of the exercises I did was checking how difficult re-platforming a containerized service from Amazon ECS or Amazon EKS to AWS Lambda with container images support is.

EKS, ECS, and Lambda
It’s important to emphasize again that I’m focusing on an event-driven backend processing service which is why this comparison is focused on a specific, but still common, use case rather than a holistic capabilities overview of these services. EKS, ECS, and Lambda are not mutually exclusive and each of these services is better at one thing while less optimal at the other. It’s usually a game of trade-offs anyway but depending on a scenario, workload type, number of services in an environment, etc., to come up with the best architecture those services from AWS can be combined or implemented interchangeably. My observations show that Lambda is barely considered whenever containerized workloads are in use, if at all. These days, containers usually equal Kubernetes.
Event-driven architecture
Conceptually, I’m a big fan of this type of architecture. Do only when there’s something to do and upon getting notified about it. Once done, turn off the lights and wait for another alarm to be woken up. Repeat forever. It’s efficient, sustainable, and cost-effective.
While Lambda along with other serverless services is designed to be at the heart of event-driven solutions, both EKS and ECS can be used to deal with such requirements, however, not always efficiently enough and not without additional overheads or complexity associated.
Scaling
One of the crucial capabilities of a service that is used to support event-driven architecture is dynamic and adaptive scaling. Lambda is known for its native scaling capabilities and handling of in-flight requests in parallel that can be controlled and supported with the use of the concurrency settings that were comprehensively described here. A Lambda function can be triggered by the majority of relevant AWS services, if not all of them, and therefore perfectly adapts to unpredictable traffic events.
In the world of Kubernetes, with EKS, there are add-ons (autoscalers) like Keda that enable similar capabilities with the use of supported scalers and allow for pod scaling based on external metrics.
ECS on the other hand supports so-called step scaling that leverages CloudWatch alarms and adjusts the number of service tasks in steps based on the size of the alarm breach. Interestingly, that type of scaling is not recommended as per the ECS Developer Guide which is why I decided to give it a try as a part of a PoC for this story. An alternative approach that I’ve seen people implementing is a Lambda function triggered periodically that watches a given external metric and based on its value manipulates the number of running ECS tasks. Even then, it’s not flexible and automatic as thresholds must be predefined.
Migration, modernization, re-platforming
While migrating more and more workloads to the cloud remains high on the list of initiatives organizations want to make progress on, according to Flexera 2023 State of the Cloud Report cost savings is the top one for the seventh year in a row. Moreover, 71% of heavy cloud users want to optimize the existing use of the cloud.


At the same time, cloud spend along with security and expertise are the top three cloud challenges recognized.

Therefore, a potential path leading to cost optimization that simultaneously can elevate security and doesn’t necessarily require extensive expertise is modernizing with the use of AWS Lambda.
Depending on where you are with your cloud adoption journey and what the key business drivers are, you should choose the most appropriate migration strategy for your workloads. Modernization is something you can go for straight away or consider as the next step after re-hosting first.
Re-platforming can turn out to be a golden mean as it allows for reshaping by leveraging cloud-native capabilities without modifying the application source code or its core architecture. That way you can benefit from increased flexibility and resilience with reduced time and financial investments. Obviously, it doesn’t mean it is the way and any decision on implementing any strategy should be supported by relevant analysis.
PoC: ECS to Lambda
Let’s imagine a scenario where the goal is to re-platform from ECS to Lambda with zero or minimal changes to:
- application code (Python)
- container image build process (Dockerfile) to reduce risks associated with the platform change itself. Why ECS and not EKS? Because for some reason I haven’t got much experience with it hence considered this a chance to see what it’s capable of in the given scenario and let myself expand my horizons.
HLD
It’s about re-platforming from this…

to this…

Application code
What this sample code below does is it receives messages from a given SQS queue and deletes them immediately. That’s it, just enough for this PoC.
# app.py
import os
import boto3
QUEUE_URL = os.environ.get("SQS_QUEUE_URL", "")
MAX_NUM_MSGS = int(os.environ.get("SQS_MAX_NUM_MSGS", 10))
VISIBILITY_TO = int(os.environ.get("SQS_VISIBILITY_TO", 15))
WAIT_SECONDS = int(os.environ.get("SQS_WAIT_SECONDS", 10))
sqs_client = boto3.client("sqs")
def handler(event, context):
get_response = sqs_client.receive_message(
QueueUrl=QUEUE_URL,
MaxNumberOfMessages=MAX_NUM_MSGS,
VisibilityTimeout=VISIBILITY_TO,
WaitTimeSeconds=WAIT_SECONDS,
)
messages = get_response.get("Messages", [])
messages_length = len(messages)
print(f"Number of messages received: {messages_length}")
for msg in messages:
print(f"Message body: {msg['Body']}")
del_response = sqs_client.delete_message(
QueueUrl=QUEUE_URL, ReceiptHandle=msg["ReceiptHandle"]
)
print(
f"Deletion status code: {del_response['ResponseMetadata']['HTTPStatusCode']}"
)
if __name__ == "__main__":
handler("", "")
Dockerfile & RIC
The only thing that had to be added to the existing Dockerfile, for Lambda to work with a container image, was installing the AWS runtime interface client (RIC) for Python — one additional line still keeping the image generic.
FROM python:3.10
WORKDIR /app
COPY requirements.txt .
RUN pip install -r requirements.txt
RUN pip install awslambdaric
COPY app.py .
CMD ["python", "app.py"]
RIC is an implementation of the Lambda runtime API that allows for extending a base image to become Lambda-compatible and is represented by an interface that enables receiving and sending requests from and to the AWS Lambda service. While it can be installed for Python, Node.js, Go, Java, .NET, and Ruby, AWS also delivers Amazon Linux-powered container images for those runtimes here. Even though they might be bigger than standard (slim) base images they are pro-actively cached by the Lambda service meaning they don’t have to be pulled entirely every time.
Lambda function configuration
From the Lambda function configuration perspective, to instruct Lambda how to run the application code both ENTRYPOINT and CWD settings must be overridden as follows:

And that’s it. It’s ready to be invoked.
Parallel testing
For that purpose, I have used the SQS queue seeder Python code below and ran it from Lambda. Based on the settings provided, it generates random strings and sends them as messages to as many queues as you want, in this case, there were two, one for ECS and another one for Lambda.
# sqs_seeder.py
import os
import random
import time
import string
import boto3
# SQS queues
SQS_QUEUE_URLS=[
# queue for ECS,
# queue for Lambda,
]
# Settings
NUMBER_OF_MSG_BATCHES = 50
MAX_MSGS_PER_BATCH = 5
MIN_SECONDS_BETWEEN_MSG_BATCHES = 5
MAX_SECONDS_BETWEEN_MSG_BATCHES = 15
sqs_client = boto3.client("sqs")
def sqs_send_msg(msgs_count):
MSGS_COUNT = msgs_count
print(f"[INFO] Number of messages in batch: {MSGS_COUNT}")
while MSGS_COUNT > 0:
MESSAGE_CHAR_SIZE = random.randint(10, 50)
MESSAGE = "".join(random.choices(string.ascii_uppercase, k=MESSAGE_CHAR_SIZE))
for queue_url in SQS_QUEUE_URLS:
try:
print(f"[INFO] Sending message {MESSAGE} to {queue_url}")
response = sqs_client.send_message(
QueueUrl=queue_url,
MessageBody=MESSAGE,
)
print(f"[INFO] Message sent, ID: {response['MessageId']}")
except Exception as error:
print(f"[ERROR] Queue URL: {error}")
MSGS_COUNT -= 1
def handler(event, context):
global NUMBER_OF_MSG_BATCHES
print(f"[INFO] Number of message batches: {NUMBER_OF_MSG_BATCHES}")
BATCH_NUMBER = 1
while NUMBER_OF_MSG_BATCHES > 0:
print(f"[INFO] Batch number #{BATCH_NUMBER}")
NUMBER_OF_MSGS = random.randint(1, MAX_MSGS_PER_BATCH)
sqs_send_msg(NUMBER_OF_MSGS)
BATCH_NUMBER += 1
NUMBER_OF_MSG_BATCHES -= 1
if NUMBER_OF_MSG_BATCHES > 0:
SLEEP_TIME = random.randint(MIN_SECONDS_BETWEEN_MSG_BATCHES, MAX_SECONDS_BETWEEN_MSG_BATCHES)
print(f"[INFO] Sleeping {SLEEP_TIME} seconds...")
time.sleep(SLEEP_TIME)
if __name__ == "__main__":
handler("", "")
Here are the ECS service step scaling policies configured that didn’t do what I initially thought they would do but more on this later.
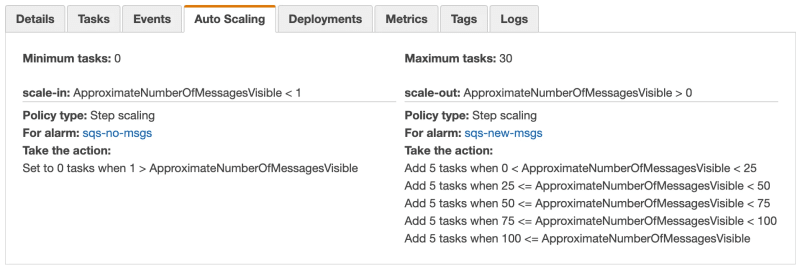
The Lambda function was configured with reserved concurrency set to 1 to try to give ECS a head start.
The screenshot below shows relevant metrics illustrating how messages were being loaded, received, and deleted from the two individual queues.

Clearly, something wasn’t right about ECS step scaling. It’s just not what I was hoping for. I thought it would be continuously adding 5 tasks as the number of messages in the queue grows but that wasn’t the case. According to the scale-out action, for the second run, I expected to get 15 tasks while the DesiredTaskCount remained at the level of 5, so it looks like a one-off scaling operation that is not adaptive over time. I admit I got misled by the Set/Add actions available there. I should have done better at reading and managing my expectations. Now I see why it wasn’t recommended.
Either way, it is also crystal clear when looking at the metrics that Lambda scaling is seamless and fast while ECS needs time before the CloudWatch alarm kicks in. That is because for AWS metrics the minimum period is 1 minute and so the reaction is not immediate.
Finally, not sure why but the scale-in action didn’t work, namely, it did not set the number of tasks to 0 even though the alarm history was showing that the action was successfully executed. I had to do it by hand.
When it comes to SQS itself, I learned one thing that seems important from the performance and efficiency point of view. Namely, having the MaxNumberOfMessages set to 10 (max) for the ReceiveMessage API call when the number of messages is not big enough, it will still return a single message most of the time. More on that here.
Wrap-up
While I had no intention of going deep into ECS step scaling and demystifying things, even if it worked the way I expected it would still perform worse than Lambda. However, this is not about judging but about knowing your options and their constraints. It is also about realizing caveats relevant to the integration points and their limitations too. While one service may seem to be fit for purpose, there might be something else that will eventually have a decisive impact on the final design.
The takeaway is that thanks to containers' portability such a comparison doesn’t necessarily have to be difficult to execute or requires much effort to draw some conclusions that will help in decision-making. A Lambda function powered by a container image is probably one of the easiest things to configure and so as long as there are no obvious obstacles, quite the opposite, when there are indications of potential improvement, why wouldn’t you give it a chance? The worst thing that can happen is that you’ll end up with additional arguments for your decision.
Again, know your options! Don’t hesitate to try things out by running PoCs to find the best solution and remember that modernization is a continuous improvement process that never ends. Technology, business requirements, functionalities, and KPIs keep on changing over time, therefore, try to continuously assess your solutions against the AWS Well-Architected Framework and strive for optimization.
Posted on May 26, 2023
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.