Implementing an Organisational Cloud Resource Tagging Strategy Using Amazon Textract, AWS Lambda and Boto3.

Wonder Agudah
Posted on February 29, 2024

Asset management is imperative in the execution of a cloud governance framework. The process of applying key value pairs known as tagging that contains important information and constitutes the metadata of resources in a cloud environment(An AWS account in this case) helps achieve this goal. Services such as Tag Editor and Resource Groups in AWS offer the ability to perform this action(tagging). However, this process can quickly get cumbersome. Especially when there is a large number of tags to be collected from a variety of sources and applied across a wide array of resources and workloads provisioned in an AWS account.
I recently had to perform this operation at work and I encountered the challenge that arises when there are many tags to be applied on many resources in an AWS account.
In pursuit of the company's cloud governance objectives. Forms were distributed to each department under the company to collect tag info. To appreciate the vast amount of data to be collected, an itemised list of some departmental units that are operative in any large scale organisation and business have been outlined below.
-
Human Resources (HR):
- Personnel Management
- Recruitment
- Training
- Employee Relations
- Compliance with Employment Laws
-
Finance and Accounting:
- Financial Planning
- Budgeting
- Accounting
- Financial Reporting
- Financial Analysis
-
Marketing:
- Marketing Strategy
- Advertising
- Branding
- Market Research
-
Sales:
- Selling Products or Services
- Customer Relationship Management
- Sales Target Achievement
-
Information Technology (IT):
- Technology Infrastructure Management
- Hardware and Software Management
- Network Management
- Cybersecurity
-
Operations:
- Day-to-Day Business Operations
- Process Optimization
- Supply Chain Management
- Production Oversight
-
Customer Service:
- Customer Inquiry Handling
- Customer Support
- Complaint Resolution
-
Research and Development (R&D):
- Research for New Products
- Improvement of Existing Products
- Innovation
-
Legal:
- Legal Counsel
- Contract Management
- Compliance with Laws and Regulations
- Management of Legal Risks
-
Administration:
- Office Management
- Facilities Management
- Administrative Support
-
Quality Assurance (QA) or Quality Control (QC):
- Ensuring Product or Service Quality
- Compliance with Quality Standards
-
Supply Chain or Logistics:
- Goods Movement
- Inventory Management
- Overall Supply Chain Oversight
-
Public Relations (PR):
- Communication with the Public
- Media Relations
- Stakeholder Communication
-
Project Management:
- Project Planning
- Project Execution Oversight
-
Strategic Planning:
- Long-Term Goal Setting
- Growth and Success Planning
-
Compliance:
- Ensuring Adherence to Laws and Regulations
- Industry Standards Compliance
-
Internal Audit:
- Internal Auditing
- Compliance Audits
- Financial Practice Audits
-
Training and Development:
- Employee Training Programs
- Professional Development Initiatives
Cost Center
Application Owner
After the painstaking effort involved in the manual collection and entry of tag information across all departments of an organisation into one comprehensive document. A more cumbersome task is involved in manually entering this tags on all development, QA and production EC2 instances and their associated EBS volumes as well as snapshots after they have been scanned and stored in a digital format.
Amazon Textract is a machine learning service offered by AWS that reduces the manual efforts and automates the process involved in the extraction of any kind of data such as forms, tables, and texts from scanned documents, making it expedient to derive important information from different sources.
Combining the above service with Boto3; the Python SDK for AWS and AWS Lambda, I architected a solution to ease and automate this effort using Amazon Textract. By automating the process of extracting this info I was able to write a script that applied this extracted data to all EC2 instances and further replicated them to their associated EBS volumes and snapshots.
This project will be demonstrated in a two part series. This article will demonstrate how to perform this action using
the Amazon Textract console to ensure that users who are just starting out with AWS can get comfortable implementing this solution using the AWS console. A second article as part of this series will also be put out and focus will be centered on how to perform this entire solution programmatically by using the AWS Boto3 documentation for Amazon Textract targeted for intermediate cloud practitioners in AWS and with considerable experience in programming.
Extracting Text from Documents with Amazon Textract in the AWS Console
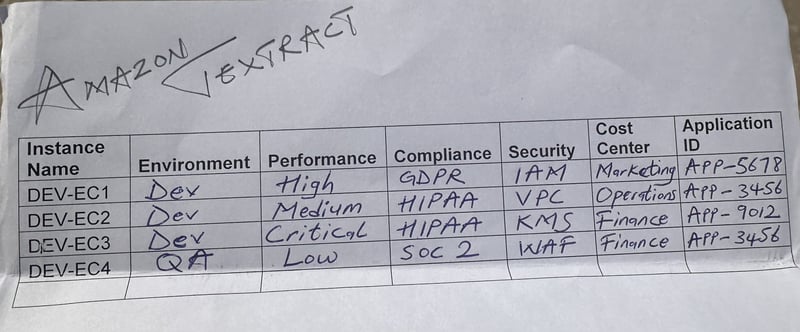
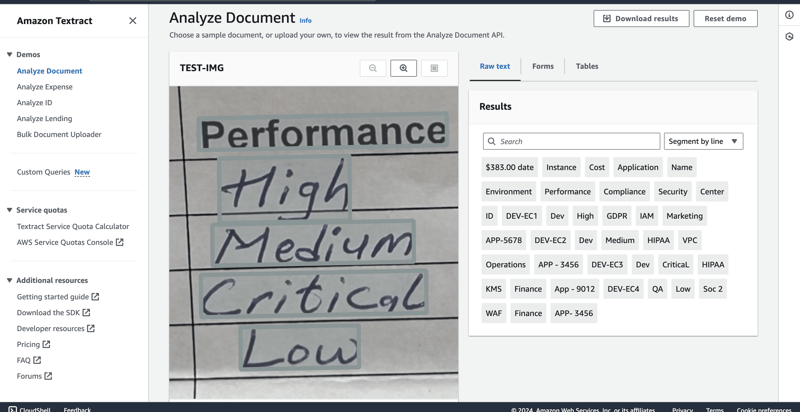
Since tags are essentially key value pairs, I drafted a sample document as attached below and in the cover image of this article showing varying field entries and their associated keys in this scenario in order to adhere with compliance and security standards as the actual scanned tagging document contains company's info.
A. Sign in and Access Textract:
- Sign in to the AWS Management Console at https://aws.amazon.com/.
- Search for "Amazon Textract" and select it.
B. Choose a Document:
* Upload document: Upload your own document in PNG, JPEG, or PDF format.
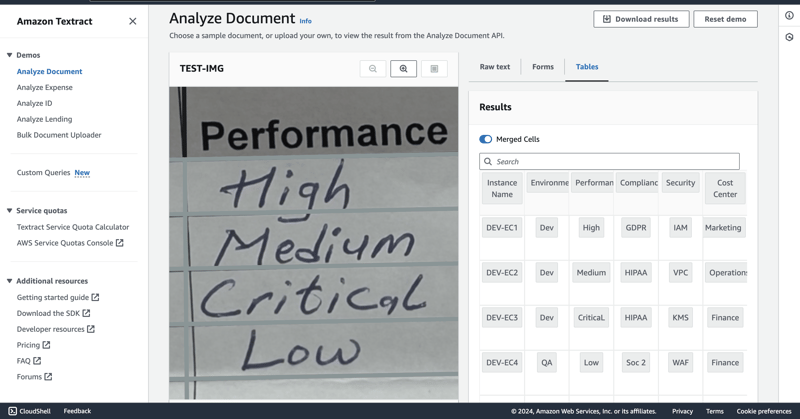
C. Analyze the Document:
- In the right pane, select the type of information you want to extract:
- Raw text: Extracts all text using Optical Character Recognition (OCR).
- Lines: Extracts individual lines of text.
- Words: Extracts individual words.
D. Explore the Extracted Data:
- Explore the other tabs for further analysis options:
- Blocks: Identifies and categorizes text blocks based on their location and content.
- Tables: Extracts data from tables within the document.
- Forms: Identifies form fields and extracts their corresponding values.
E. Download Results (Optional):
- Click the "Download JSON" button to download the extracted data in JSON format for further processing.
PS: This tutorial provides a basic overview. For detailed information and advanced functionalities, refer to the official Amazon Textract documentation: https://docs.aws.amazon.com/textract/
At this point, as depicted in the above process on using Amazon Textract to extract the key value pair information that was manually entered in the sample form for collecting tag information, the extracted tags can be applied to the specified EC2 resources. Considering the fact these are just a few instances, the tag information can be applied using AWS Tag Editor. The second part of this article will perform this action programatically to cater for use cases were there are a myriad of instances.
After applying the tags to DEV-EC1, DEV-EC2, DEV-EC3, and DEV-EC4, a lambda function with runtime; Python 3.9 can be created using the code block below to replicate the applied tags to all EBS volumes attached to the respective EC2 instances as well as the captured snapshots. Also attach the IAM policy;AmazonEC2FullAccess to the permissions of the role of the AWS Lambda function.
import boto3
def lambda_handler(event, context):
# Get a list of all AWS regions
ec2_regions = [region['RegionName'] for region in boto3.client('ec2').describe_regions()['Regions']]
# Iterate through each region
for region in ec2_regions:
print(f"Working in region: {region}")
# Initialize the EC2 client for the current region
ec2_client = boto3.client('ec2', region_name=region)
# Get all instances with their tags
instances_info = ec2_client.describe_instances(Filters=[{'Name': 'instance-state-name', 'Values': ['running']}])
# Prepare a mapping of instance ID to its tags
instance_tags_map = {}
for reservation in instances_info['Reservations']:
for instance in reservation['Instances']:
instance_tags = [tag for tag in instance.get('Tags', []) if not tag['Key'].startswith(('DEV:'))]
instance_tags_map[instance['InstanceId']] = instance_tags
# Get all EBS volumes and their snapshots in this region
volumes_info = ec2_client.describe_volumes()
snapshots_info = ec2_client.describe_snapshots(OwnerIds=['self'])
# Iterate through each volume and its associated snapshots
for volume in volumes_info['Volumes']:
# Get the volume ID
volume_id = volume['VolumeId']
# Check if the volume has attachments
if 'Attachments' in volume:
# Get the instance ID to which the volume is attached
instance_id = volume['Attachments'][0]['InstanceId']
# Get tags of the associated instance
instance_tags = instance_tags_map.get(instance_id, [])
# Apply instance tags to the volume
if instance_tags:
ec2_client.create_tags(
Resources=[volume_id],
Tags=instance_tags
)
# Tag the snapshots associated with the volume
for snapshot in snapshots_info['Snapshots']:
if snapshot['VolumeId'] == volume_id:
ec2_client.create_tags(
Resources=[snapshot['SnapshotId']],
Tags=instance_tags
)
print(f"Tags copied from EC2 instances to their associated EBS volumes and snapshots in {region}")
print("Script completed in all regions.")
In the above code I listed a few instances to perform this process on by indicating the instance name prefix “DEV”. To apply this same process on a fleet of EC2 instances with a naming convention for Dev,Test and Prod, the logic can be modified to perform this action on all instances with a prefix of Prod for instances rather than manually entering the instance ids of all EC2 instances.
Since AWS Lambda has a default timeout of 3 seconds, increment this value accordingly to accommodate the number of instance tags to be replicated across attached EBS volumes and captured snapshots. The execution time of Lambda has a threshold of 15 minutes. Thus, ensure that the processing logic for your use case is written to be as efficient as possible.
Posted on February 29, 2024
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related
February 29, 2024