Enhance Your Slack Workspace with a user-trainable ChatGPT-Integrated FAQ Bot

Gabriel Koo
Posted on April 26, 2023

Update (2024-09-28)
If you want a more powerful version that utilized Amazon Bedrock, as well as tools calling and a proper vector database, check out the newer version of this Slack chatbot https://github.com/gabrielkoo/self-learning-rag-it-support-slackbot!
TLDR
This AWS & AI-powered chat bot solution costs around US$$0.009 per question only. And you may find an end-to-end tutorial on setting it up (in less than 30 minutes) at the end of this article.
Introduction
How much time do you spend on asking/answering questions about things that requires some internal context of your team/organization? Have you ever thought of an almighty AI that can does all the answering for you?
In this blog post, I'll walk you through the rationale of creating a user-trainable ChatGPT-integrated FAQ bot for your Slack workspace.
This bot will help boost your team's productivity by saving time on questioning, searching, and answering. By leveraging AWS services such as AWS SAM, AWS Lambda, and S3, we can create a cost-effective and efficient FAQ bot for your organization.
Let's jump straight into a demo.
Demo
The demo bot is connected to episodes data from Wikipedia pages about the Disney+ TV Series "The Mandalorian".
The bot recognizes Grogu:

But it doesn't know who I am:
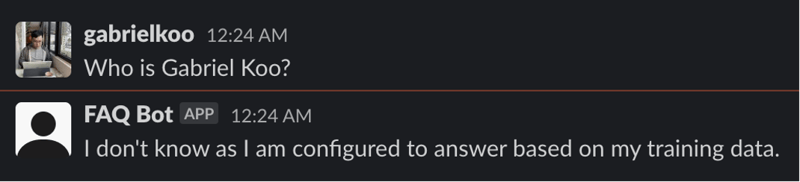
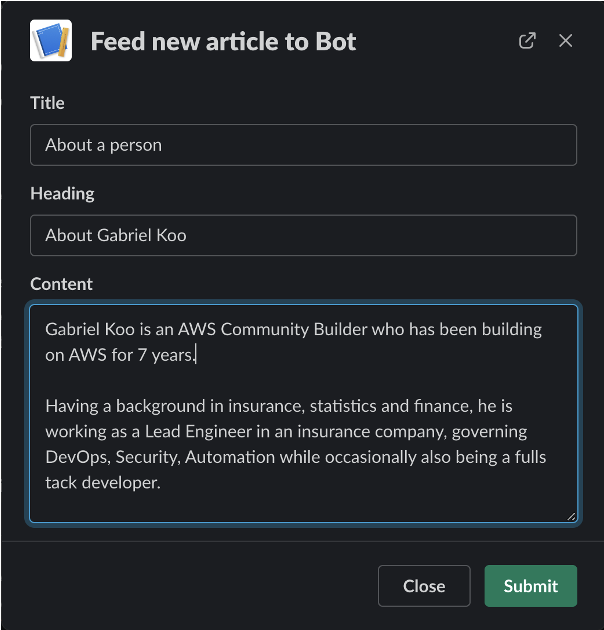
To remedy this, I can submit a new article to the bot:
(Note that it's still rare to see a ChatGPT/Embedding powered application to have such a "direct feedback" function as of now)
Now the bot can answer my question:
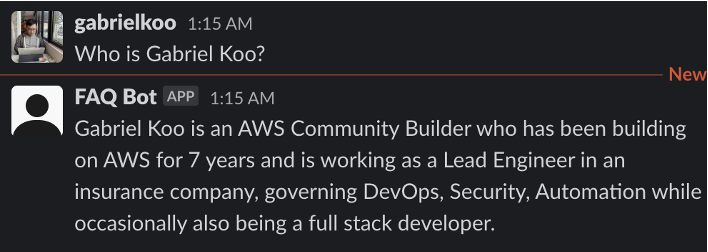
It's cool isn't it?
Background
ChatGPT's API became available in March 2023, sparking excitement and numerous integrations all over the world. Two integrations that caught my attention are:
-
Combing Embedding Search with ChatGPT to build a FAQ engine - it's a way of:
Knowledge Base Question Answering (KBQA) to create a FAQ engine - this involves:
- Natural language understanding (using text embeddings for questions)
- Information retrieval (using text embeddings for articles, matching against the question's embeddings)
- Knowledge representation (using ChatGPT to select and present information)
- Connecting ChatGPT with a programmable messaging platform like Slack
But so far, I have not seen any open-source project that:
- combines the two together
- provides a easy hosting method like AWS SAM, and lastly
- provides a functionality to let the user submit extra knowledge into the embedding dataset.
The third point is crucial because, in the post-OpenAI era, a costly data scientist shouldn't be required to build a FAQ engine. Instead, users should contribute knowledge to the dataset, allowing the AI to learn from collective intelligence.
So, I built one myself.
It's 2023, Let's Go Serverless
Back in 2016 when I was working in a consultancy company as an intern, I built and hosted a Neural Network (NN) based Slack chatbot on a (still free in 2016) dyno on Heroku to cater for questions like "Where should we go for lunch?" or "Pick two colleagues to buy tea for us.". The whole setup was very tedious:
- Every time when I add a new sample question into the NN (and burning my laptop due to high CPU usage), I had to re-train the model locally again
- I had also checked in the (big) model datafile into GitHub, so that Heroku would deploy the file as part of the codebase (and it took a long time for every deployment)
The bot was basic, using a classifier to determine the context with the highest probability and calling a hardcoded function accordingly.
However, it's 2023 now. With models like ChatGPT and OpenAI's Embedding models, we can focus on user experience and architecture. That's why I've built the /submit_train_article command to let end users to further train the Slack bot in my application.
Why using AWS SAM?
AWS SAM is an open source framework for building serverless applications on AWS. The greatest benefit is it provides shorthand syntax to express various cloud resources in a very simple way.
Not only is it simple, it also does a lot of work for you under the hook such as
- creating the right permission role for your serverless function so that it won't be a new attack service for your existing cloud resources.
- building bundles for the required packages of your serverless function code
Lastly it's transferrable. There are so many open-sourced SAM projects on repositories like GitHub, so that you can just quickly experiment various solutions architected by others by deploying them easily - while skipping the need to provision every resources by yourself.
How it works
You may take a look at the diagrams below:
The architecture diagram:
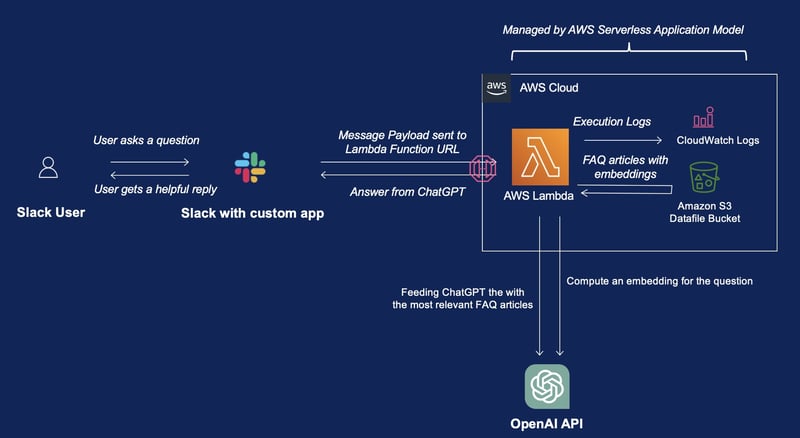
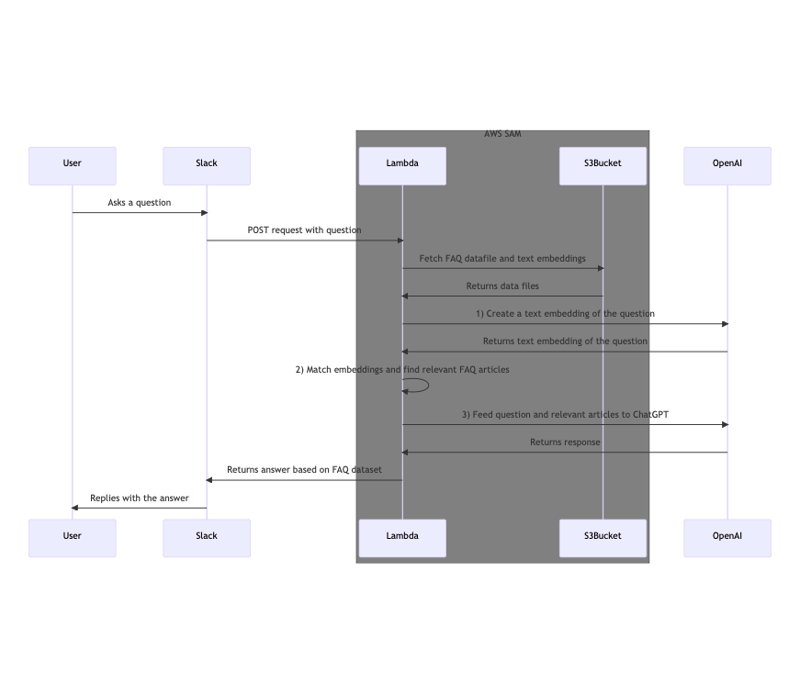
Sequence diagram for the Q&A flow:
Sequence diagram for the new training article submission flow:
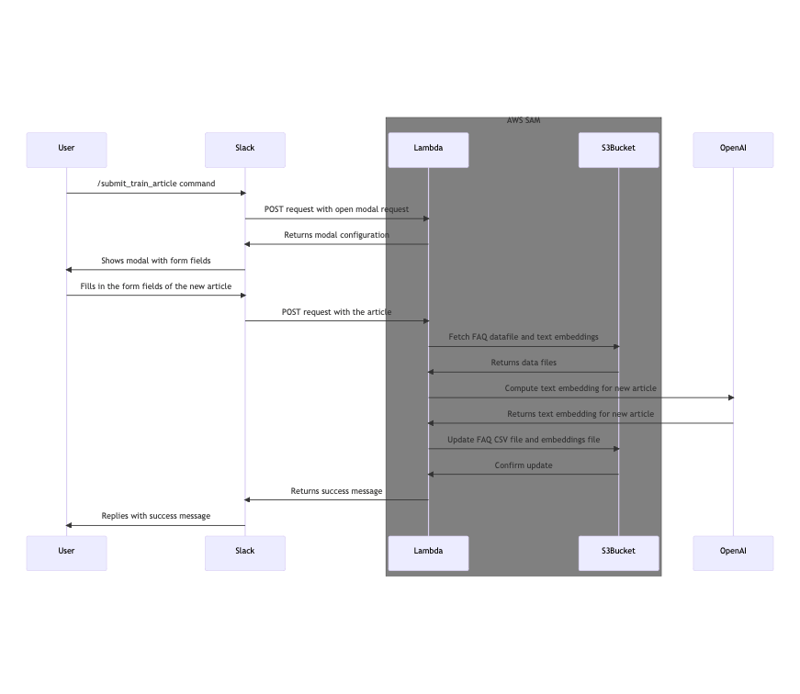
In simple words, here's how it works:
- The question is converted into an "Embedding" with OpenAI's Embedding API
- The embedding of the question is compared against other embeddings generated from the FAQ article database
- The top few articles, together with the original question, is fed into ChatGPT
- ChatGPT gives a helpful answer to the question based on the relevant information, so that it would never answer you something like "I am sorry, but I do not have access to some info within your company".
Architecture and Infrastructure
The entire integration is built using AWS SAM, consisting of the following two main components:
- A Lambda function that handles the Slack API requests, it's possible with the new Function URL feature that was released in 2022. This saves us from the trouble of setting up an API Gateway.
- An AWS S3 bucket to store the datafiles, that includes a CSV file of the articles, and a CSV file of the document embeddings.
Yeah that's it! With AWS SAM, things are simply so simple, and all these are defined in template.yml.
In just less than 100 lines, we could define all the infrastructure we need with AWS SAM:
Transform: 'AWS::Serverless-2016-10-31'
Parameters:
OpenaiApiKey:
Type: String
Description: OpenAI API key
NoEcho: true
SlackBotToken:
Type: String
Description: Slack API token of your App, refer to "Installed App" settings, "Bot User OAuth Token" field.
NoEcho: true
SlackSigningSecret:
Type: String
Description: Signing secret of your Slack App, refer to "Basic Information" settings, "App Credentials" > "Signing Secret"
NoEcho: true
Resources:
Function:
Type: 'AWS::Serverless::Function'
Properties:
Runtime: python3.9
CodeUri: ./function
Handler: lambda_function.lambda_handler
Environment:
Variables:
OPENAI_API_KEY: !Ref OpenaiApiKey
SLACK_BOT_TOKEN: !Ref SlackBotToken
SLACK_SIGNING_SECRET: !Ref SlackSigningSecret
DATAFILE_S3_BUCKET: !Ref DataBucket
Layers:
- !Ref PythonLayer
MemorySize: 1024
Timeout: 15
Policies:
- AWSLambdaBasicExecutionRole
FunctionUrlConfig:
AuthType: NONE
Policies:
- S3CrudPolicy:
BucketName: !Ref DataBucket
PythonLayer:
Type: AWS::Serverless::LayerVersion
Properties:
ContentUri: ./layer
Metadata:
BuildMethod: python3.9
DataBucket:
Type: AWS::S3::Bucket
Properties:
BucketName: !Sub '${FunctionName}-data'
Outputs:
FunctionUrlEndpoint:
Description: 'Lambda Function URL Endpoint'
Value:
Fn::GetAtt: FunctionUrl.FunctionUrl
(Truncated for simplicity, you can look at the full version here.)
In the template above, you can have:
- An AWS Lambda in 23 lines
- An AWS Lambda Layer in 6 lines(for the Python packages like OpenAI SDK)
- An S3 Bucket in 4 lines
And a lot of unsung heroes are also created for you:
- CloudWatch logging configuration that stores the bot's logs
- An IAM Role that authorizes the AWS Lambda to a. get and write S3 files in the data file bucket b. write logs into CloudWatch Logs
- A publicly callable HTTP endpoint (So that you don't need to provision a virtual machine for a web server)
Serverless is Really Cool
Here I would also like to express how excited it is to be able to setup such a smart FAQ chatbot in a Serverless way.
Using Lambda and Lambda Function URL as the web server S3 for data storage allows you to train your model locally and upload the latest models to the bucket. The Slack bot will then use the most recent dataset to serve your users. This approach is cost-effective, as it eliminates the need to provision a virtual machine for running a lightweight web server and avoids storing large model data files on the virtual machine.
I did consider other storage options like DynamoDB or RDS, but these solutions are not as lightweight as S3, and that we always need the full embedding dataset to compute the "article similarity" so that both a SQL and NoSQL database doesn't help much. Though I did consider binding an Amazon Elastic File System (EFS) into the Lambda, the steps to set it up seems to be much larger than S3, so that's why I made the choice.
Cost Effective, Yet Powerful
Let's assume you are using the current ChatGPT 3.5 pricing, even if you are using all 4k tokens in every pair of Q&A, with the question being ask having 500 tokens...
For OpenAI's usage side:
For Embedding,
($0.0004/1K tokens) * 1k tokens
= $0.0004/question
For ChatGPT,
($0.002/1K tokens) * 4k tokens
= $0.008/question
OpenAI total $ per question: $0.0084
For AWS's side:
I assume that each call requires a 1GB RAM worker running for 10 seconds, with Lambda Function URL handling 50KB of data, and lastly the data file being 100MB in total.
Computation
($0.0000166667 for every GB-second) * 1GB * 10s
= $0.000166667
Request
($0.20 per 1M requests) * 1 request
= $0.0000002
S3 Retrieval
($0.0004 per 1000 requests) * 1 request
= $0.0000004
P.S. Data transfer from S3 to Lambda is free (if they are in the same region)
AWS total $ per question: $0.000167267
Total $ per question: $0.008567267.
This is simply so inexpensive, especially the cost on AWS's side! It should be noted again, that this integration can give you a helpful answer in just 10 seconds! Say if you were looking for some information within your company's knowledge base, it could have taken you a few minutes to lead to a similar answer from the bot.
With the same budget, this AI-based chatbot is answering questions with a much fast speed and lower cost than a human assistant!
Overall, this chatbot could be helping a lot of things when scaled up:
- Replace the company internal knowledge base like Confluence or StackOverflow
- Act as an assistant of your company's customer service team
And the power of such a setup won't stop growing when your users submit more and more knowledge base articles into it.
Deploy it onto your Slack Workspace!
Are you convinced that it's great to setup a bot like this?
If so, to set up your own ChatGPT-integrated FAQ bot, follow these steps:
- Clone the source code from my GitHub repository: https://github.com/gabrielkoo/chatgpt-faq-slack-bot
- Prepare your FAQ dataset in CSV format.
- Generate the embeddings file locally.
- Create your Slack app and install it into your Slack workspace.
- Deploy the SAM application using the provided template.
- Configure the Lambda Function URL in your Slack App's "Request URL" settings in Event Subscriptions and Slash Commands.
If your FAQ dataset is ready, you can complete the setup in just 30 minutes.
Transform your team's productivity by reducing the time spent on questioning, searching, and answering with this user-trainable ChatGPT-integrated FAQ bot!
P.S. This solution was also shared in an official AWS Event.
References
- AWS Serverless Application Model https://aws.amazon.com/serverless/aws-sam/
- OpenAI - "Question answering using embeddings-based search" https://github.com/openai/openai-cookbook/blob/main/examples/Question_answering_using_embeddings.ipynb - The entire logic of this bot came from this Python Notebook, except the "user submit further training" functionality.
Posted on April 26, 2023
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related
April 26, 2023