A tale of invocation - Using AWS Lambda to transfer files from AWS S3 to Azure Blob Storage

Adrian Mudzwiti
Posted on March 25, 2023

A few days ago I decided to scan a popular freelance site for an interesting problem to solve without the intention of applying for the job, as lady luck would have it I stumbled across an interesting challenge, the client needed to copy data from an S3 bucket to Azure Blob Storage using Power Automate. Seems like a fairly easy task right ?
I started off with reading the Microsoft Docs and reviewing the Amazon S3 Power Platform Connector.
There is a caveat when it comes to using the connector as Microsoft explicitly expresses a known limit of object sizes needing to being less than 3.5 MB, as to be expected with low-code development platforms, there’s always a catch.
This seemed like a perfect opportunity to build a Lambda function with Python.
In this post I will show you how to create a Lambda function that is invoked once a file has been uploaded to S3 and using Lambda layers to package libraries that will be used by the Lambda function.
Pre-requisites:
• AWS Account
• Amazon S3 Bucket
• Azure Subscription
• Azure Storage Account
• Docker
This post assumes that you have already created an S3 bucket in AWS and an Azure Storage account with a container. If you’re familiar with Pulumi, I have included Pulumi programs to create the required resources in both clouds in the below repo:
Step 1: Create an IAM execution role
The Lambda function that we will create in the next step will require permissions to access S3 and write permissions to CloudWatch logs.
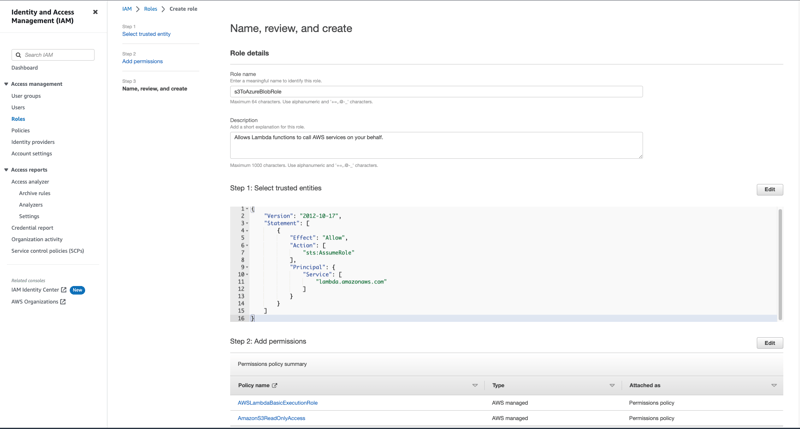
Navigate towards the IAM console and select Roles under Access management from the left side-menu, select the Create role button, from the subsequent page that loads select AWS service as the Trusted entity type and Lambda as the Use case. On the Add permissions page you’ll need to search and select the checkbox for the below permissions:
AmazonS3ReadOnlyAccess
AWSLambdaBasicExecutionRole
Provide a name for the role e.g s3ToAzureBlobRole and finalize the creation of the role.
Step 2: Create a Lambda function
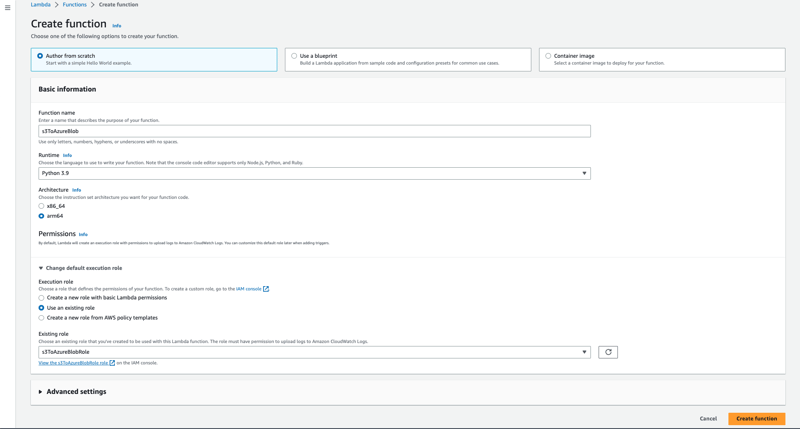
Navigate towards the Lambda console and select the Create function button.
Select Author from scratch and under the Basic information section provide a name of the function eg. s3ToAzureBlob and select Python 3.9 under the Runtime drop-down.
Under the Architecture section, if you’re using Apple Silicon like me, make sure to select arm64 otherwise if you’re using an intel based machine, select x86_64.
We’ll need to expand the Permissions and make sure Use an existing role is selected, from the drop-down select the role you created earlier (s3ToAzureBlobRole). Select the Create function button.
Under the code tab, you’ll need to replace the code shown in the console editor with the code shown below:
import boto3
import botocore
import os
import tempfile
from azure.storage.blob import BlobServiceClient, BlobClient, ContainerClient
from azure.core.exceptions import ClientAuthenticationError, ServiceRequestError
s3 = boto3.resource('s3')
# Credentials for accessing Azure Blob Storage
storage_account_key = os.environ.get('storage_account_key')
storage_account_name = os.environ.get('storage_account_name')
connection_string = os.environ.get('connection_string')
container_name = os.environ.get('container_name')
def lambda_handler(event, context):
# Get temp file location when running
temFilePath = tempfile.gettempdir()
# Change directory to /tmp folder
os.chdir(temFilePath)
for record in event['Records']:
# Get bucket and key from s3 trigger event
bucket = record['s3']['bucket']['name']
key = record['s3']['object']['key']
# Get file name from key, join /tmp folder path and file name
file_name = key
upload_file_path = os.path.join(temFilePath, file_name)
try:
# Download the object from s3
s3.meta.client.download_file(bucket, key, key)
def upload_to_blob_storage(file_path, file_name):
"""Upload file to Azure storage as blob from /tmp folder"""
blob_service_client = BlobServiceClient.from_connection_string(connection_string)
blob_client = blob_service_client.get_blob_client(container=container_name, blob=file_name)
with open(file_path, "rb") as data:
blob_client.upload_blob(data, overwrite=True)
print(f" {file_name} uploaded to Azure Blob !")
upload_to_blob_storage(upload_file_path, file_name)
except FileNotFoundError:
print(f"The file {key} does not exist")
except botocore.exceptions.ClientError as error:
print(error.response['Error']['Code'], error.response['Error']['Message'])
except ClientAuthenticationError as e:
print(f"Error uploading file: {e}")
except ServiceRequestError as e:
print(f"Error uploading file: {e}")
Save the changes and select the Deploy button.
Step 3: Create an S3 trigger
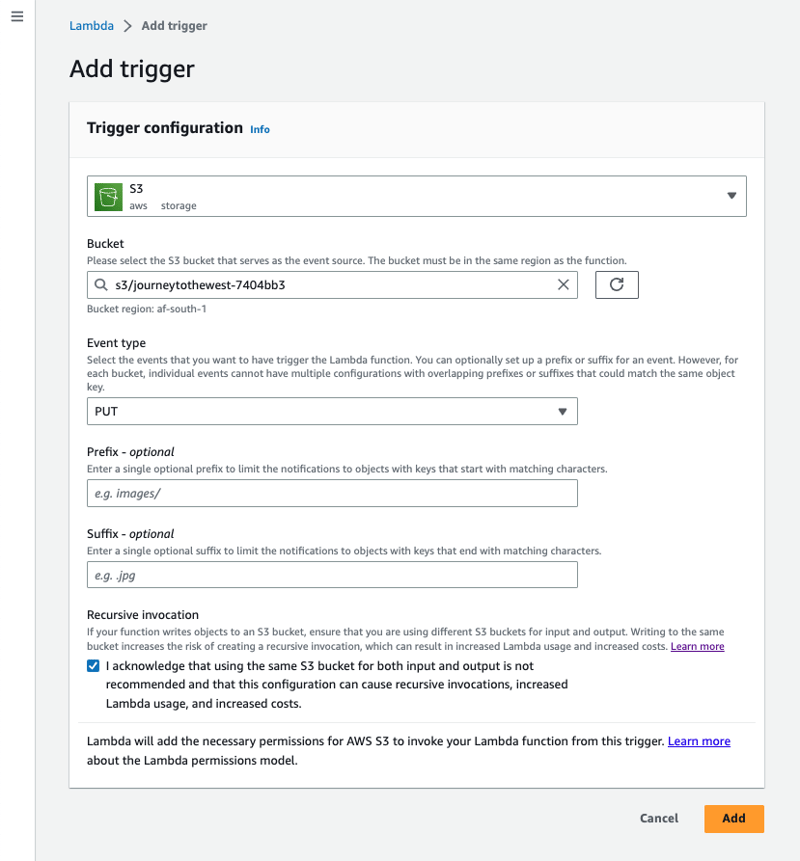
A trigger is a service or resource that invokes your function. We will be using S3 as a source that invokes our function each time an object is uploaded to the S3 bucket.
Under the Trigger configuration, select S3 as the source and select the bucket, under Event type select Put, ensure the checkbox under Recursive invocation is selected and select the Add button to complete the trigger configuration.
Step 4: Create a Lambda Layer
Lambda layers allow you to package additional libraries that will be used by your function. Our function will make use of Azure libraries (azure-storage-blob, azure-core) to communicate with Azure services from the Python code.
You’ll need to create the following directory structure locally that is compatible with Python 3.9 to create a simulated Lambda environment with Docker.
├── requirements.txt
└── python/
└── lib/
├── python3.9/
│ └── site-packages/
In the requirements.txt file, specify the Azure Storage Blobs client library as well as the Azure Core shared client library for Python by adding the following lines in the file.
azure-storage-blob
azure-core
Ensure that the Docker daemon is running. You’ll need to install the library dependencies required by the Lambda function to the subfolders created earlier. Enter the below command:
docker run -v "$PWD":/var/task "public.ecr.aws/sam/build-python3.9" /bin/sh -c "pip install -r requirements.txt -t python/lib/python3.9/site-packages/; exit"
Once the dependencies have been downloaded you’ll need to zip the contents of the python folder.
zip -r azurelib.zip python > /dev/null
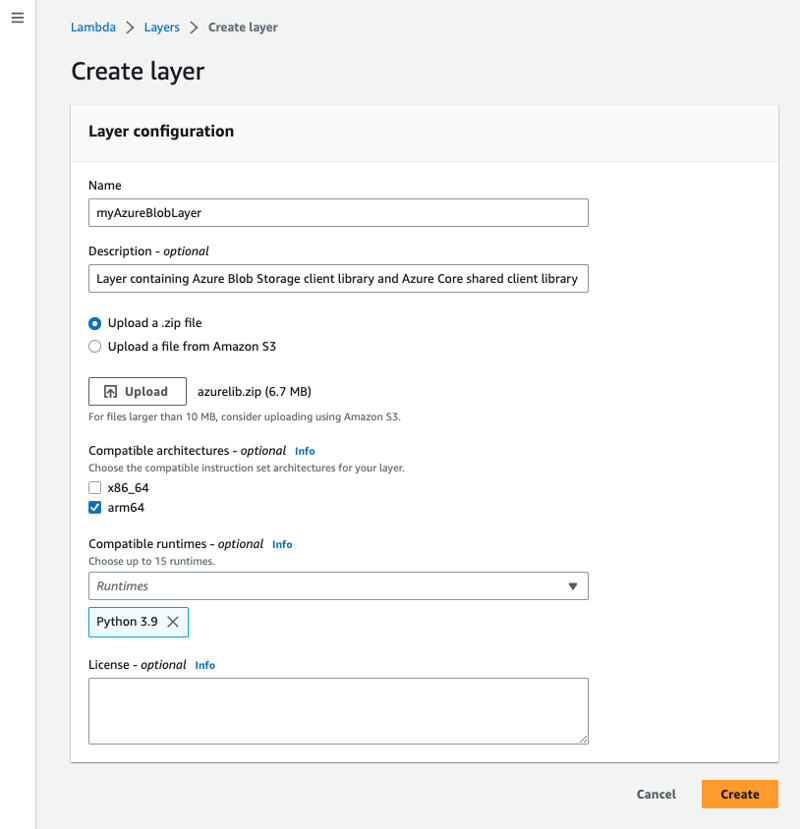
Navigate towards the Lambda console from your browser and expand the side menu by selecting the hamburger menu on the top left corner of the page. Select Layers under Additional resources. Select the Create layer button, you’ll need to provide a name for the layer, upload the zipped file contain the library our function requires to interact with Azure and select Create once you’ve provided the mandatory information.
Navigate towards the function you created earlier, scroll towards the bottom of the page and select Add a layer under the Layers section. Select Custom layers, select the layer you created earlier and select the version.
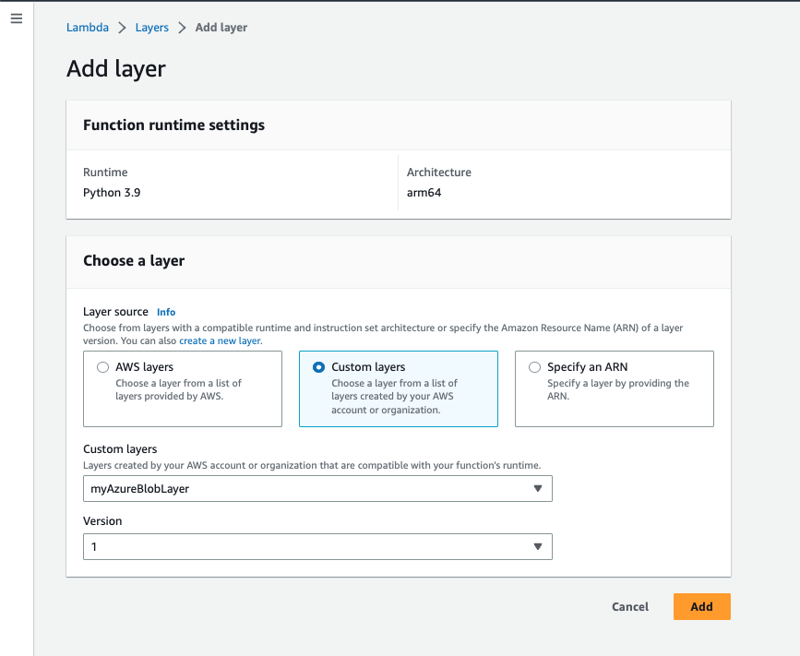
Step 5: Adding environment variables
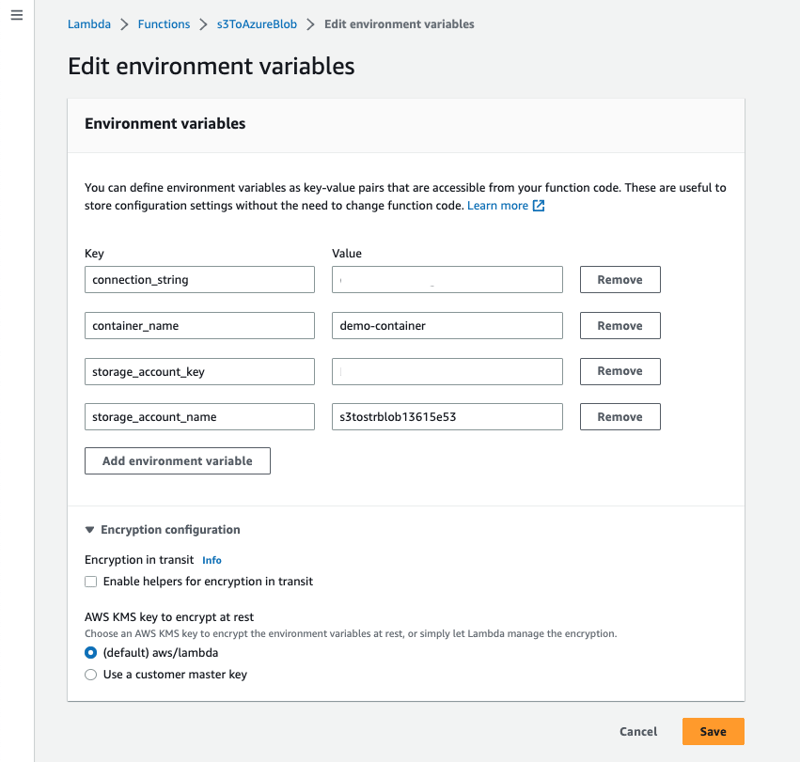
Select the Configuration tab, select Environment variables, select the edit button then select Add environment variable, you’ll need to populate the Key/Value pairs with credentials required for accessing Azure Blob Storage.
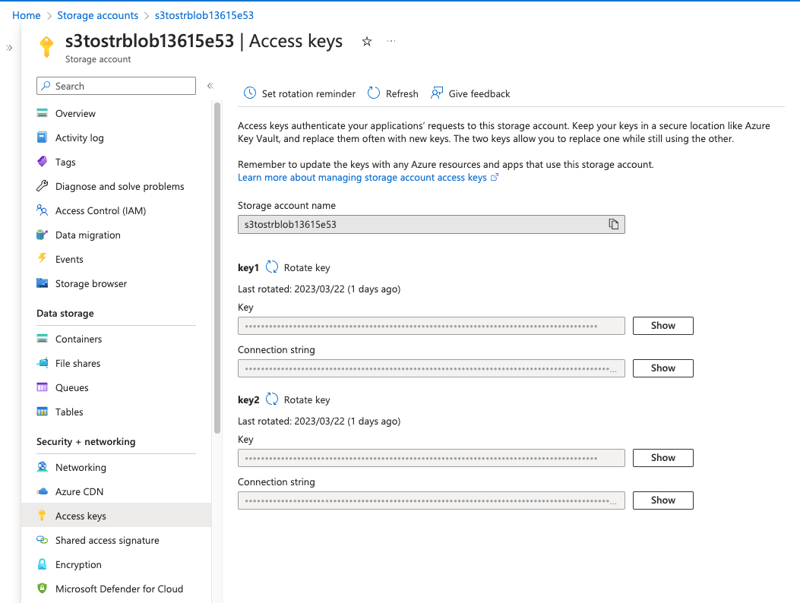
Login to the Azure portal to retrieve the Access keys for the Storage account.
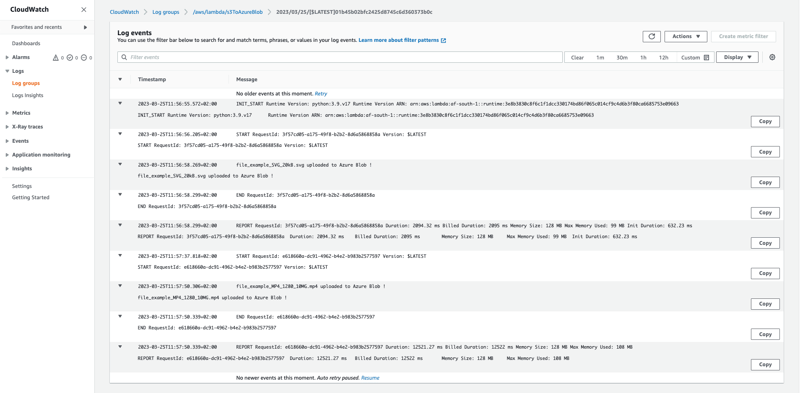
To test if the solution works, you can upload a file to the S3 bucket, you can then review the CloudWatch logs for all log events.
You can also check if the container within your Azure Storage Account has an uploaded file.
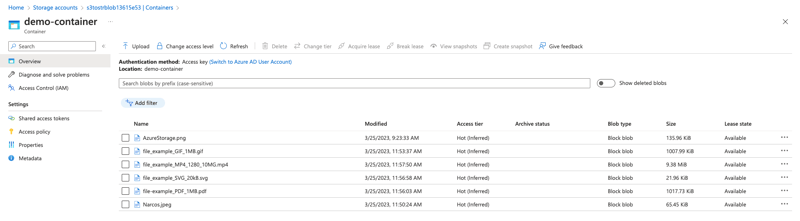
Optional
You might want to increase the Timeout to 15 seconds to negate the function timing out, you can also increase the Ephemeral storage from 512 MB to a higher capacity, up to 10 GB.
Conclusion
The best source for new project ideas can be found looking at freelance sites. This approach leads to a more organic approach to learning.
Thanks for reading, I hope you’ve learnt something new.
Posted on March 25, 2023
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.