Cron monitoring for better sleep

Pavel Kutáč
Posted on October 19, 2021

Regular execution of jobs with Cron is common in almost every system. However, discovering the job stops being executed might be difficult and can take some time. So it is important to monitor it.
🇨🇿 V češtině si lze článek přečíst na kutac.cz
Bugs, which are happening just before the eyes of the user, someone will report eventually. But when background tasks are stopped, no one might notice it for even months. So monitoring is essential. And it might not be even so expensive or hard.
Everyone probably heard some story of non-working DB backups. Which was discovered only, when the backup was really needed. And one simple monitoring would save it.
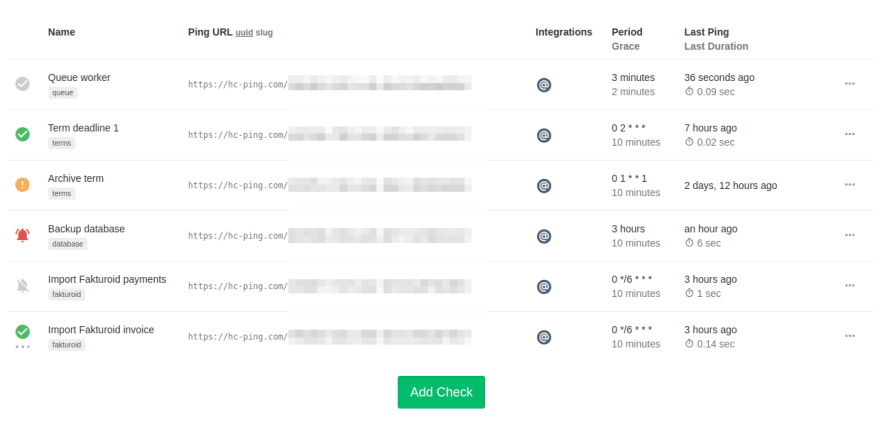
Healthchecks.io - Dead's man switch
In the previous article, I wrote about Cron-job service which might be good to trigger cron tasks. However, what happens, when the response code is 200 but nothing is executed? This is really hard to discover. So services like Healthchecks.io are here to help. And with a quite generous free tier.
Service is working on Dead's man switch principle. It is required to notify the service in set intervals, otherwise notifications are being sent. For example to email, SMS, phone call, Slack, Discord, Teams, Trello, WhatsApp, or one of another 16 services.
There are 2 check types. One is called Simple which accepts the interval in which the system is expecting pings. The second one is Cron, which supports basic Cron syntax to define times when to run. Both support also Grace time which defines the maximum possible delay.
Success Ping, Start, Fail, and Exit code
Only success Ping is required as a minimal starting point. By sending Ping you are telling that now the task was processed. If the service does not receive a ping at a given time or interval, notifications are sent. Endpoint Start is notifying that the task just started. Now the service is expecting Ping in defined limit since Start. This is good for detecting endless loops or stuck code.
Endpoints Fail and Exit code is there to notify about failure. With Exit code, you can specify the numeric exit code of the job.
It is possible to attach a log message with a size up to 10 kB to the requests. For more info see the documentation.
HTTP requests and retry
As documentation states, HTTP pings are not really reliable.
Sending monitoring signals over the public internet is inherently unreliable. HTTP requests can sometimes take excessively long or fail completely for a variety of reasons.
It is required to set reasonable timeouts and a retry policy. Here is a simplified helper class for the Laravel framework below. It would be better to use the Retry plugin, but simple for might be enough here.
<?php
namespace App\Services;
use GuzzleHttp\Client;
use Illuminate\Support\Facades\Config;
use Illuminate\Support\Facades\Log;
class HealthChecksService
{
private $client;
public function __construct()
{
$this->client = new Client([ 'base_uri' => Config::get('healthchecks.api_endpoint') ]);
}
private function makeRequest(string $action, string $checkName, string $log = ""): void
{
$options = [
'timeout' => 2,
'connect_timeout' => 2,
'body' => $log,
];
$exception = null;
$i = 0;
for (; $i < 3; $i += 1) {
try {
$this->client->request('POST', \rtrim("/{$action}", '/'), $options);
$exception = null;
break;
} catch (\Throwable $e) {
$exception = $e;
\usleep(\pow(2, $i) * 500000);
}
}
if ($exception) {
Log::warning(
'Cannot perform HealthChecks request',
['checkName' => $checkName, 'action' => $action, 'exception' => $exception, 'retry' => $i + 1],
);
}
}
public function start(string $checkName): void
{
$this->makeRequest('start', $checkName);
}
public function success(string $checkName, string $log = ""): void
{
$this->makeRequest('', $checkName, $log);
}
public function exitStatus(string $checkName, $exitStatus, string $log = ""): void
{
$this->makeRequest("$exitStatus", $checkName, $log);
}
}
Posted on October 19, 2021
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related