Fuzzing Tesseract & Cloud Vision: Generating OCR-proof images

Dan Sporici
Posted on September 11, 2019
In this article, I'm going to discuss about my Bachelor's degree final project, which is about evaluating the robustness of OCR systems (such as Tesseract or Google's Cloud Vision) when adversarial samples are presented as inputs. It's somewhere in-between fuzzing and adversarial samples crafting, on a black box.
It's an old project that I recently presented at an International Security Summer School hosted by the University of Padua. I decided to also publish it here mainly because of the positive feedback received when presented at the summer school.
I'll try to focus on methodology and results, which I consider being of interest, without diving into implementation details.
I published this ~1 year ago - not sure if it still works as described here. Hopefully it does, but I'm pretty sure Google made changes to the Vision engine since then.
Motivation
Let's start with what I considered to be plausible use cases for this project and what problems it would be able to solve.
Confidentiality of text included in images? -- It is no surprise to us that large services (that's you, Google) will scan hosted images for texts in order to improve classification or extract user information. We might want some of that information to remain private.
Smart CAPTCHA? -- This aims to improve the efficiency of CAPTCHAs by creating images which are easier to read by humans, thus reducing the discomfort, while also rendering OCR-based bots ineffective.
Defense against content generators? -- This could serve as a defense mechanism against programs which scan documents and republish content (sometimes using different names) in order to gain undeserved merits.
Challenges
Now, let's focus on the different constraints and challenges:
1. Complex / closed-source architecture
](https://res.cloudinary.com/practicaldev/image/fetch/s--L8cx-VOL--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://codingvision.net/imgs/posts/evaluating-the-robustness-of-ocr-systems/tess-pipeline.png)
Modern OCR systems are more complex than basic convolutional neural networks as they need to perform multiple actions (e.g.: deskewing, layout detection, text rows segmentation), therefore finding ways to correctly compute gradients is a daunting task. Moreover, many of them do not provide access to source code thus making it difficult to use techniques such as FGSM or GANs.
2. Binarization

An OCR system usually applies a binarization procedure (e.g.: Otsu's method) to the image before running it through the main classifier in order to separate the text from the background, the ideal output being pure black text on a clean white background.
This proves troublesome because it restricts the samples generator from altering pixels using small values: as an example, converting a black pixel to a grayish color will be reverted in the binarization process thus generating no feedback.
3. Adaptive classification

This is specific to Tesseract, which is rather deprecated nowadays - still very popular, though. Modern classifiers might be using this method, too. It consists of performing 2 iterations over the same input image. In the first pass, characters which can be recognized with a certain confidence are selected and used as temporary training data. In the second pass, the OCR attempts to classify characters which were not recognized in the first iteration, but using what it previously learned.
Considering this, having an adversarial generator which alters one character at a time might not work as expected since that character might appear later in the image.
4. Lower entropy
This refers to the fact that the input data is rather 'limited' for an OCR system when compared to... let's say object recognition. As an example, images which contain 3D objects have larger variance than those which contain characters since the characters have a rather fixed shape and format. This should make it more difficult to create adversarial samples for character classifiers without applying distortions.
A direct consequence is that it greatly restricts the amount of noise that can be added to an image so that the readability is preserved.

5. Dictionaries
OCR systems will attempt to improve their accuracy by employing dictionaries with predefined words. Altering a single character in a word (i.e.: the incremental approach) might not be effective in this case.
Targeted OCR Systems

For this project, I used Tesseract 4.0 for prototyping and testing, as it had no timing restrictions and allowed me to run a fast, parallel model with high throughput so I could test if the implementation works as expected. Later, I moved to Google's Cloud Vision OCR and tried some 'remote' fuzzing through the API.
Methodology
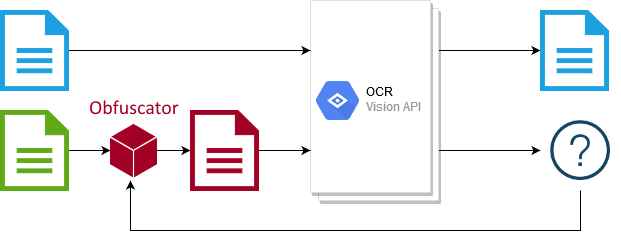
In order to be able to cover even black box cases, I used a genetic algorithm guided by the feedback of the targeted OCR system. We observe that the confidence of the classifier, alone, is not a good metric for this problem, a score function based on the Levenshtein distance and the amount of noise is employed.
One of the main problems here was the size of the search space which was partially solved by identifying regions of interest in the image and focusing only on these. Also, lots of parameter tuning...
Noise properties
Given the constraints, the following properties of the noise model must be matched:
- high contrast -- so it bypasses the binarization process and generates feedback
- low density -- in order to maintain readability by exploiting the natural low-filtering capability of the human vision
Applying salt-and-pepper noise in a smart manner will, hopefully, satisfy the constraints.
Working modes

Initially, the algorithm worked using only overtext mode, which applied noise in the rectangle which contained characters. However, this method is not the best choice for texts written using smaller characters mainly because there are less pixels that can be altered thus drastically lowering the readability even with minimal amounts of noise. For this special case, the decision to insert the noise in-between the text rows (artifacts) was taken in order to preserve the original characters. Both methods presented similar success rates in hiding texts from the targeted OCR system.
Just for fun, here's what happens if the score function is inverted, which translates as "generate an image with as much noise as possible, but which can be read by OCR software". Weird, but it's still recognized...

Results on Tesseract
Promising results were achieved while testing against Tesseract 4.0. In the following figure is presented an early (non-final) sample in which the word "Random" is not recognized by Tesseract:

Tests on Google's Cloud Vision Platform
This is where things get interesting.
The implemented score function can be maximized in 2 ways: hiding characters or tricking the OCR engine into adding characters which shouldn't be there.
One of the samples managed to create a loop in the recognition process of Google's Cloud Vision OCR, basically recognizing the same text multiple times. No DoS or anything (or I'm not aware of it), I'm still not sure if the loop persisted or not - it either produced a small number of iterations, failed (timed out?) or they had load balancers which compensated for this and used different instances.
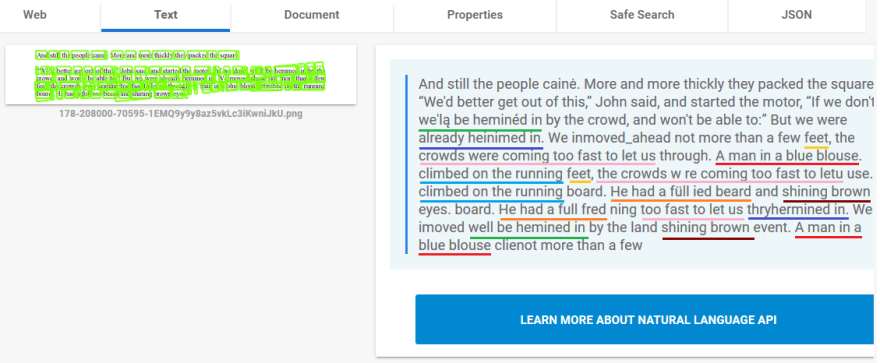
Let's take a closer look at the sample: below, you can see how the adversarial sample was interpreted by Google's Cloud Vision OCR system. The image was submitted directly to the Cloud Vision platform via the "Try the API" option so, at the moment of testing, the results could be easily reproduced.

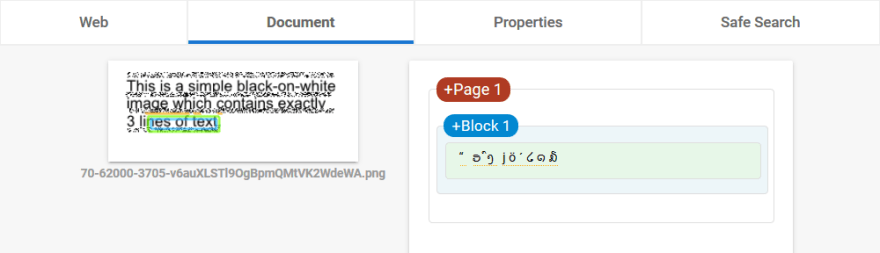
Also the 'boring' case where the characters are hidden:
Conclusions
It works, but the project reached its objective and is no longer in development.
It seems difficult to create samples that work for all OCR systems (generalization).
Also, the samples are vulnerable to changes at the preprocessing stage in the OCR pipeline such as:
- noise filtering (e.g.: median filters)
- compression techniques (e.g.: Fourier compression)
- downscaling->upscaling (e.g.: Autoencoders)
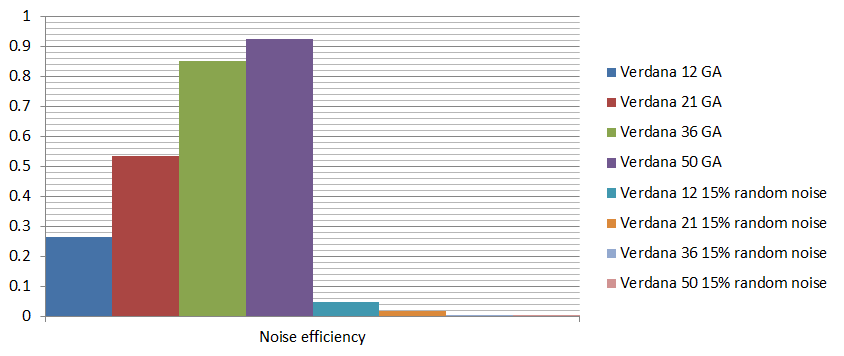
However, we can conclude that, using this approach, it is more challenging to mask small characters without making the text difficult to read. I compiled the following graph, in which are compared: the images generated by the algorithm (below 7% noise density) and a set of images that contain random noise (15% noise density). The 2 sets contain different images with characters of sizes: 12, 21, 36, 50. Each random noise set contains 62 samples for each size - average values were used.
Noise efficiency is computed by taking into account the Levenshtein distance and the total amount of noise in the image.
Interesting TODO's
- Extracting templates from samples and training a generator?
- Exploiting directly the row segmentation feature?
- Attacking Otsu's binarization method?
Maybe someday...
Posted on September 11, 2019
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.