Regex is not your enemy

Alois Sečkár
Posted on December 31, 2023

One of the common subjects of IT jokes are regular expressions as "magic" that nobody can understand. I agree that many developers don't love these "weird clusters of characters" and avoid them if they can. However, it's a pity because they are very useful.
My use case today is purely practical - I'm creating a new version of my website and I have slightly modified the data model. I now need to migrate dozens of historical records from the old version.
The data (news on the website) is available in the form of an SQL export, where the records look like this:
INSERT INTO "main"."web_news" ("date_created", "content", "author_id", "news_id") VALUES ('2012-11-29', 'Site moved to a new web hosting by WEDOS Internet', '1', '1');
The new website table has an additional column date_edited, so this value needs to be added, and the news_id column, which is a primary key with an auto-generated value, cannot be manually inserted in PostgreSQL, so this value needs to be omitted.
Certainly, it would be possible to go through it and make the necessary modifications manually. It's still manageable for "dozens" of records. If a person doesn't know how to automate it quickly, direct manipulation is probably the fastest way. It's really not good to spend an hour automating something that can be straightforwardly done in a few minutes. But it's even better to know how to make your life easier.
Another option is to call the source database with modified SQL and extract the data in a better format. The problem of the missing column can be solved, for example, like this: SELECT date_created, date_created AS date_edited FROM web_news{lang="sql"} - simply select the data twice, once with a different alias. But let's say we don't have access to the database and we only have a ready-made SQL dump.
So, the only option left is to use regular expressions. You need a text editor that can "Find" and "Replace" using them - my choice is Notepad++ (for Windows people like me - shortcut Ctrl+H).
A simpler modification is to delete news_id at the end of each INSERT. Regular expressions work by using a combination of actual characters and special metacharacters to find matches in the source text. The key is to construct the combination correctly. Let's do it.
Removing a column
The search term will be: , '\d+'\)
The beginning of the string is simple - comma, space, apostrophe - these are not special characters, they will match exactly what is written in the text. Theoretically, we could replace the space with the regular expression \s (metacharacter for "white space"), but that makes more sense when you're not sure in advance whether there will be a space or maybe a tab. Next is the metacharacter \d - it tells to search for a digit, i.e. characters from the range 0-9. If we wanted, we could also use the notation [0-9] (in square brackets you can enclose a group or a range of possible characters), but \d is shorter and more convenient. The metacharacter + says that the previous (digit) should be found at least once, but possibly multiple times ("1-n times"). This solves the issue of finding two or more digit values for news_id. Regex is "greedy" by nature, so it will match everything it can until the next character in the expression, which is the closing apostrophe. Finally, to make sure we are taking the number that is at the end and not the previous one (author_id), we need to match the closing parenthesis. However, parentheses are metacharacters (we will see their meaning shortly in the second transformation), so we need to use a backslash to "escape" it.
Those who don't believe it should first try it in the search mode (Ctrl+F). By the way, it's never a bad idea. First, test what the entered regular expression actually finds before applying it directly to the entire source text.
Let's replace it with: \)
This is easy - we simply replace the piece of text we found, which contains news_id, with the closing parenthesis character (again, forcibly escaped with a backslash).
Then all we need to do is confirm the "Replace" command, and within a moment, what would otherwise take several minutes to do manually is done.
The result is:
... VALUES ('2012-11-29', 'Site moved to a new web hosting by WEDOS Internet', '1');
Adding a column
Now let's move on to the second modification - adding a new column date_edited.
It makes logical sense for the default state to have the edit date the same as the original creation date. If someone modifies the record over time, then of course the edit date will change, but that is highly unlikely to happen. So how do we take the value of date_created and copy it?
The functionality of round brackets in regular expressions can help with something that can be likened to creating variables. The matched piece of actual text, which is wrapped in round brackets, is saved aside and can be used in the subsequent replacement step, where it is referenced using a backslash and a number corresponding to the order of the bracket pair (there can be multiple pairs in one expression). This is the real power of regular expressions because it allows you not only to duplicate data, as we will do shortly, but also to move it around in different ways, which I have already used many times instead of the tedious and error-prone manual Ctrl+X and Ctrl+V.
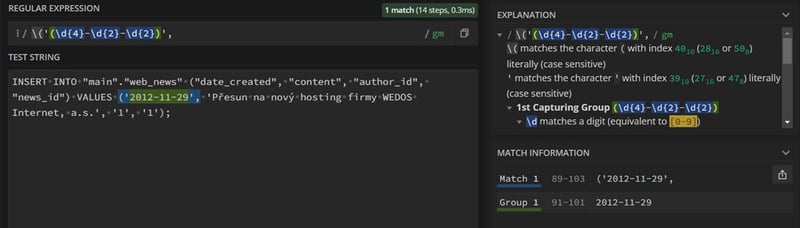
The search expression will be: \('(\d{4}-\d{2}-\d{2})',
This is already a proper "monster," but let's break it down to make it less intimidating. At the beginning, we have an escaped opening round bracket - this is to target correctly within the line. It is followed by an apostrophe, which opens the value. After that, there is a round bracket, but notice that this time it is without a backslash. This means that it functions as a metacharacter and opens a sequence that the regex parser records. Then comes the familiar \d character and the yet-to-be-introduced construction {4} - curly brackets indicate a specific number of repetitions. Here, the only value is 4, meaning we want the number "exactly 4 times in a row" (= year). It is also possible to write {m,n}, which then means a range of "m to n times". Fortunately, we don't need that; our date has a fixed format. A hyphen follows, which is not a metacharacter, so it is a literal value. The next parts of the expression match the months and days in the date. When we have the whole part, we can close the round bracket. We could possibly end here, but just to be sure, we add a closing apostrophe and a comma to avoid the (unlikely but possible) situation where the date is randomly mentioned somewhere in the content data, which is free text and cannot be assumed with certainty. Generally, I recommend considering your source data when constructing regular expressions and trying to minimize the possibility of "false positives" because they can mess things up and nullify the positive effect of regex transformation.
Let's replace with: \('\1', '\1',
Here is the key sequence \1 - it refers to the matched expression in the format YYYY-MM-DD, which was created by the regex for searching. By repeating it twice, we ensure that it is inserted correctly into the SQL structure (the parentheses need to be escaped to be inserted literally, otherwise the parser would ignore them).
Without further ado, we have what we needed:
... VALUES ('2012-11-29', '2012-11-29', 'Site moved to a new web hosting by WEDOS Internet', '1');
The more records need to be dealt with, the more advantageous it is to spend some time constructing a regular expression that will handle repetitive work for you. And indeed, it can save hours of work.
I participate as a scorer in international baseball and softball tournaments. Until recently, we had to enter the lineups of individual teams into an older version of the system for online recording before each tournament. The program stored the data in text files, so it was not necessary to use its interface and rewrite everything manually. The source data about the players was available in electronic form (machine-readable PDF), but the order of values did not match what the program needed. However, thanks to regular expressions, this was not a big deal. It was enough to decide once that I would not manually enter the data until two a.m., and I managed to reduce the necessary time from hours to tens of minutes.
You may argue that nowadays, you can just ask ChatGPT or another artificial intelligence tool to figure out the correct regex construction for you. However, when working with generative AI, two rules apply - you need to have an idea of what is possible in order to write a prompt, and you should also have some understanding of the problem yourself to be able to verify the output and confirm that it is not a result of "hallucinations".
If I have convinced you that it is worth trying regular expressions, here is some material for further self-study. I introduce you the ultimate website https://regex101.com/, where you can write expressions interactively and it automatically verifies if they work and provides a detailed breakdown of what was actually entered. In practice, an invaluable tool that you can always come back to.
Happy regular-expressing!
👀 If you want more, check another practical examples in my Applying regular expressions article. 👀
Posted on December 31, 2023
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related
