Implement a kafka like consumer strategy to process records in your database

Alejandro Bezdjian
Posted on November 13, 2020
Let's say you have a table in your database which contains data about some files that you would like to process in batch jobs (this is just an example, it can be anything other than files). You have some job that runs every X minutes and does something like:
SELECT * FROM files
WHERE processed = false
LIMIT 100;
Then, it process each row and updates it by flipping the processed. This simple implementation should work just fine if the worker can process the incoming data as fast as it is generated, but it will start lagging if not (or if you want to re-process all the rows in a reasonable time).
The natural thing to do in that case would be to add more workers to parallelize the process. The problem is that the query we are making can lead to problems, for example, since there is no mechanism to stop 2 workers from getting the same rows, some rows can get processed more than once.
I want to show you one way to solve this problem borrowing an idea from Kafka. In kafka you can scale a topic by adding more partitions to it, this will allow you to increase the number of consumers and your throughput. You can read more about kafka consumers here.
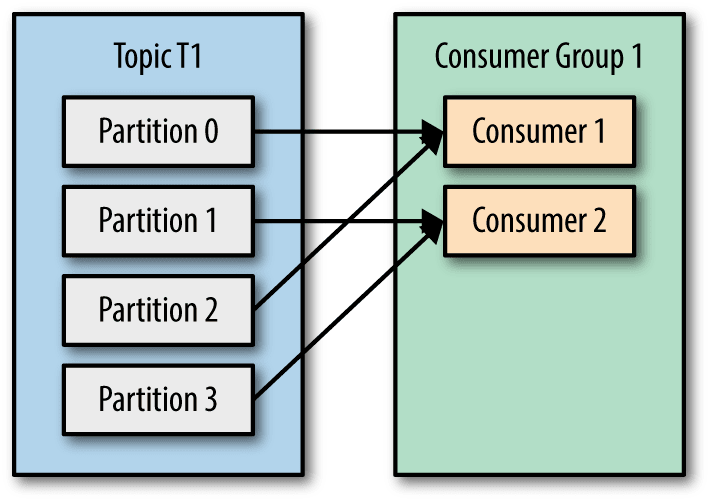
Kafka guarantees that the messages written into a topic will be stored in only one partition and will be consumed by only one consumer in a consumer group, and that's exactly what we want in our case here.
In order to achieve this we can use a few useful SQL functions. First we are going to need a unique hash_code for each of our rows:
ALTER TABLE files ADD COLUMN hash_code BIGINT;
The "partition" will be calculated from to this number, so make sure to use a good hashing function.
Every worker instance will act as a "consumer" in kafka, so they need a unique number to avoid processing the same rows, and just like kafka, we won't be able to have more "consumers" than "partitions". How to assign that number depends on your application and is out of the scope of this post.
The other important number that we need is the total amount of workers. Once we have those, let's change our query to get the results we want:
SELECT * FROM files
WHERE processed = false AND MOD(hash_code, :instances) = :instanceId
LIMIT 100;
The main idea behind this query is to use the modulo operation to find the "partition", so MOD(hash_code, :instances) will return that number (starting from 0).
Now, there is a problem with this query. Since we just added the hash_code column, there might be a lot of null values. To solve this issue, we can use the coalesce function to turn each null value into a number. The final query should look like this:
SELECT * FROM files
WHERE processed = false AND MOD(COALESCE(hash_code, 0), :instances) = :instanceId
LIMIT 100;
By doing this, you avoid the need to do a massive update in that table before being able to process the data, in this example all the null values will be processed only by the worker with ID 0.
And that's it!
Of course this method isn't perfect, you could have idle workers if the distribution of your data is not perfect.
What I like about this approach is that is easy to understand, and the required code is simple and elegant. Other solutions may involve the use of locks which are harder to get right in my opinion.
I hope you enjoyed this as much as I did! If you try it in your application let me know!
![]()
Posted on November 13, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related
November 13, 2020