Jordan Is Speed (speeding up scraping with multiple threads)

Jordan Hansen
Posted on August 1, 2019
Story so far
This is a follow up on my post about dead link checking. I still do like this piece of code but speed was a big issue. I was checking a site with over 100,000 links (a big part of which were comments on blog posts) and it took days. “Days” is just too much for any piece of code like this to be running.
I still am not sure what kind of heuristic I could use to handle comments.
A link like https://laurenslatest.com/fail-proof-pizza-dough-and-cheesy-garlic-bread-sticks-just-like-in-restaurants/#comment-26820 isn’t really a new link. How do I differentiate that from a url like domain.com/#/posts? I’m still thinking about this and hope to find a way to handle it better.
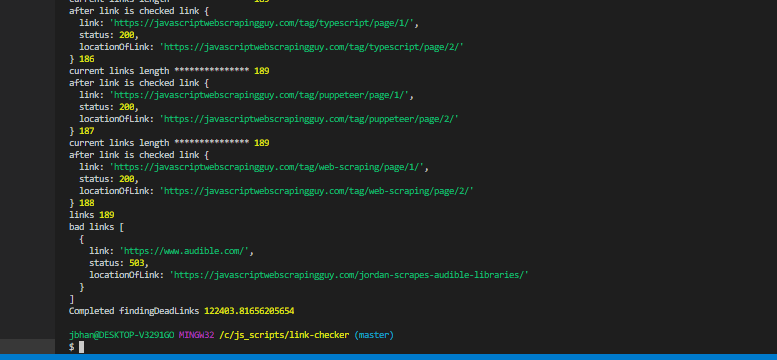
Below is an example of the speed of checking the links on this website that had only about 189 links to check. It took ~122 seconds which doesn’t feel too terrible for one site. The speed improvement you’ll see is really impressive, though.
Using Web Workers

As I mentioned in the previous post, I was considering taking advantage of the asynchronous nature of javascript and try to do the work in chunks concurrently. To do this, I needed to take advantage of web workers to spin off additional threads.
Javascript is single threaded but also asynchronous. There is a really good explanation of how this all works here. I found a really great library, threads.js by good guy Andy. I had some questions while implementing it and he was incredibly helpful.
Refactoring
I had to do a fair bit of refactoring. Previously, I was passing in the whole array of links into my function that would get new links. I did this so I could confirm I wasn’t adding duplicate links. The downfall of this is I’m kind of cascading that huge links array from function to function until it is actually used.
Another downfall, and the real reason why I refactored, is that if link checking is done in the function that is going to be in a separate thread then it’s extremely likely it’s going to duplicate a ton of links while they are separate.
for (let i = 0; i < links.length; i++) {
if (!links[i].status) {
const promises: any[] = [];
const amountOfThreads = 20;
for (let linkToCheckIndex = 0; linkToCheckIndex < amountOfThreads; linkToCheckIndex++) {
if (links[i + linkToCheckIndex]) {
promises.push(checkLink(links[i + linkToCheckIndex], domain));
}
}
const checkLinkResponses = await Promise.all(promises);
for (let index = 0; index < checkLinkResponses.length; index++) {
// Replace the link that doesn't have a status with the link that does
let linkToReplaceIndex = links.findIndex(linkObject => linkObject.link === checkLinkResponses[index].link.link);
links[linkToReplaceIndex] = checkLinkResponses[index].link;
// This part needs to check for duplicate links
// So we can't do it concurrently just in case we miss duplicates
for (let linkToCheck of checkLinkResponses[index].links) {
if (links.filter(linkObject => linkObject.link === linkToCheck.link).length < 1) {
console.log('pushed in ', linkToCheck.link);
links.push(linkToCheck);
}
}
}
i += amountOfThreads - 1;
// console.log('after link is checked link', links[i], i);
console.log('current links length and current index ***************', links.length, i);
}
}
The chunk of code now looks like the above. I have to do quite a bit of looping to match things up where they belong and that is pretty expensive but now at least I can speed up a lot of the request stuff. It should be noted that this does increase the load on the site under test. It really didn’t seem to be significant, though. I tried with 20 threads on https://javascriptwebscrapingguy.com and didn’t notice anything while navigating around.
I had to take advantage of Promise.all which actually worked really well. I wanted the requesting part to run concurrently but I needed the part following (where I match up the results) to be blocked. So I ended up doing something like this:
const promises: any[] = [];
const amountOfThreads = 20;
for (let linkToCheckIndex = 0; linkToCheckIndex < amountOfThreads; linkToCheckIndex++) {
if (links[i + linkToCheckIndex]) {
promises.push(checkLink(links[i + linkToCheckIndex], domain));
}
}
const checkLinkResponses = await Promise.all(promises);
Doing this will spin up as many threads as I like, push them into an array of promises and then I just block with my const checkLinkResponses = await Promise.all(promises);. Later down the line the in code you can see I increment my index by the appropriate amount with i += amountOfThreads - 1;.
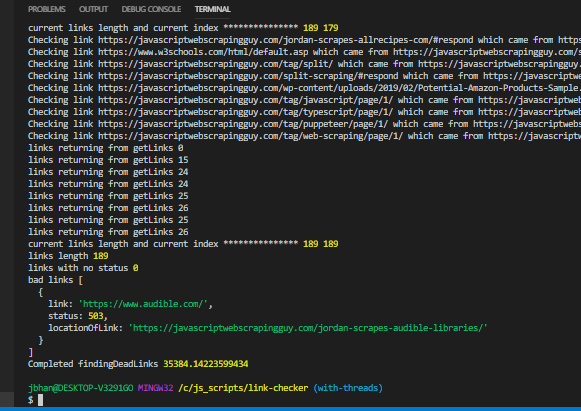
It was pretty dang tricky getting all this to work and getting it to work well. I finally was able to get it working and returning the same results as the previous working code among numerous different thread counts. You can see the results pasted below. There is a serious time difference (20 threads brought it down to 28 seconds! ) in the script and I’m really proud of that.
Any time I go over 10 threads I think javascript has a built in warning for a possible memory leak. (node:17960) MaxListenersExceededWarning: Possible EventEmitter memory leak detected. 11 message listeners added to [Worker]. Use emitter.setMaxListeners() to increase limit is the warning I get. I would like to dig into this more at some point. It certainly doesn’t break my script and scaling up past 10 still gives me faster results so it doesn’t seem to be preventing the additional threads even though the error kind of suggests that.
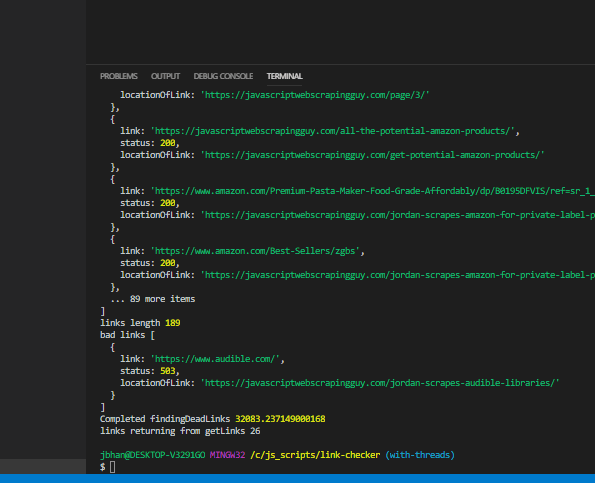
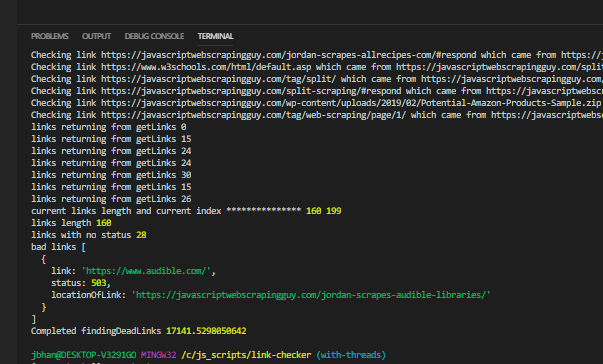
The one notable experiment is when I bumped it up to 50 threads, I ended up with a bunch of links with a null status, meaning the check either didn’t get done on those links or, more likely, we didn’t wait for them to come back properly before we ended the script. Something worth digging into at some point in the future.
So there it is! Concurrent javascript using web workers (and an awesome package!) to spin off threads.


The post Jordan Is Speed (speeding up scraping with multiple threads) appeared first on JavaScript Web Scraping Guy.
Posted on August 1, 2019
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.