SDB :Pure golang development, distributed, rich data structure, persistent, easy-to-use NoSQL database

yemingfeng
Posted on May 12, 2022
SDB :Pure golang development, distributed, rich data structure, persistent, easy-to-use NoSQL database
Why do you need SDB?
Consider the following business scenario:
- Counting Service: Count the likes, plays and other data of the content
- Commenting Service: After posting a comment, view a list of comments for a piece of content
- Recommendation Service: each user has a recommendation list with content and weight
The above business scenarios can all be implemented through MySQL + Redis.
MySQL acts as a persistent capability in this scenario, and Redis provides read and write
capabilities for online services.
The above storage requirements are: persistence + high performance + rich data structure. Can only
one storage be used to satisfy the above scenario?
The answer is: very little. Some databases either support insufficient data structure, or data
structure is not rich enough, or the access cost is too high......
In order to solve the above problems, SDB was created.
A brief introduction to SDB
- Pure golang development, the core code does not exceed 1k, the code is easy to read
- Rich data structure
- Persistence - using pebble 、leveldb 、badger storage engine
- Monitor
- Support prometheus + grafana monitoring solution
- cli
- Easy to use cli
- distributed
- Implemented master-slave architecture based on raft
Architecture
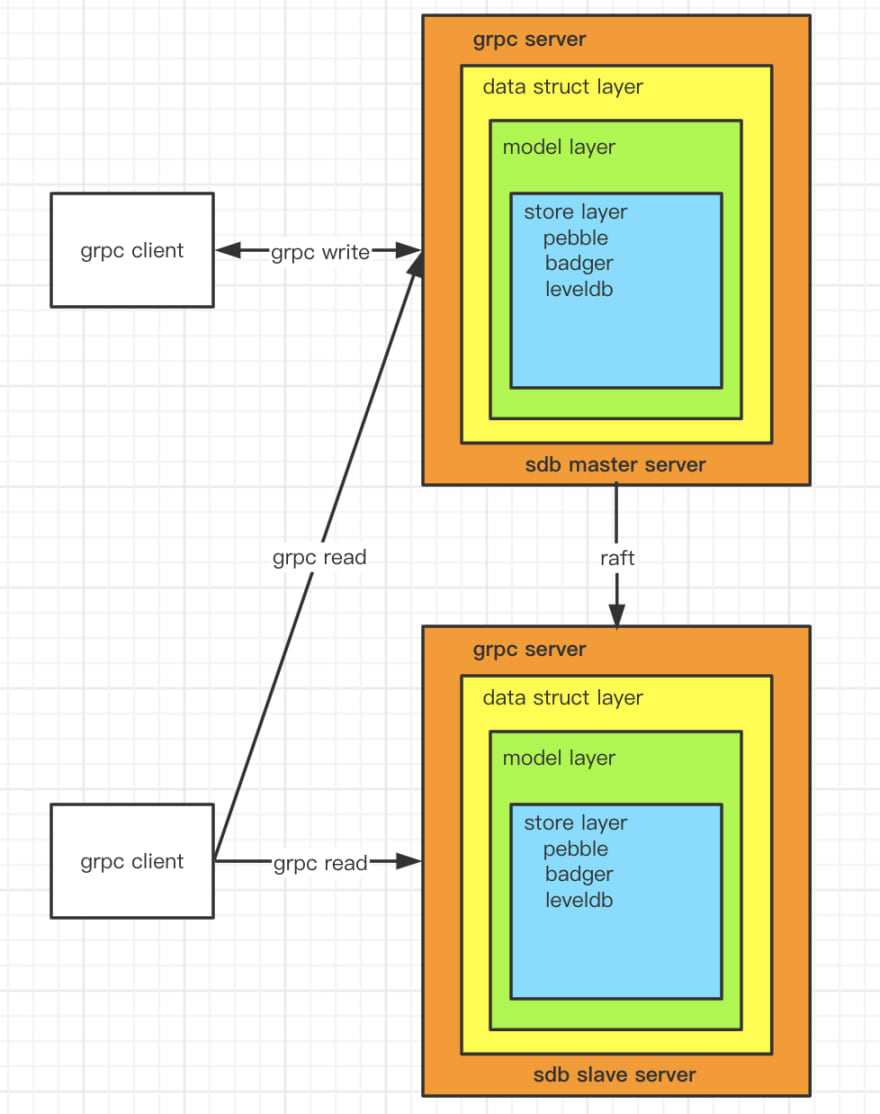
- Implemented a master-slave architecture based on the raft protocol.
- When a write request is initiated, any node can be connected. If the node is the master node, the request will be processed directly, otherwise the request will be forwarded to the master node.
- When initiating a read request, you can connect to any node, and the node will process the request directly.
Quick to use
Compile protobuf
Due to the use of protobuf, the project does not upload the go files generated by protobuf to
github. Need to manually trigger compilation of protobuf files
sh ./scripts/build_protobuf.sh
Start the master server
sh ./scripts/start_sdb.sh
Start the slave server1
sh ./scripts/start_slave1.sh
Start the slave server2
sh ./scripts/start_slave2.sh
Use pebble storage engine by default.
Use cli
Client use
package main
import (
"github.com/yemingfeng/sdb/internal/util"
pb "github.com/yemingfeng/sdb/pkg/protobuf"
"golang.org/x/net/context"
"google.golang.org/grpc"
)
var clientLogger = util.GetLogger("client")
func main() {
conn, err := grpc.Dial(":10000", grpc.WithInsecure())
if err != nil {
clientLogger.Printf("faild to connect: %+v", err)
}
defer func() {
_ = conn.Close()
}()
c := pb.NewSDBClient(conn)
setResponse, err := c.Set(context.Background(),
&pb.SetRequest{Key: []byte("hello"), Value: []byte("world")})
clientLogger.Printf("setResponse: %+v, err: %+v", setResponse, err)
getResponse, err := c.Get(context.Background(),
&pb.GetRequest{Key: []byte("hello")})
clientLogger.Printf("getResponse: %+v, err: %+v", getResponse, err)
}
Performance Testing
Test script: benchmark
Testing Machine: MacBook Pro (13-inch, 2016, Four Thunderbolt 3 Ports)
Testing processor: 2.9GHz Dual-core Core i5
Testing memory: 8GB
Testing result: peek QPS > 10k,avg QPS > 9k,set avg time < 80ms,get avg time <
0.2ms

Plan
- [x] Write interface documentation
- [x] Implement more APIs (2021.12.30)
- [x] String
- [x] SetNX
- [x] GetSet
- [x] MGet
- [x] MSet
- [x] List
- [x] LMembers
- [x] LLPush
- [x] Set
- [x] SMembers
- [x] Sorted Set
- [x] ZMembers
- [x] String
- [x] Support for richer data structures (2021.01.20)
- [x] bitset
- [x] map
- [x] geo hash
- [x] sdb-cli (2021.03.10)
- [x] master-slave architecture
- [ ] Write sdb kv storage engine
Interface documentation
string
| interface | parameter | description |
|---|---|---|
| Set | key, value | set kv |
| MSet | keys, values | set multi kv |
| SetNX | key, value | When key does not exist, set value |
| Get | key | Get the value corresponding to the key |
| MGet | keys | Get the value corresponding to a set of keys |
| Del | key | delete key |
| Incr | key, delta | Add delta to the key, and throw an exception if the value is not a number. If value does not exist, then value = delta |
list
| interface | parameter | description |
|---|---|---|
| LRPush | key, values | append values from the key array |
| LLPush | key, values | append values to the front of the key array |
| LPop | keys, values | remove all values elements from the key array |
| LRange | key, offset, limit | traverse keys in array order, starting at 0. If offset = -1, traverse from back to front |
| LExist | key, values | determine if values exist in the key array |
| LDel | key | delete a key array |
| LCount | key | returns the number of elements in the key array, the time complexity is high, not recommended |
| LMembers | key | traverse keys in array order. high time complexity, not recommended |
set
| interface | parameter | description |
|---|---|---|
| SPush | key, values | add values to the key collection |
| SPop | keys, values | remove all values elements from the key collection |
| SExist | key, values | determine whether values exist in the key set |
| SDel | key | delete a key set |
| SCount | key | returns the number of elements in the key set, the time complexity is high, not recommended |
| SMembers | key | iterate over keys by value size. High time complexity, not recommended |
sorted set
| interface | parameter | description |
|---|---|---|
| ZPush | key, tuples | add the values to the key sorted set, sorted by tuple.score from small to large |
| ZPop | keys, values | removes all values elements from the key sorted set |
| ZRange | key, offset, limit | according to the score size, iterate over the keys from small to large. If offset = -1, start traversing by score from large to small |
| ZExist | key, values | determine whether values exist in the key sorted set |
| ZDel | key | delete a key sorted set |
| ZCount | key | returns the number of elements in the sorted set of key, the time complexity is high, not recommended |
| ZMembers | key | according to the score size, iterate over the keys from small to large. High time complexity, not recommended |
bloom filter
| interface | parameter | description |
|---|---|---|
| BFCreate | key, n, p | create bloom filter, n is the number of elements, p is the false positive rate |
| BFDel | key | delete a key bloom filter |
| BFAdd | key, values | add values to bloom filter. An exception will be thrown when the bloom filter is not created |
| BFExist | key, values | determine whether values exist in the key bloom filter |
hyper log log
| interface | parameter | description |
|---|---|---|
| HLLCreate | key | create hyper log log |
| HLLDel | key | delete a hyper log log |
| HLLAdd | key, values | add values to hyper log log. An exception will be thrown when the hyper log log is not created |
| HLLCount | key | get the number of deduplicated elements of a hyper log log |
bitset
| interface | parameter | description |
|---|---|---|
| BSDel | key | delete a bitset |
| BSSetRange | key, start, end, value | set key [start, end) range bit to value |
| BSMSet | key, bits, value | set key bits to value |
| BSGetRange | key, start, end | get the bits in the range of key [start, end) |
| BSMGet | key, bits | get the bit of key bits |
| BSMCount | key | get the number of key bit = 1 |
| BSMCountRange | key, start, end | get the number of key [start, end) bit = 1 |
map
| interface | parameter | description |
|---|---|---|
| MPush | key, pairs | add pairs KV pairs to the key map |
| MPop | key, keys | remove all keys elements in the key map |
| MExist | key, keys | determine whether keys exist in the key map |
| MDel | key | delete a map |
| MCount | key | returns the number of elements in the key map, the time complexity is high, not recommended |
| MMembers | key | iterates over pairs by pair.key size. High time complexity, not recommended |
geo hash
| interface | parameter | description |
|---|---|---|
| GHCreate | key, precision | create a geo hash, precision stands for precision. |
| GHDel | key | delete a geo hash |
| GHAdd | key, points | add the points to the geo hash, and the id in the point is the unique identifier |
| GHPop | key, ids | delete points |
| GHGetBoxes | key, point | returns a list of points in the same box as a point in the key geo hash, sorted by distance from small to large |
| GHGetNeighbors | key, point | returns the list of points closest to the point in the key geo hash, sorted by distance from small to large |
| GHCount | key | returns the number of elements in the key geo hash, the time complexity is high, not recommended |
| GHMembers | key | returns a list of all points in the key geo hash. High time complexity, not recommended |
page
| interface | parameter | description |
|---|---|---|
| PList | dataType, key, offset, limit | query an existing element under a dataType. If key is not empty, get the element of key under this dataType. |
pub sub
| interface | parameter | description |
|---|---|---|
| Subscribe | topic | subscribe to a topic |
| Publish | topic, payload | post a payload to a topic |
cluster
| interface | parameter | description |
|---|---|---|
| CInfo | Get node information in the cluster |
Monitor
Install docker version grafana, prometheus (skipable)
- Start scripts/run_monitor.sh
Config grafana
- Open grafana: http://localhost:3000 (note to replace the ip address)
- Create new prometheus datasources: http://host.docker.internal:9090 (If using docker installation, this is the address. If host.docker.internal cannot be accessed, just replace prometheus.yml file host.docker.internal is your own ip address)
- Import scripts/dashboard.json file into grafana dashboard
The final effect can refer to: grafana diagram of performance test
Configuration parameters
| parameter | description | default value |
|---|---|---|
| store.engine | Storage engine, optional pebble, level, badger | pebble |
| store.path | storage directory | ./master/db/ |
| server.grpc_port | grpc port | 10000 |
| server.http_port | http port,for use by prometheus | 11000 |
| server.rate | qps per second limit | 30000 |
| cluster.path | directory where raft logs are stored | ./master/raft |
| cluster.node_id | the node id identified by the raft protocol, which must be unique | 1 |
| cluster.address | address for raft correspondence | 127.0.0.1:12000 |
| cluster.master | the address of the master node in the existing cluster is added through the http[http_port] interface exposed by the master node. If it is a new cluster, it is empty. | |
| cluster.timeout | raft protocol apply timeout, the unit is ms | 10000 |
| cluster.join | as a slave node, whether to join the master node; it needs to be set to true for the first time to join, and false to start again after joining | false |
SDB principle - storage engine selection
The core problem of the SDB project is the problem of the data storage scheme.
First, we can't write a storage engine by hand. This is too much work and unreliable. We have to
find a storage solution suitable for SDB positioning in open source projects.
SDB requires a storage engine that can provide high-performance read and write capabilities.
Commonly used stand-alone storage engine solutions include B+ tree, LSM tree, and B tree.
There is also a background, golang performs very well in cloud native, and its performance is
comparable to C language, and the development efficiency is also high, so SDB prefers to use pure
golang for development.
So now the problem becomes: it is more difficult to find a storage engine developed in pure golang
version. After collecting a series of materials, I found the following open source solutions:
- LSM
- B+ Tree
On the whole, the three storage engines golangdb, badger, and pebble are all very good.
In order to be compatible with these three storage engines, SDB Provides an
abstract interface
, and then adapt to the three storage engines.
The principle of SDB - data structure design
SDB has solved the problem of data storage through the previous three storage engines. But how to
support rich data structures on KV's storage engine?
Taking pebble as an example, first of all pebble provides the following interface capabilities:
- set(k, v)
- get(k)
- del(k)
- batch
- iterator
Next, I take the support of the List data structure as an example to analyze how SDB supports List
through the pebble storage engine.
The List data structure provides the following interfaces: LRPush, LLPush, LPop, LExist, LRange,
LCount.
If the key of a List is: [hello], and the list elements of the List are: [aaa, ccc, bbb], then each
element of the List is stored in pebble as:
| pebble key | pebble value |
|---|---|
| l/hello/{unique_ordering_key1} | aaa |
| l/hello/{unique_ordering_key2} | ccc |
| l/hello/{unique_ordering_key3} | bbb |
The pebble key generation strategy for List elements:
- data structure prefix: List is prefixed with l characters, Set is prefixed with s...
- list key part: the key of List is hello
- unique_ordering_key: The generation method is implemented by the snowflake algorithm, which guarantees local auto-increment
- pebble value part: the real content of the List element, such as aaa, ccc, bbb
Why is the insertion order of List guaranteed?
This is because pebble is an implementation of LSM, which uses lexicographical ordering of keys
internally. In order to guarantee the insertion order, SDB adds unique_ordering_key to the pebble
key As the basis for sorting, thus ensuring the insertion order.
With the pebble key generation strategy, everything becomes easier. Let's look at the core logic of
LRPush, LLPush, LPop, and LRange:
LRPush
func LRPush(key []byte, values [][]byte) (bool, error) {
batchAction := store.NewBatchAction()
defer batchAction.Close()
for _, value := range values {
batchAction.Set(generateListKey(key, util.GetOrderingKey()), value)
}
return batchAction.Commit()
}
LLPush
The logic of LLPush is very similar to that of LRPush. The difference is that as long as
{unique_ordering_key} is negative, it becomes the minimum value. In order to ensure that the values
are internally ordered, we have to - index. The logic is as follows:
func LLPush(key []byte, values [][]byte) (bool, error) {
batch := store.NewBatch()
defer batch.Close()
for i, value := range values {
batch.Set(generateListKey(key, -(math.MaxInt64 - util.GetOrderingKey())), value)
}
return batch.Commit()
}
LPop
When writing to pebble, the key is generated through the unique_ordering_key scheme. Unable to find
elements of List in pebble directly in pebble key. When deleting an element, it is necessary to
traverse all elements of the List, find the element whose value = value to be deleted, and then
delete it. The core logic is as follows:
func LPop(key []byte, values [][]byte) (bool, error) {
batchAction := store.NewBatchAction()
defer batchAction.Close()
store.Iterate(&store.IteratorOption{Prefix: generateListPrefixKey(key)},
func(key []byte, value []byte) {
for i := range values {
if bytes.Equal(values[i], value) {
batchAction.Del(key)
}
}
})
return batchAction.Commit()
}
LRange
Similar to delete logic, through iterator The interface is
traversed. Additional support for reverse iteration is here
Allow offset to pass in -1, which means to iterate from the back.
func LRange(key []byte, offset int32, limit uint32) ([][]byte, error) {
index := int32(0)
res := make([][]byte, limit)
store.Iterate(&engine.PrefixIteratorOption{
Prefix: generateListPrefixKey(key), Offset: offset, Limit: limit},
func(key []byte, value []byte) {
res[index] = value
index++
})
return res[0:index], nil
}
The above implements the support for the List data structure.
Other data structures are generally similar in logic, among
which sorted_set
more complicated. You can check it yourself.
LPop optimization
Smart people can see that the logic of LPop consumes a lot of performance in the case of a large
amount of data. It is because we cannot know the key corresponding to the value in the storage
engine, and we need to load all the elements in the List After coming out, judge one by one before
deleting.
In order to reduce time complexity and improve performance. Take List: [hello] -> [aaa, ccc, bbb] as
an example. The storage model will be changed to the following:
Positive row index structure [unchanged]:
| pebble key | pebble value |
|---|---|
| l/hello/{unique_ordering_key1} | aaa |
| l/hello/{unique_ordering_key2} | ccc |
| l/hello/{unique_ordering_key3} | bbb |
Secondary index structure
| pebble key | pebble value |
|---|---|
| l/hello/aaa/{unique_ordering_key1} | aaa |
| l/hello/ccc/{unique_ordering_key2} | ccc |
| l/hello/bbb/{unique_ordering_key3} | bbb |
With this auxiliary index, we can determine whether there is an element of a certain value in the
List by means of prefix retrieval. This reduces time complexity and improves performance. It is also
necessary to write the auxiliary index when writing the element, so the core logic will be changed
to:
func LRPush(key []byte, values [][]byte) (bool, error) {
batch := store.NewBatch()
defer batch.Close()
for _, value := range values {
id := util.GetOrderingKey()
batch.Set(generateListKey(key, id), value)
batch.Set(generateListIdKey(key, value, id), value)
}
return batch.Commit()
}
func LLPush(key []byte, values [][]byte) (bool, error) {
batch := store.NewBatch()
defer batch.Close()
for i, value := range values {
id := -(math.MaxInt64 - util.GetOrderingKey())
batch.Set(generateListKey(key, id), value)
batch.Set(generateListIdKey(key, value, id), value)
}
return batch.Commit()
}
func LPop(key []byte, values [][]byte) (bool, error) {
batch := store.NewBatch()
defer batch.Close()
for i := range values {
store.Iterate(&engine.PrefixIteratorOption{Prefix: generateListIdPrefixKey(key, values[i])},
func(storeKey []byte, storeValue []byte) {
if bytes.Equal(storeValue, values[i]) {
batch.Del(storeKey)
infos := strings.Split(string(storeKey), "/")
id, _ := strconv.ParseInt(infos[len(infos)-1], 10, 64)
batch.Del(generateListKey(key, id))
}
})
}
return batch.Commit()
}
The principle of SDB - the mapping of relational model to KV model
With the above solution, you probably know how the KV storage engine supports data structures. But
this approach is crude and cannot be generalized.
Referring to TiDB Design, SDB has designed a
relational model to KV structure.
In SBD, data is constructed from Collections and Rows. in:
Collection
A table similar to a database is a logical concept. Each dataType (such as List) corresponds to a
Collection. A Collection contains multiple Rows.A Row contains unique keys: key, id, value, indexes, is the data that is actually stored in KV
storage. Each row row has rowKey as the unique value, rowKey ={dataType} + {key} + {id}Each row contains N indexes, each index has indexKey as a unique value, indexKey
={dataType} + {key} + idx_{indexName} + {indexValue} + {id}
Take ListCollection as an example, the key of the List is [l1], assuming that the Collection has 4
rows of Row, and each row of Row has the index of value and score
Then the Row structure of each row is as follows:
{ {key: l1}, {id: 1.1}, {value: aaa}, {score: 1.1}, indexes: [ {name: "value", value: aaa}, {name: "score", value: 1.1} ] }
{ {key: l1}, {id: 2.2}, {value: bbb}, {score: 2.2}, indexes: [ {name: "value", value: bbb}, {name: "score", value: 2.2} ] }
{ {key: l1}, {id: 3.3}, {value: ccc}, {score: 3.3}, indexes: [ {name: "value", value: ccc}, {name: "score", value: 3.3} ] }
{ {key: l1}, {id: 4.4}, {value: aaa}, {score: 4.4}, indexes: [ {name: "value", value: aaa}, {name: "score", value: 4.4} ] }
Take Row with id = 1.1 as an example, dataType = 1, rowKey = 1/l1/1.1, valueIndexKey
= 1/l1/idx_value/aaa/1.1, scoreIndexKey = 1/l1/idx_score/1.1/1.1 The written data is:
rowKey: 1/l1/1.1 -> { {key: l1}, {id: 1.1}, {value: aaa}, {score: 1.1}, indexes: [ {name: "value", value: aaa}, {name: "score", value: 1.1} ] }
valueIndexKey: 1/l1/idx_value/aaa/1.1, -> 1/l1/1.1
scoreIndexKey: 1/l1/idx_score/1.1/1.1 -> 1/l1/1.1
In this way, the data structure, KV storage, and relational model are connected.
SDB principle - communication protocol scheme
After solving the problems of storage and data structure, SDB faces the problem of the [last mile]
which is the choice of communication protocol.
SDB is positioned to support multiple languages, so it is necessary to choose a communication
framework that supports multiple languages.
grpc is a very good choice. You only need to use the SDB proto file to automatically generate
clients in various languages through the protoc command line tool, which solves the problem of
developing different clients.
SDB principle - master-slave architecture
After solving all the above problems, SDB is already a reliable stand-alone NoSQL database.
In order to further optimize SDB, a master-slave architecture has been added to SDB.
There are three options for the raft protocol under the golang language, namely:
In order to support the Chinese project, dragonboat was chosen. PS: Thank you, Chinese!
After using the raft protocol, the throughput of the entire cluster drops a little, but with the horizontally expanded read capability, the benefits are still obvious.
Version update record
v3.0.0
- commit Implemented master-slave architecture based on raft
v1.7.0
- commit Use sharding to store bitset, bitset no longer needs to be initialized, with the function of [automatic expansion]
Thanks to the power of open source, I will not list them all here, please move to go.mod
Posted on May 12, 2022
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related


November 29, 2024