Semantic Search With Xata, OpenAI, TypeScript, and Deno

Tudor Golubenco
Posted on March 21, 2023
At the same time we launched our ChatGPT integration, we also added a new vector type to Xata, making it easy to store embeddings. Additionally, we have added a new vectorSearch endpoint, which performs similarity search on embeddings.
Let’s take a quick tour to see how you can use these new capabilities to implement semantic search. We’re going to use the OpenAI embeddings API, TypeScript and Deno. This tutorial assumes prior knowledge of TypeScript, but no prior knowledge of Xata, Deno, or OpenAI.
What is semantic search?
Instead of just matching keywords, as traditional search engines do, semantic search attempts to understand the context and intent of the query and the relationships between the words used in it.
For example, let’s say you have the following sample sentences:
- "The quick brown fox jumps over the lazy dog story"
- “The vehicle collided with the tree”
- “The cat growled towards the dog”
- "Lorem ipsum dolor sit amet, consectetur adipiscing elit”
- “The sunset painted the sky with vibrant colors”
If you search for “sample text in latin”, traditional keyword search won’t match the “lorem ipsum” text, but semantic search will (and we’re going to demo it in this article).
Similarly, if you search for “the kitty hissed at the puppy”, semantic search will see that the phrase has the same meaning as “the cat growled towards the dog”, even if they use none of the same words. Or, for another example, “vanilla sky” should bring up the “The sunset painted the sky with vibrant colors” sentence. Pretty cool, right? This is now quite possible thanks large-language models and vector search.
A quick intro to embeddings
From a data point of view, embeddings are simply arrays of floats. They are the output of ML models, where the input can be a word, a sentence, a paragraph of text, an image, an audio file, a video file, and so on.

Each number in the array of floats represents the input text on a particular dimension, which depends on the model. This means that the more similar the embeddings are, the more “similar” the input objects are. I’ve put “similar” in quotes because it depends on the model what kind of similar it means. When it comes to text, it’s usually about “similar in meaning”, even if different words, expressions, or languages are used.
Reducing complex data to an array of numbers representing its qualities turns out to be very useful for a number of use cases. Think of reverse image search, recommendations algorithms for video and music, product recommendations, categorizing products, and so on.
Vector type in Xata
If you want to follow along, start with steps:
- Sign up or sign into Xata here (the usage from this tutorial fits well within the free tier, so you don’t need to set up billing)
- Create a database named
vectors - Create a table named
Sentences - Add two columns:
-
sentenceof type string -
embeddingof type vector. Use 1536 as the dimension
-

When you are done, the schema should look like this:

Initialize the Xata project
To get ready for running the typescript code, install the Xata CLI:
npm install -g @xata.io/cli@latest
Run xata auth login to authenticate the CLI. This will open a browser window and prompt you to generate a new API key. Give it any name you’d like.
xata auth login
Create a folder for the code:
mkdir sentences
cd sentences
And run xata init to connect it to the Xata DB:
xata init
The Xata CLI will ask you to select the database and then ask you how to generate the types. Select Generate TypeScript code with Deno imports. Use default settings for the rest of the questions.

Prepare OpenAI and Deno
Create an OpenAI account and generate a key. Note that you need to set up billing for OpenAI in order for to run these examples, but the cost will be tiny (under $1).
Add the OpenAI key to the .env file which was created by the xata init command above. Your .env should look something like this:
# API key used by the CLI and the SDK
# Make sure your framework/tooling loads this file on startup to have it available for the SDK
XATA_API_KEY=xau_<redacted>
OPENAI_API_KEY=sk-<redacted>
Install the Deno CLI. See this page for the various install options, on macOs with Homebrew it is:
brew install deno
Load data
It’s now the time to write a bit of TypeScript code. Create a loadWithEmbeddings.ts file top level in your project with the following contents:
import { Configuration, OpenAIApi } from "npm:openai";
import { getXataClient } from "./src/xata.ts";
import { config as dotenvConfig } from "<https://deno.land/x/dotenv@v1.0.1/mod.ts>";
dotenvConfig({ export: true });
const openAIConfig = new Configuration({
apiKey: Deno.env.get("OPENAI_API_KEY"),
});
const openAI = new OpenAIApi(openAIConfig);
const xata = getXataClient();
const sentences: string[] = [
"The quick brown fox jumps over the lazy dog story",
"The vehicle collided with the tree",
"The cat growled towards the dog",
"Lorem ipsum dolor sit amet, consectetur adipiscing elit",
"The sunset painted the sky with vibrant colors",
];
for (const sentence of sentences) {
const resp = await openAI.createEmbedding({
input: sentence,
model: "text-embedding-ada-002",
});
const [{ embedding }] = resp.data.data;
xata.db.Sentences.create({
sentence,
embedding,
});
}
Step by step, this is what the script is doing:
- Uses
dotenvto load the.envfile into the current environment. This makes sure theXATA_API_KEYand theOPENAI_API_KEYare available to the rest of the script. - Initializes the OpenAI and Xata client libraries.
- Defines the test data in the
sentencesarray. - For each
sentence, calls the OpenAI embeddings API to get the embedding for it. - Inserts a record containing the sentence and the embedding into Xata.
Execute the script like this:
deno run --allow-net --allow-env --allow-read --allow-run ./loadWithEmbeddings.ts
If you visit the Xata UI now, you should see the data loaded, together with the embeddings.
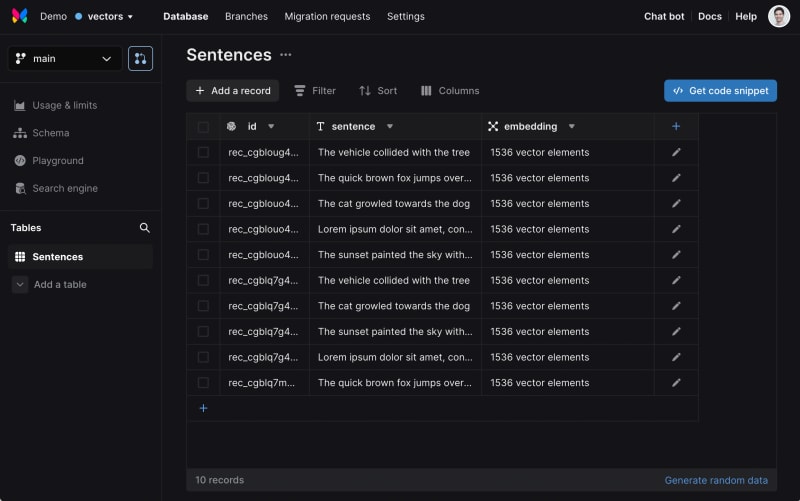
Run search queries
Let’s write another simple script that performs a search based on an input query. Name this script search.ts.
import { Configuration, OpenAIApi } from "npm:openai";
import { getXataClient } from "./src/xata.ts";
import { config as dotenvConfig } from "<https://deno.land/x/dotenv@v1.0.1/mod.ts>";
dotenvConfig({ export: true });
const openAIConfig = new Configuration({
apiKey: Deno.env.get("OPENAI_API_KEY"),
});
const openAI = new OpenAIApi(openAIConfig);
const xata = getXataClient();
if (Deno.args.length !== 1) {
console.log("Please provide a search query");
console.log(
"Example: deno run --allow-net --allow-env search.ts 'the quick brown fox'"
);
Deno.exit(1);
}
const query = Deno.args[0];
const resp = await openAI.createEmbedding({
input: query,
model: "text-embedding-ada-002",
});
const [{ embedding }] = resp.data.data;
const results = await xata.db.Sentences.vectorSearch("embedding", embedding);
for (const result of results) {
console.log(result.getMetadata().score, "|", result.sentence);
}
Here is what’s going on in the script:
- The beginning is similar as for the previous script, using
dotenvto load the.envfile and then initializing the client libraries for OpenAI and Xata - Read the query as the first argument passed to the script
- Use the OpenAI embeddings API to create embeddings for the query
- Run a vector search using the Xata Vector Search API. This finds vectors that are similar to the provided embedding
- Print the results, together with the similarity score
To run the script, execute it like this:
$ deno run --allow-net --allow-env --allow-read --allow-run \\
./search.ts 'sample text in latin'
1.8154079 | Lorem ipsum dolor sit amet, consectetur adipiscing elit
1.7424928 | The quick brown fox jumps over the lazy dog story
1.7360129 | The cat growled towards the dog
1.7311659 | The sunset painted the sky with vibrant colors
1.7038174 | The vehicle collided with the tree
As you can see, searching for “sample text in latin” results in the “Lorem ipsum” text as we hoped. You can also try some variations, for example, “sample sentence” still brings the “Lorem ipsum” one as the top result:
$ deno run --allow-net --allow-env --allow-read --allow-run \\
./search.ts 'sample sentence'
1.805396 | Lorem ipsum dolor sit amet, consectetur adipiscing elit
1.7715557 | The quick brown fox jumps over the lazy dog story
1.7608802 | The sunset painted the sky with vibrant colors
1.7573793 | The cat growled towards the dog
1.7493906 | The vehicle collided with the tree
The scores on the left are numbers between 0 and 2 which indicate how close each sentence is to the provided query. If you run with a sentence that exits in the data, you’ll get a score very close to 2:
$ deno run --allow-net --allow-env --allow-read --allow-run \\
./search.ts 'The quick brown fox jumps over the lazy dog story'
1.9999993 | The quick brown fox jumps over the lazy dog story
1.8063612 | The cat growled towards the dog
1.769694 | Lorem ipsum dolor sit amet, consectetur adipiscing elit
1.7673006 | The vehicle collided with the tree
1.7605586 | The sunset painted the sky with vibrant colors
Now let’s try the “vanilla sky” query:
$ deno run --allow-net --allow-env --allow-read --allow-run \\
./search.ts 'vanilla sky'
1.8137007 | The sunset painted the sky with vibrant colors
1.7584264 | Lorem ipsum dolor sit amet, consectetur adipiscing elit
1.7579571 | The quick brown fox jumps over the lazy dog story
1.7505519 | The vehicle collided with the tree
1.738231 | The cat growled towards the dog
Bingo, top result matches what we expected.
Another one to try:
$ deno run --allow-net --allow-env --allow-read --allow-run \\
./search.ts 'The car crashed into the oak.'
1.907266 | The vehicle collided with the tree
1.7763984 | The cat growled towards the dog
1.7755028 | The quick brown fox jumps over the lazy dog story
1.7745116 | The sunset painted the sky with vibrant colors
1.7570261 | Lorem ipsum dolor sit amet, consectetur adipiscing elit
Again, the sentence with the same meaning shows up at the top with a score close to 2.
Conclusion
The large-language-models are powerful tools that open up new use cases. Semantic search is one of these use cases, and we’ve seen how the Xata vector search can be used to implement it. You can also use it to build recommendation engines, or finding similar entries in a knowledge-base, or questions in a Q&A website.
If you’re running this tutorial, please join us on the Xata Discord and let us know what you are building!
Posted on March 21, 2023
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.