Computer Network Concepts - The one and only guide you need

WEI FENG
Posted on December 2, 2021

"To become a Web Frontend Developer, we can never survive without Computer network knowledges. Frontend is never solely about Javascript or CSS. We work closely with network protocol and http request daily"
Table Of Contents
1. Common HTTP request that we will use
2. Inheritable and non-inheritable properties in CSS
3. HTTP respond Header
4. Common HTTP respond status code
5. Key differences between HTTP=1.0, HTTP=1.1, 2.0
6. What Happens When You Type URL into the browser
7. How do we understand keep-alive connection
8. What's the pros and cons for HTTP request
9. HTTPS protocol
10. Understand the OSI 7-layers model
11.TCP and UDP
12. Websocket
13. Domain Name System (DNS)
Other Contents
HTML - The one and only guide you need (in progress)
React Concepts Part.1 - The one and only guide you need
React Concepts Part.2 - The one and only guide you need
CSS Concepts - The one and only guide you need
Web Optimization Concepts - The one and only guide you need
Browser Concepts - The one and only guide you need
1. Common HTTP request that we will use
> - What is HTTP? Refer to the W3school for full detail
The Hypertext Transfer Protocol (HTTP) is designed to enable communications between clients and servers.
HTTP works as a request-response protocol between a client and server.
| Request Method | Explaination |
|---|---|
| GET: | GET is used to request data from a specified resource. |
| POST: | POST is used to send data to a server to create/update a resource. |
| PUT: | PUT is used to send data to a server to create/update a resource. |
| DELETE: | The DELETE method deletes the specified resource. |
| HEAD: | HEAD is almost identical to GET, but without the response body. |
| OPTIONS: | The OPTIONS method describes the communication options for the target resource. (used for CORS preflight) |
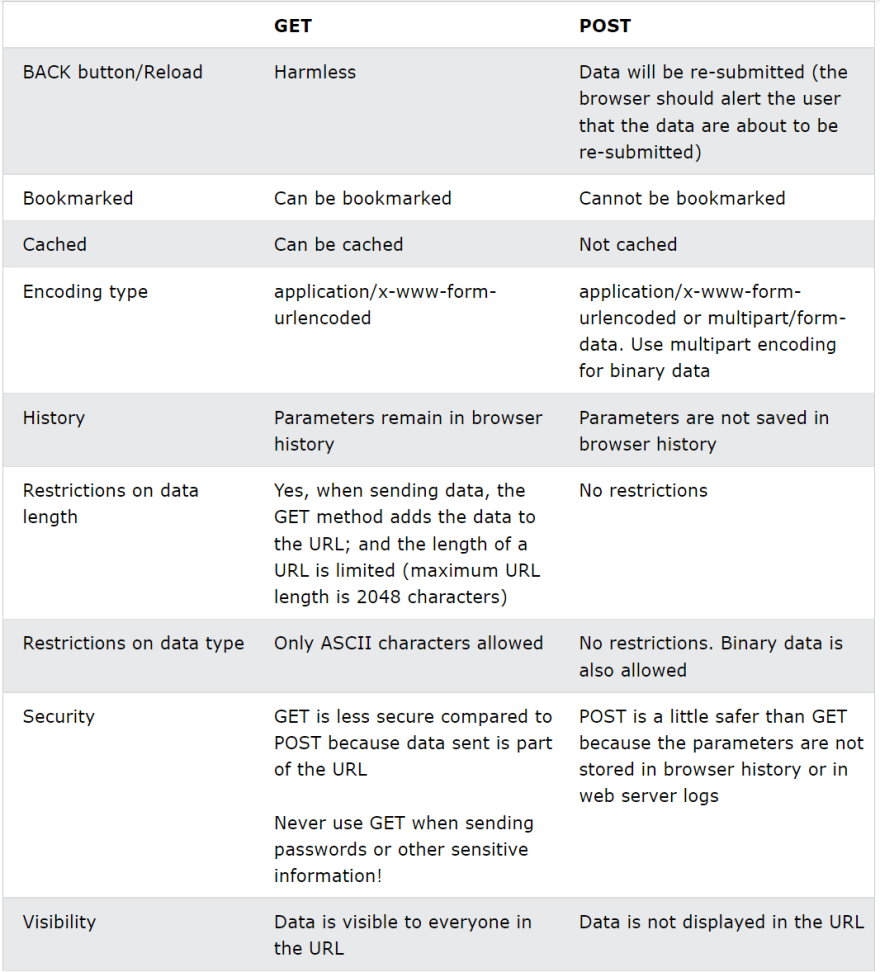
Difference between GET and POST : Noted that if URL length does not exceed 2,083 characters, then GET request will be good with almost every browser.
2. HTTP request Header
GET /home.html HTTP/1.1
// Http method, path of the resource, protocol
Host: developer.mozilla.org
// Domain of the current page who sends the request
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:50.0) Gecko/20100101 Firefox/50.0
// Browser'user Proxy
Accept: text/html,application/xhtml+xml,application/xml;q=0.9
//accepted content type for the browser
Accept-Language: en-US,en;q=0.5
//accept language for the browser
Accept-Encoding: gzip, deflate, br
//accepted encoding method
Referer: https://developer.mozilla.org/testpage.html
//the URL that make the request
Connection: keep-alive
//the connection type between sever and client
If-Modified-Since: Mon, 18 Jul 2016 02:36:04 GMT
If-None-Match: "c561c68d0ba92bbeb8b0fff2a9199f722e3a621a"
Cache-Control: max-age=0
//for cache control
3. HTTP respond Header
200 OK
// HTTP response status codes, short description
Access-Control-Allow-Origin: *
// CORS
Connection: Keep-Alive
//connection type
Content-Type: text/html; charset=utf-8
// document type
Date: Mon, 18 Jul 2016 16:06:00 GMT
//responding time
Etag: "c561c68d0ba92bbeb8b0f612a9199f722e3a621a"
Last-Modified: Mon, 18 Jul 2016 02:36:04 GMT
//for cache control
Set-Cookie: mykey=myvalue; expires=Mon, 17-Jul-2017 16:06:00 GMT; Max-Age=31449600; Path=/; secure
// set cookie expire time and other related information
4. Common HTTP respond status code
Refer to this documentation for details
Successful responses
- 200 OK
The request succeeded.
- 204 No Content
There is no content to send for this request, but the headers may be useful. The user agent may update its cached headers for this resource with the new ones.
- 206 Partial Content
This response code is used when the Range header is sent from the client to request only part of a resource.
Redirection messages
- 301 Moved Permanently
The URL of the requested resource has been changed permanently. The new URL is given in the response.
- 302 temporary moved
A 301 redirect means that the page has permanently moved to a new location. A 302 redirect means that the move is only temporary.
- 304 Not Modified
This is used for caching purposes. It tells the client that the response has not been modified, so the client can continue to use the same cached version of the response.
Client error responses
- 400 Bad Request
The server could not understand the request due to invalid syntax.
- 401 Unauthorized
Although the HTTP standard specifies "unauthorized", semantically this response means "unauthenticated". That is, the client must authenticate itself to get the requested response.
- 403 Forbidden
The client does not have access rights to the content; that is, it is unauthorized, so the server is refusing to give the requested resource. Unlike 401 Unauthorized, the client's identity is known to the server.
- 404 Not Found
The server can not find the requested resource. In the browser, this means the URL is not recognized. In an API, this can also mean that the endpoint is valid but the resource itself does not exist.
Server error responses
- 500 Internal Server Error
The server has encountered a situation it does not know how to handle.
- 501 Not Implemented
The request method is not supported by the server and cannot be handled. The only methods that servers are required to support (and therefore that must not return this code) are GET and HEAD.
- 502 Bad Gateway
This error response means that the server, while working as a gateway to get a response needed to handle the request, got an invalid response.
- 503 Service Unavailable
The server is not ready to handle the request. Common causes are a server that is down for maintenance or that is overloaded.
5. Key differences between HTTP=1.0, HTTP=1.1, 2.0
Refer to the full article here
1. PersistentConnection
HTTP 1.0 stipulates that the browser and the server only maintain a short connection. The server immediately disconnects the TCP connection after processing the request.HTTP 1.1 supports Persistent Connection, and Long connection is used by default.For HTTP 1.1 long connections, new request headers need to be added to help achieve this. The value of the Connection request header is Keep-Alive, the client informs the server to keep the connection after returning the result of this request; the value of the Connection request header is close When, the client notifies the server to close the connection after returning the result of this request.
2.Pipelining
Request pipeline (Pipelining) processing, multiple HTTP requests and responses can be transmitted on a TCP connection, reducing the consumption and delay of establishing and closing connections.3.host field:
In HTTP1.0, it is believed that each server is bound to a unique IP address. Therefore, the URL in the request message does not convey the hostname. But with the development of virtual host technology, there can be multiple virtual hosts (Multi-homed Web Servers) on a physical server, and they share an IP address. With the host field HTTP1.1 can send request to different host on the same server4.Bandwidth optimization:
In HTTP/1.0, there are some phenomena of wasting bandwidth. For example, the client only needs a part of an object, but the server sends the entire object.The range header field is introduced in the request message in HTTP/1.1,It allows to request only certain part of the resource. If the server correspondingly returns the content requested by the object, the response code is 206 (Partial Content), which can prevent the Cache from mistaking the response as a complete object.
5.Cache:
HTTP/1.1 adds the Cache-Control header field which supports an extensible instruction subset: for example, the max-age instruction supports relative timestamp.HTTP 2.0
1.Multiplexing:
HTTP 2.0 uses multiplexing technology to process multiple requests concurrently on the same connection, and the number of concurrent requests is several orders of magnitude larger than HTTP 1.1.2.data compression:
HTTP 1.1 does not support header data compression, HTTP 2.0 uses HPACK algorithm to compress header data, so that the data volume is smaller and the transmission on the network will be faster.3.Server push:
When we request data from a web server that supports HTTP2.0, the server will push some resources needed by the client to the client by the way, so that the client will not create a connection again and send a request to the server to obtain it. This method is very suitable for loading static resources.4.Binary framing:
HTTP/2 adds a binary framing layer between the application layer (HTTP/2) and the transport layer (TCP or UDP).
Without changing the semantics, methods, status codes, URI and header fields of HTTP/1.x, it solves the performance limitations of HTTP 1.1, improves transmission performance, and achieves low latency and high throughput.
6. What Happens When You Type in a URL into the browser
1. URL parsing: The browser will extract the protocol and path of the requested resource.
2. Cache Validation: Then browser will verify whether such requested resource has been cached and still valid. If yes it will return the cached result immediately or else it will send a new request to the server.
3. DNS query: The browser checks the browser cache for a DNS record to find the corresponding IP address. If not found, it will proceed to the OS cache followed by router cache. Lastly, ISP(Internet Service Provider)’s DNS server initiates a DNS query to find the IP address.
4. Get the MAC address: After the browser gets the IP address, the data transmission also needs to know the destination host's MAC address.
5. The browser initiates a TCP connection with the server. It will require a three way handshake to establish the TCP connection between them.
6. The browser sends an HTTP request to the webserver. Once the TCP connection is established, the browser sends a HTTP request. Refer to the above section regarding HTTP request.
7. Server handle the request and sends out an HTTP response.
The server response contains the web page you requested as well as the status code, compression type (Content-Encoding), how to cache the page (Cache-Control), any cookies to set, privacy information, etc. Refer to the above section regarding HTTP response.
8. The browser parse and paint the HTML content The browser displays the HTML content in phases. First, it will render the DOM tree and CSSOM tree through the respective files and construct a render tree base on them. Once this is done the browser will layout the page through the render tree and use its api to paint the user interface on viewport.
9. TCP four way handshake to stop the connection Once the client thinks it has received everything it needs, it will start a four way handshake with the server to close the connection. Refer to the TCP section below for more information.
7. How do we understand keep-alive connection
In HTTP1.0, by default is to create a new connection between the client and the server for each request/response, and disconnect immediately after completion, which is a short connection.
When the Keep-Alive mode is used, the Keep-Alive function keeps the client-to-server connection valid. When a subsequent request to the server occurs, the Keep-Alive function avoids establishing or re-establishing a connection, which is a long connection. The method of use is as follows:
The client sends the request to the server while adding the Connection field to the header. The server sends the Connection: Keep-Alive field back to the client. The client receives the Connection field and then Keep-Alive connection established successfully.
To close the connection, client side will send connection:closed inside of its request, server will respond and close the keep-alive connection.
Pros of long connection
- less cpu and memory usage as there are less connections
- allows pipelining (refer to the above session about pipelining)
- let congestion control will be needed
- less delay in the subsequent request as the client side do not need to perform the three way handshake on every request.
Cons of long connection
The long tcp connection may waste resources if it stays idle for long period.

8. What's the pros and cons for HTTP request
Pros
1.Simple and fast: When a client requests a service from the server, it only needs to transmit the request method and path. Because the HTTP protocol is simple, the HTTP server request processing time will be very fast.
2.connectionless: No connection means it limits each connection to only process one request. After the server has processed the client's request and received the client's response, it will disconnect. This method can save transmission time.
3.Stateless: HTTP protocol is a stateless protocol, where the state refers to the context information of the communication process. The lack of state means that if the previous information is needed for subsequent processing, it must be retransmitted, which may result in an increase in the amount of data transmitted per connection. On the other hand, if the server does not need previous information, its response is faster.
4.Flexible: HTTP allows the transmission of any type of data object. The type being transmitted is marked by Content-Type.
Cons
Clear text transmission: The messages in the protocol are in text form, which is directly exposed to the outside world and is not safe. It may be manipulated by third party that's listening to the connection.
9. HTTPS protocol
Hypertext transfer protocol secure (HTTPS) is the secure version of HTTP, which is the primary protocol used to send data between a web browser and a website. HTTPS is encrypted in order to increase security of data transfer. This is particularly important when users transmit sensitive data, such as by logging into a bank account, email service, or health insurance provider.
What happens during a TLS handshake?
During the course of a TLS handshake, the client and server together will do the following:
1.Specify which version of TLS (TLS 1.0, 1.2, 1.3, etc.) they will use
2.Decide on which cipher suites (see below) they will use
3.Authenticate the identity of the server via the server’s public
key and the SSL certificate authority’s digital signature
4.Generate session keys in order to use symmetric encryption after the handshake is complete
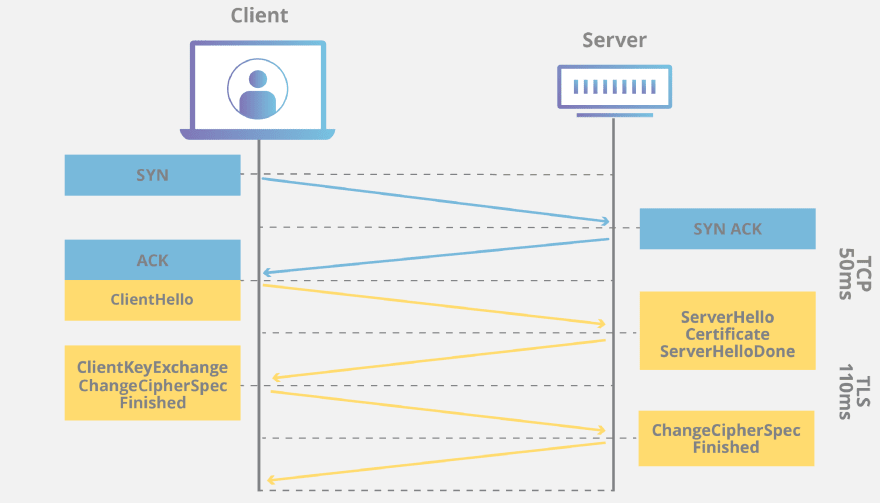
Read more about https handshakes here
The Pros of HTTPS are as follows:
Use the HTTPS protocol to authenticate users and servers, and ensure that data is sent to the correct client and server;
Using HTTPS protocol can carry out encrypted transmission, identity authentication, communication is more secure, prevent data from being stolen and modified during transmission, and ensure data security;
The Cons of HTTPS are as follows:
HTTPS needs to perform encryption and decryption processing for both the server and the client, which consumes more server resources and the process is complicated
The handshake phase of the HTTPS protocol is time-consuming, which increases the loading time of the page;
SSL certificate is expensive in cost (We talking about real money), the more powerful the certificate, the higher the cost;
The SSL certificate needs to be bind with an IP, and multiple domain names cannot be bind to the same IP.
10. Understand the OSI 7-layers model
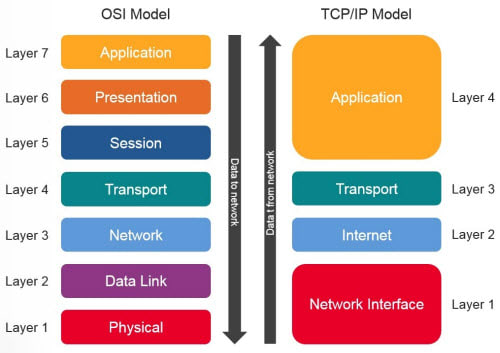
Click here for more information on each layer's functionality
The Open Systems Interconnection (OSI) model describes seven layers that computer systems use to communicate over a network. It was the first standard model for network communications, adopted by all major computer and telecommunication companies in the early 1980s
The modern Internet is not based on OSI, but on the simpler TCP/IP model. However, the OSI 7-layer model is still widely used, as it helps visualize and communicate how networks operate, and helps isolate and troubleshoot networking problems.
11.TCP and UDP
What is the Difference Between TCP and UDP?

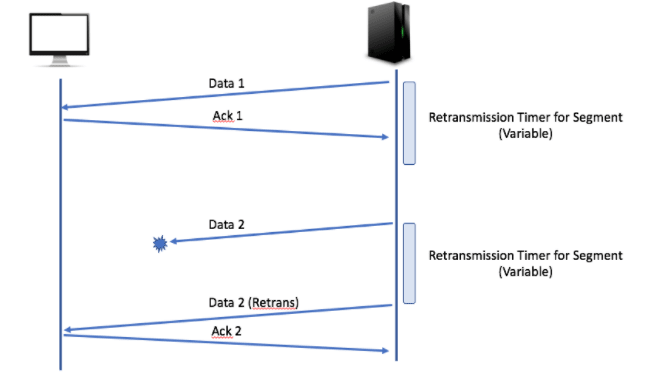
Each byte of data sent in a TCP connection has an associated sequence number. This is indicated on the sequence number field of the TCP header.
When the receiving socket detects an incoming segment of data, it uses the acknowledgement number in the TCP header to indicate receipt. After sending a packet of data, the sender will start a retransmission timer of variable length. If it does not receive an acknowledgment before the timer expires, the sender will assume the segment has been lost and will retransmit it.
The TCP congestion control mechanism is consists following four mechanisms (refer to the link above to get more details):
- Slow start
- Congestion avoidance
- Fast retransmission
- Fast recovery

TCP 3-way handshake and close connection
Three way handshake (refer to this link for details)

Step 1 (SYN): In the first step, the client wants to establish a connection with a server, so it sends a segment with SYN(Synchronize Sequence Number) which informs the server that the client is likely to start communication and with what sequence number it starts segments with
Step 2 (SYN + ACK): Server responds to the client request with SYN-ACK signal bits set. Acknowledgement(ACK) signifies the response of the segment it received and SYN signifies with what sequence number it is likely to start the segments with
Step 3 (ACK): In the final part client acknowledges the response of the server and they both establish a reliable connection with which they will start the actual data transfer
Close connection (refer to this link for details)

Step 1 (FIN From Client) –
Suppose that the client application decides it wants to close the connection. (Note that the server could also choose to close the connection). This causes the client to send a TCP segment with the FIN bit set to 1 to the server and to enter the FIN_WAIT_1 state. While in the FIN_WAIT_1 state, the client waits for a TCP segment from the server with an acknowledgment (ACK).Step 2 (ACK From Server) –
When the Server received the FIN bit segment from Sender (Client), Server Immediately sends acknowledgement (ACK) segment to the Sender (Client).Step 3 (Client waiting) –
While in the FIN_WAIT_1 state, the client waits for a TCP segment from the server with an acknowledgment. When it receives this segment, the client enters the FIN_WAIT_2 state. While in the FIN_WAIT_2 state, the client waits for another segment from the server with the FIN bit set to 1.Step 4 (FIN from Server) –
The server sends the FIN bit segment to the Sender(Client) after some time when the Server sends the ACK segment (because of some closing process in the Server).Step 5 (ACK from Client) –
When the Client receives the FIN bit segment from the Server, the client acknowledges the server’s segment and enters the TIME_WAIT state. The TIME_WAIT state lets the client resend the final acknowledgment in case the ACK is lost. The time spent by clients in the TIME_WAIT state depends on their implementation, but their typical values are 30 seconds, 1 minute, and 2 minutes. After the wait, the connection formally closes and all resources on the client-side (including port numbers and buffer data) are released.
12. Websocket
The WebSocket API is an advanced technology that makes it possible to open a two-way interactive communication session between the user's browser and a server. With this API, you can send messages to a server and receive event-driven responses without having to poll the server for a reply.
WebSocket mechanism: The client notifies the WebSocket server of an event with all recipient IDs, and the server immediately notifies all active clients after receiving it, only those client whose ID is in the recipient list will handle the event from websocket server.
The advantage of WebSocket are as follows:
Support two-way communication, real-time data streaming
We can send text or binary data
Built on the TCP protocol, the implementation at the server side is relatively easy
The data format is relatively lightweight, the resource required is small
There is no same origin restriction, the client can communicate with any server
It has good compatibility with HTTP protocol. The default ports used by websocket are also 80 and 443.
13. Domain Name System (DNS)
- DNS is the abbreviation of Domain Name System, and it provides a host name to IP address conversion service. It is a distributed database composed of hierarchical DNS servers.
It is an application layer protocol that defines how the host queries this distributed database. DNS makes our life easier for not having to remember the IP address.
Function: Resolve the domain name into an IP address. The client sends a domain name query request to the DNS server (the DNS server has its own IP address), and the DNS server informs the client of the IP address of the Web server.
2. Does DNS use TCP and UDP at the same time?
DNS takes port 53 and uses TCP and UDP protocols at the same time.
(1) Use TCP protocol for zone transfer
The secondary domain name server will regularly (usually 3 hours) to query the main domain name server to find out whether the data has changed. If there is a change, a zone transfer will be performed for data synchronization. The zone transfer uses TCP instead of UDP, because the amount of data transferred synchronously is much more than the amount of data in a request response.
TCP is a reliable connection, which guarantees the accuracy of data.
(2) UDP packets are smaller in size. UDP packets can't be greater than 512 bytes. So any application needs data to be transferred greater than 512 bytes require TCP in place. For example, DNS uses both TCP and UDP for valid reasons described below. UDP messages aren't larger than 512 Bytes and are truncated when greater than this size. DNS uses TCP for Zone transfer and UDP for name, and queries either regular (primary) or reverse. UDP can be used to exchange small information whereas TCP must be used to exchange information larger than 512 bytes. If a client doesn't get response from DNS, it must retransmit the data using TCP after 3-5 seconds of interval.
Posted on December 2, 2021
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related


