Chapter 1· Computer Vision(1) Object Detection

Walkman42
Posted on September 16, 2023
0. Getting Started with Computer Vision Through Gaming
最近开始将我的教程翻译成英文,由于翻译过程中涉及示例代码的i18n修改,进度可能要稍微落后于我的中文博客。如果您有中文阅读能力,可以移步这里。
Recently, I started translating my tutorials into English.
Due to internationalization modifications in the example code during the translation process, and the progress may be slightly behind my Chinese blog. If you have the ability to read Chinese, you can move HERE.
本文中文地址|Chinese source text link

Recently, I've become fascinated with a game called "Night of the Full Moon", which is a card-based auto-battler game similar to Teamfight Tactics and Hearthstone.
Due to the lack of comprehensive official resources, it's quite challenging for a tech enthusiast like me to get started.
Okay, we are going to create a game database together.
The cards in the game look like this:
| English Example | Chinese Example |
|---|---|
 |
 |
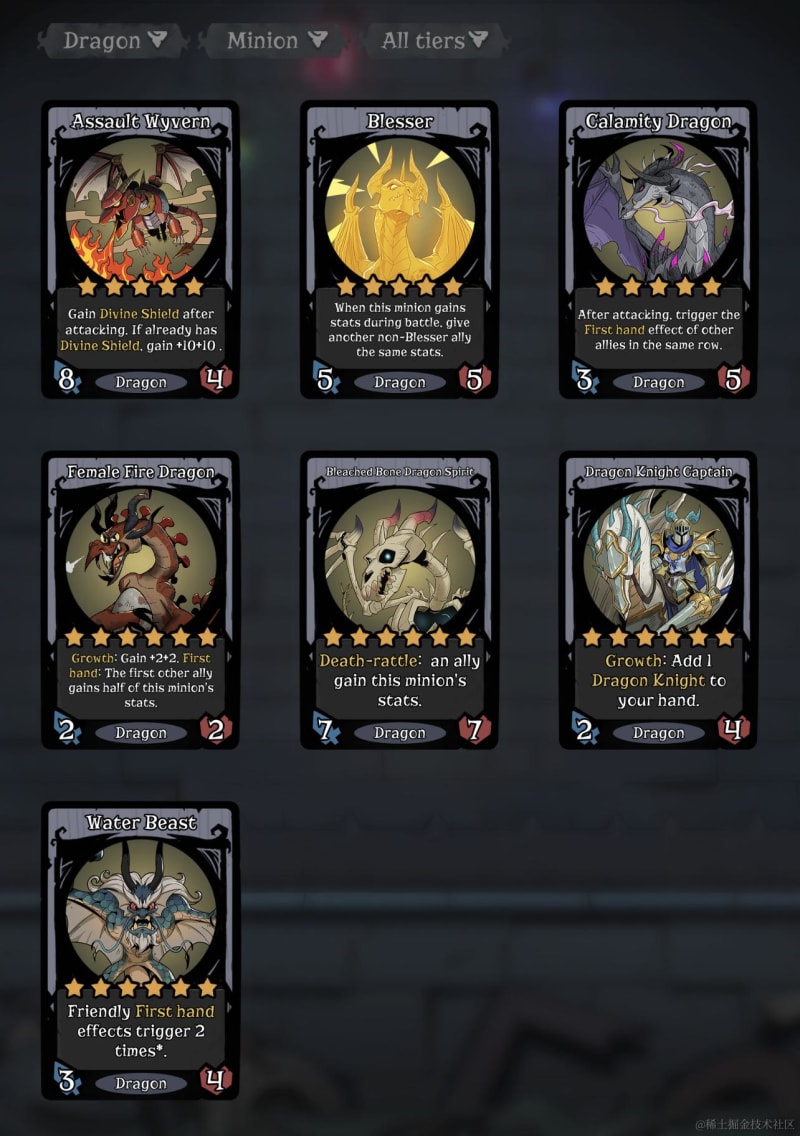 |
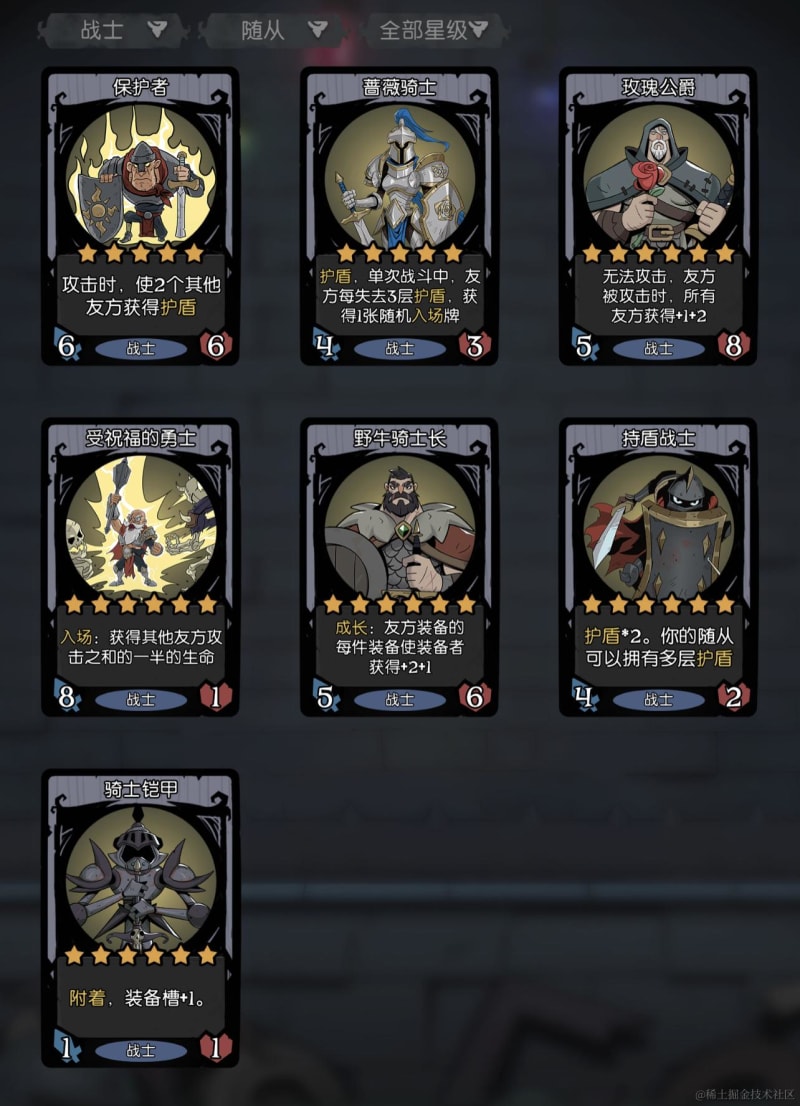 |
Objective of the Machine Vision Section: To record the information of minion cards in the game into the database through the identification of game screenshots.
Given the numerous minions in the game (202 in total), in order to analyze the compatibility between minions at a glance, we need a more intuitive and convenient method for data filtering and presentation.
To achieve this goal, let's first organize the general approach and steps:
- Identify the cards in the image.
- Recognize the text information on the cards.
- Enter into the database after removing duplicates. We will gradually discuss the technical means and open-source libraries that will be used in this process later on.
To enhance the reading experience, the code snippets in this document are provided as essential feature examples, omitting relatively complex logic and conditionals that might be present in your actual project.
The code is intended for reference and learning purposes; you may need to make adjustments according to your specific business requirements in your project.
1.Identify the cards in the image

For humans, what a playing card is may be quite clear, but how can we make a computer understand what a playing card is?
Of course, we start by providing a clear definition:
A playing card is a rectangular flat object with patterns, numbers, text, or symbols on it.
Next, we need to instruct the computer to identify these playing cards from images. Here's the general approach:
- Load the image.
- Convert the image to grayscale.
- Perform Canny edge detection.
Here, we will primarily make use of the OpenCV library for image processing.
OpenCV (Open Source Computer Vision Library) is an open-source computer vision library that provides a vast array of tools, algorithms, and functions for image and video processing. Originally developed by Intel, it is released under a BSD license and is free to use in both commercial and research applications. This library aims to make computer vision tasks more accessible and finds wide applications in various fields, including machine learning, image processing, computer vision research, industrial automation, and embedded systems.
import cv2
# Load the image
img = cv2.imread('images/01.jpg')
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# Apply object detection
edges = cv2.Canny(img_gray, threshold1=30, threshold2=100)
# Find contours
contours, hierarchy = cv2.findContours(edges.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)

From the image above, it's apparent that we have identified some contours. However, there is an issue where information at the top, such as the race, card type, and card level, has also been detected by the edge detection. This clearly does not meet our expectations. Therefore, we are redefining the concept of a card and improving this by excluding contours that are too small.
A playing card is a rectangular flat object with patterns, numbers, text, or symbols on it.
Minimum area of 36,000 square pixels (>=150x240).
import cv2
# Load the image
img_path = 'images/01.jpg'
img = cv2.imread(img_path)
if img is None:
print("Image load failed!")
exit(0)
# Convert the image to RGB before displaying
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# Find contours
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
edges = cv2.Canny(img_gray, threshold1=30, threshold2=100)
contours, hierarcy = cv2.findContours(edges.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# Filter out small contours based on the area[HA]
min_contour_area = 36000
large_contours = [cnt for cnt in contours if cv2.contourArea(cnt) > min_contour_area]
# Draw contours and label them
img_contours = img_rgb.copy()
for i, contour in enumerate(large_contours):
# Get the bounding box of the contour
x, y, w, h = cv2.boundingRect(contour)
# Draw the contour and label it
cv2.rectangle(img_contours, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.putText(img_contours, str(i + 1), (x, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 255), 2)
# Display the image with contours and labels
cv2.imshow('Contours', img_contours)
cv2.waitKey(0)
Let's take a look at the results[HA]:
| What we see | What the computer sees |
|---|---|
 |
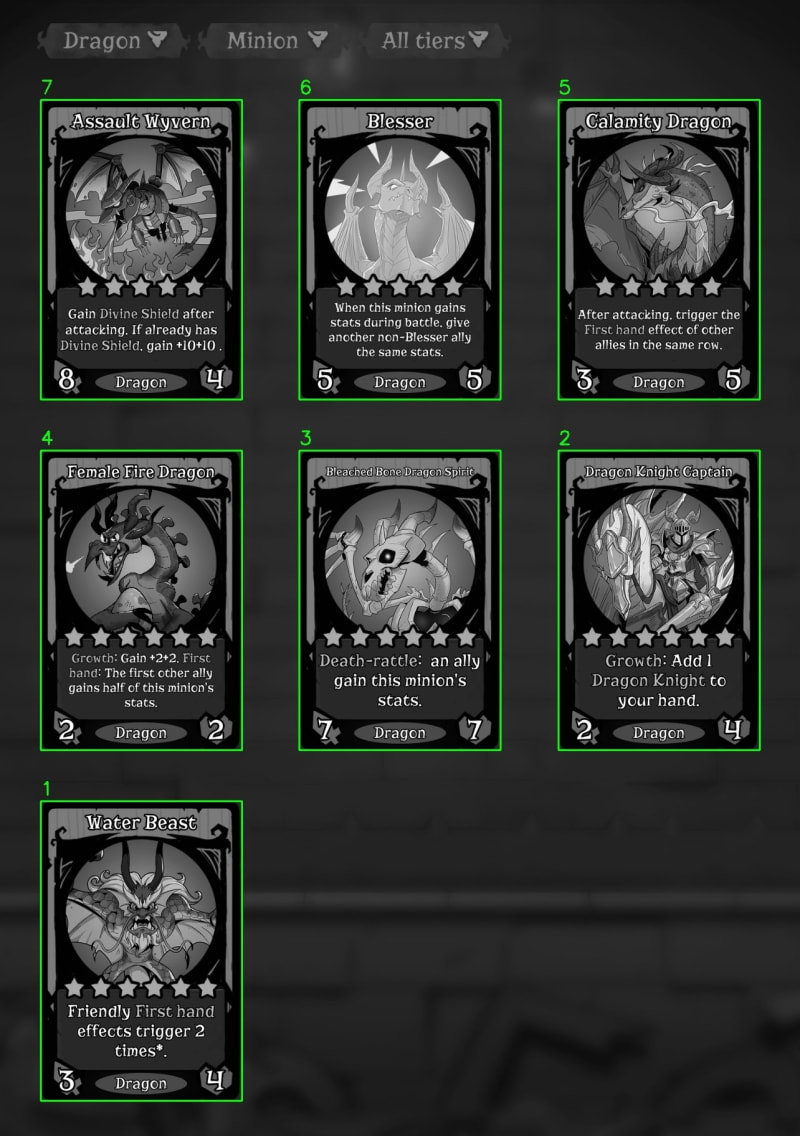 |
In the code, we performed color conversion with the goal of reducing information interference when detecting edges. Here is a brief overview of the purposes of different color conversions:
-
Grayscale Image:
- Reduced Computational Complexity: When your task involves image processing or analysis without the need for color information, converting the image to grayscale can reduce computational complexity. Grayscale images contain only brightness information, omitting color.
- Feature Extraction: In some computer vision tasks like face detection or object recognition, grayscale images are often sufficient for extracting essential features because color information may not be critical.
-
RGB Image:
- Color-Related Tasks: If your task involves color information, such as color being an important feature in image classification, you should retain the color information in RGB (Red, Green, Blue) images.
- Segmentation Tasks: RGB images are generally more useful in image segmentation tasks because color can help distinguish different objects or regions.
-
Other Color Spaces:
- HSV (Hue, Saturation, Value) Space: The HSV color space is commonly used for color analysis and processing because it more intuitively represents color attributes. It may be more useful for certain color-related tasks.
- Lab (L*, a*, b*) Space: Lab color space is often used for color-related tasks and image analysis because it separates brightness information (L channel) from color information (a and b channels), making color processing easier.
These color conversions are chosen based on the specific requirements of your computer vision task and whether color information is essential for achieving your goals.
Posted on September 16, 2023
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related



