Voxel51 Filtered Views Newsletter - March 29, 2024

Jimmy Guerrero
Posted on March 29, 2024

Author: Harpreet Sahota (Hacker in Residence at Voxel51)
Welcome to Voxel51's bi-weekly digest of the latest trending AI, machine learning and computer vision news, events and resources! Subscribe to the email version.
📰 The Industry Pulse
Ubisoft's new gaming NPC
🎮Ubisoft has introduced "neo NPCs" like Bloom, a new breed of gaming NPC designed to have meaningful conversations with players, thanks to the power of generative AI. This development represents a significant step forward in making game worlds more interactive and engaging. The Game Developers Conference highlighted the growing interest in AI across the gaming industry. Ubisoft's approach to designing NPCs like Bloom encourages players to use their social instincts within the game, making the gaming experience more personal and relatable. The possibilities are endless; what kind of character would you want to have a conversation within your favorite game?
Apple's move into GenAI
🍎 Apple is expected to address its approach to generative AI at the upcoming Worldwide Developers Conference (WWDC), which has led to widespread speculation and anticipation. The company has reportedly invested heavily in training its AI models and is exploring various avenues, including potential content partnerships and collaborations with leading AI entities. This move marks a significant shift in Apple's technological strategy, which has historically focused on on-device machine learning. We’ll soon see how Apple’s strategic moves in AI will reshape the competitive landscape and influence the future of consumer technology.
Suno's AI blues
🎷 The song "Soul Of The Machine" by an AI music generation startup called Suno attempts to mimic the soulful essence of Mississippi Delta Blues with an AI singing about its sadness. However, the reception among musicians reveals AI's nuanced challenges in replicating the human touch in music. While showcasing AI's ability to generate music that fits within a specific genre, the song lacks the emotional depth and nuanced understanding of rhythm and tension that human musicians bring to their performances. The article also highlights the irreplaceable value of live music, emphasizing the dynamic interaction between performers and their audience that is currently beyond AI's reach.
👨🏽💻 GitHub Gems
New LLaVA release
LLaVA-NeXT (aka LLaVA-1.6) is here! The improved version of the LLaVA (Large Language and Vision Assistant) model, which is an open-source multimodal AI assistant capable of processing both text and images, boasts enhanced reasoning, optical character recognition (OCR), and world knowledge capabilities.
Here are the key improvements in LLaVA-NeXT compared to the previous LLaVA-1.5 version:
According to the authors, on several benchmarks, LLaVA-NeXT-34B outperforms Gemini Pro, a state-of-the-art multimodal model. It achieves state-of-the-art performance across 11 benchmarks with simple modifications to the original LLaVA model.
The authors curated high-quality user instruction data that meets two criteria: diverse task instructions and superior responses. They combined two data sources for this: (1) Existing GPT-V data in LAION-GPT-V and ShareGPT-4V. (2) A 15K visual instruction tuning dataset from the LLaVA demo covering various applications. They also filtered potentially harmful or privacy-sensitive samples and generated responses with GPT-4V.
Major improvements include enhanced reasoning capabilities, optical character recognition (OCR), and world knowledge compared to the previous LLaVA-1.5 model.
LLaVA-NeXT has an emerging zero-shot capability in Chinese despite only being trained on English multimodal data. Its Chinese multimodal performance is surprisingly good.
The model is compute and data efficient. LLaVA-NeXT-34B was trained with 32 GPUs for about 1 day using only 1.3 million data samples. This compute and data cost is 100-1000x lower than other models.
In qualitative tests, LLaVA-NeXT-34B demonstrated strong visual comprehension and question-answering abilities on images, such as identifying people and understanding context from social media screenshots.
LLaVA-NeXT has been open-sourced and is available in the Hugging Face Transformers library, making it one of the best open-source vision-language models currently available.
LLaVA-NeXT is a massive advancement in open-source multimodal AI making powerful visual-language capabilities more widely accessible to researchers and developers
Get hands-on with the model and see it in action yourself with this Colab notebook we created for you!
📙 Good Reads
Multimodality and Large Multimodal Models (LMMs)
Think about how you experience the world: you see, hear, touch, and talk.
As a human, you have the uncanny ability to process and interact with the world using multiple modes of data simultaneously. You can output data in various ways, whether speaking, writing, typing, drawing, singing, or more. Developing AI systems that can operate in the "real world" means building models that understand the world as you do. It requires models that can take in multiple input types, reason over that input, and generate output across different modalities.
This week's blog pick is one from Chip Huyen, who examined large multimodal models (LMMs) in depth.
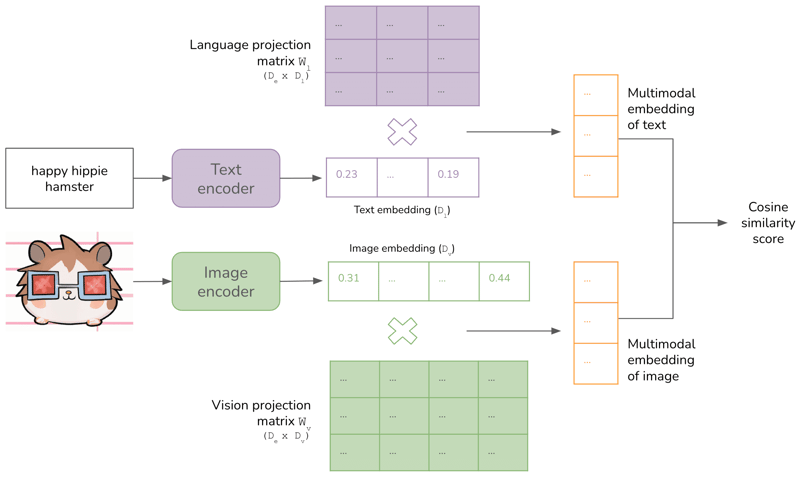
Chip's blog post discusses the latest advancements in training multimodal models. It’s split into three parts:
Understanding Multimodal: This section discusses the context of multimodality, including its importance, different data modalities, and types of multimodal tasks. It emphasizes the significance of working with images and text to generate content and a more comprehensive understanding.
Multimodal Training: This part discusses training a multimodal system, using CLIP and Flamingo as examples. It covers the components of a multimodal system, including encoders for each data modality, alignment of embeddings, and, for generative models, a language model to generate text responses.
Research Directions for LMMs: The final section discusses active research areas for LMMs, such as generating multimodal outputs, incorporating more data modalities, and creating adapters for more efficient multimodal training.
It's a long read, but it's time well spent. I highly recommend checking it out. My main takeaways are summarized below.
The Essence of Multimodality
Chip outlines that multimodality involves interactions between different data types, including text, images, audio, etc. She mentions that it can mean one or more of the following:
Multiple Input and Output Modalities: A model could input text and output an image, or vice versa. This versatility allows AI systems to engage in more complex tasks, such as generating descriptive text from an image (image captioning) or creating a visual representation based on a textual description.
Multimodal Inputs: An example would be an AI system that can analyze and understand content that includes images, text, or audio to make decisions or provide insights. This approach requires a comprehensive understanding of different data types to accurately interpret the context or content, such as sentiment analysis across text and image data.
Multimodal Outputs: This could involve an AI system that, given a specific input, can produce a textual summary and a relevant image or graphical representation. This capability enhances user interactions and provides more dynamic and informative responses in applications like educational tools or content creation platforms.
Data Modalities
Data modalities refer to the different forms of data, such as text, images, audio, tabular data, etc. Understanding and working with multiple data modalities is crucial for AI systems to operate effectively in the real world, mirroring human intelligence's multimodal nature.
-
One highlighted aspect is the ability to represent or approximate one data modality in terms of another. For example:
- Audio can be visualized as images through mel spectrograms.
- Speech can be transcribed into text, albeit losing some nuances like intonation and volume.
- Images can be converted into vectors and then represented as sequences of text tokens.
- Videos are treated as sequences of images, sometimes along with the audio.
- Text can be visualized by taking a picture of it.
- Data tables can be transformed into charts or images.
Images are versatile modality for model inputs. They can represent other data types; visual data are abundant from sources like phones and webcams.
Conversely, the text is highlighted as a powerful output modality because of its applicability across various tasks, including summarization, translation, reasoning, and question-answering.
While there is a breadth of data modalities, images and text have widespread applicability, and the existing research and development efforts are centred around these modalities.
Chip Huyen's exploration into multimodality and LMMs offers an excellent overview of the topic, a thorough explanation of groundbreaking models like CLIP and Flamingo, plus a compelling glimpse into the future of AI, where the integration of diverse data types promises to unlock new levels of intelligence and utility.
🎙️ Good Listens
Kate Park has made massive contributions to the development of data engines.
Her journey began at Tesla, where she played a crucial role in enhancing their Autopilot system. She then continued her work at Scale AI, focusing on natural language processing (NLP) systems. Park's pioneering work at Tesla involved leveraging data engines to enhance Tesla Autopilot's capabilities. She emphasized that the key to achieving advanced levels of autonomy lies in data, not just in quantity but quality.

In a conversation on The Gradient Podcast, she highlights the balance between data quantity, quality, and the efficient allocation of resources to maximize model performance improvements. This podcast episode is a masterclass on how data engines create a systematic approach to improving machine learning models through collecting and processing high-quality data.
Here are my main takeaways:
Data engines are a systematic approach to improving machine learning models. They involve a cycle where data collection and processing lead to model improvements. These improvements, in turn, enhance the system's ability to handle more edge cases, thereby significantly improving its overall performance.
Architectural improvements involve research and development of new model structures, which can have more uncertain outcomes. Data engines focus on deterministic model improvement through data collection and processing, independent of architectural changes.
Value of Data Scaling Experiments. Kate emphasizes observing the correlation between the amount of data added over time and the resultant performance improvements in AI models.
Performance improvements may not always follow a linear trend and might plateau after a certain point. However, adding more data is justified if performance improves with reasonable effort. When the performance bar is surpassed, or the gains from additional data diminish significantly, the focus shifts from adding more data to perhaps looking at architectural improvements or other areas.
Kate advocates for a scientific approach to data scaling, where empirical evidence guides development. The challenge, however, lies in estimating the initial amount of data required to solve a problem—a process she refers to as the "black magic" part of the data engine.
Data Engines and GenAI
The data required for LLMs and generative AI is highly specialized and expertise-focused. Unlike in computer vision, where a broader range of labelers might suffice, LLMs require data generation from individuals with specific domain knowledge.
A diverse array of experts is needed. For instance, math experts are needed for mathematical content, coding experts for programming-related queries, and legal experts for legal advice. This diversity necessitates recruiting people from various fields, each with specialized knowledge.
The challenge is that a single labeler typically cannot cover more than a few domains, making it impractical to rely on a generalist approach to data labeling for tasks requiring deep domain knowledge.
Addressing these challenges requires building an extensive network of experts eager to contribute to supervising and improving models. This network functions beyond the capacity of having a fixed in-house team of labelers capable of handling diverse tasks.
Continuous model improvement demands a dynamic approach to recruiting experts from niche domains. As models evolve and new application areas emerge, the pool of required expertise will also need to adapt and expand.
Kate suggests the solution is creating a "white-collar gig community." This concept envisions a new form of engagement where professionals contribute their expertise on a gig basis, akin to a more specialized form of crowd-sourcing, focusing on high-level knowledge work.
Beyond the key takeaways highlighted, Kate shares insight into the practical application and impact of data engines from her experience within the industry. She offers invaluable insights from her time at Tesla and Scale AI, detailing the data engines' role in autonomous driving and natural language processing domains.
👨🏽🔬 Good Research

How to Read Conference Papers
Prof Jason Corso published a blog post about how to read research papers a while back. His PACES (problem, approach, claim, evaluation, substantiation) method has been my go-to for understanding papers.
The Role of Data Curation in Image Captioning
This week, I’ll apply his methodology to "The Role of Data Curation in Image Captioning" by Wenyan Li, Jonas F. Lotz, Chen Qiu, and Desmond Elliott.
Problem
Image captioning models are typically trained by treating all samples equally, ignoring variations in captions or the presence of mismatched or hard-to-caption data points. This negatively impacts a model's ability to generate captions accurately because it can "confuse" the model during training. This paper investigates whether actively curating difficult samples within datasets can enhance model performance without increasing the total number of samples.
Approach
The paper introduces three data curation methods to improve image captioning models by actively curating difficult samples within the dataset. These methods are:
REMOVAL: Completely removing high-loss samples from the training process.
REPLACECAP: Replacing the caption of a high-loss sample with another caption from the dataset or a caption generated by a language model.
REPLACEIMG: A text-to-image generation model replaces the image of a high-loss sample with a newly synthesized image based on its captions.
Claim
The authors claim that actively curating difficult samples in datasets, without increasing the total number of samples, enhances image captioning performance through three data curation methods: complete removal of a sample, caption replacement, or image replacement via a text-to-image generation model.
Their experiments show that the best strategy varies between datasets but is generalizable across different vision-language models.
Evaluation
The methods were evaluated with two state-of-the-art pretrained vision-language models (BLIP and BEiT-3) on widely used datasets (MS COCO and Flickr30K), focusing on how these curation methods impact the performance of image captioning models. They used metrics like CIDEr and BLEU scores to measure improvements.
The study finds that Flickr30K benefits more from removing high-loss training samples, suggesting it may be noisier than MS COCO.
Substantiation
The study discovered that:
A hybrid approach combining REMOVAL and REPLACEIMG methods yielded the best results, suggesting that a sophisticated strategy leveraging multiple curation methods could offer more flexibility and effectiveness in curating datasets.
The extent of curation and the choice of method are critical and dataset-dependent, with some datasets benefiting more from certain curation strategies than others.
The potential of using synthesized images for training was acknowledged, although the quality of the generated images limited its benefits.
The findings underscore the importance of data curation in training more effective image captioning models and open up avenues for applying similar frameworks to other multimodal tasks.
🗓️. Upcoming Events
Check out these upcoming AI, machine learning and computer vision events! View the full calendar and register for an event.
Posted on March 29, 2024
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related


October 11, 2024


