Efficiently Managing and Querying Visual Data With MongoDB Atlas Vector Search and FiftyOne

Jimmy Guerrero
Posted on March 18, 2024

Author: Jacob Marks (Machine Learning Engineer at Voxel51)
Efficiently Managing and Querying Visual Data With MongoDB Atlas Vector Search and FiftyOne
The vast majority of the world’s data is unstructured, nestled within images, videos, audio files, and text. Whether you’re developing application-specific business solutions or trying to train a state-of-the-art machine learning model, understanding and extracting insights from unstructured data is more important than ever.
Without the right tools, interpreting features in unstructured data can feel like looking for a needle in a haystack. Fortunately, the integration between FiftyOne and MongoDB Atlas enables the processing and analysis of visual data with unparalleled efficiency!
In this post, we will show you how to use FiftyOne and MongoDB Atlas Vector Search to streamline your data-centric workflows and interact with your visual data like never before.
What is FiftyOne?
FiftyOne is the leading open-source toolkit for the curation and visualization of unstructured data, built on top of MongoDB. It leverages the non-relational nature of MongoDB to provide an intuitive interface for working with datasets consisting of images, videos, point clouds, PDFs, and more.
You can install FiftyOne from PyPi:
pip install fiftyone
The core data structure in FiftyOne is the Dataset, which consists of samples — collections of labels, metadata, and other attributes associated with a media file. You can access, query, and run computations on this data either programmatically, with the FiftyOne Python software development kit, or visually via the FiftyOne App.
As an illustrative example, we’ll be working with the Quickstart dataset, which we can load from the FiftyOne Dataset Zoo:
import fiftyone as fo
import fiftyone.zoo as foz
## load dataset from zoo
dataset = foz.load_zoo_dataset("quickstart")
## launch the app
session = fo.launch_app(dataset)
💡It is also very easy to load in your data.
Once you have a fiftyone.Dataset instance, you can create a view into your dataset (DatasetView) by applying view stages. These view stages allow you to perform common operations like filtering, matching, sorting, and selecting by using arbitrary attributes on your samples.
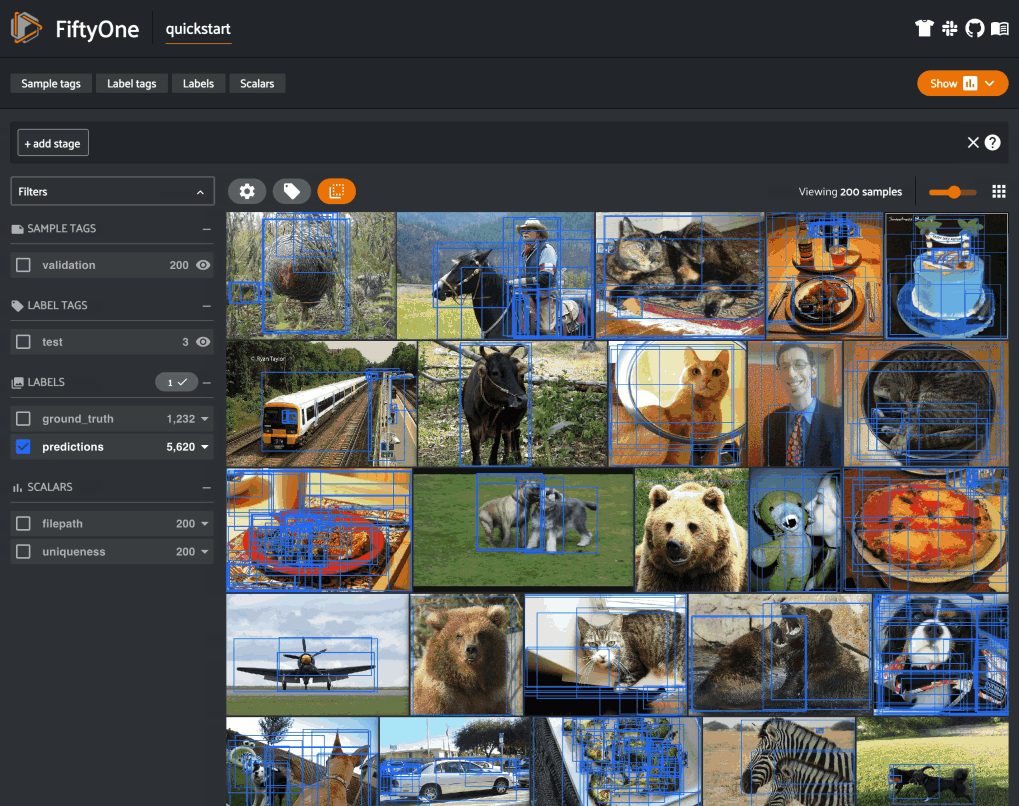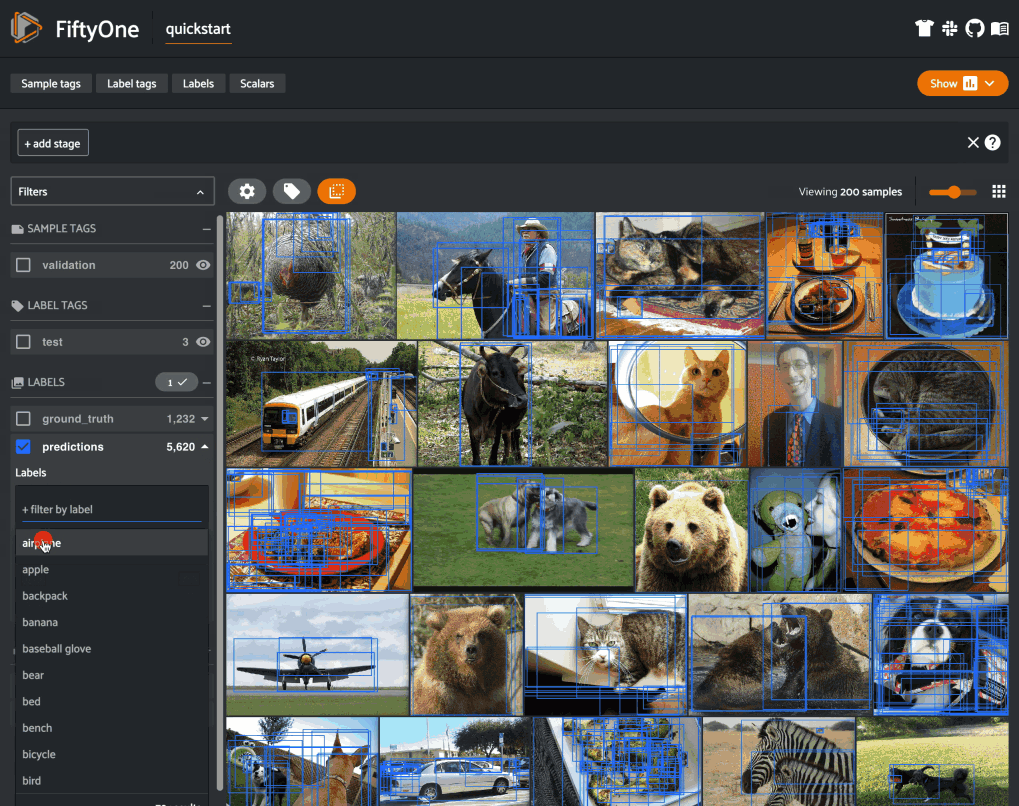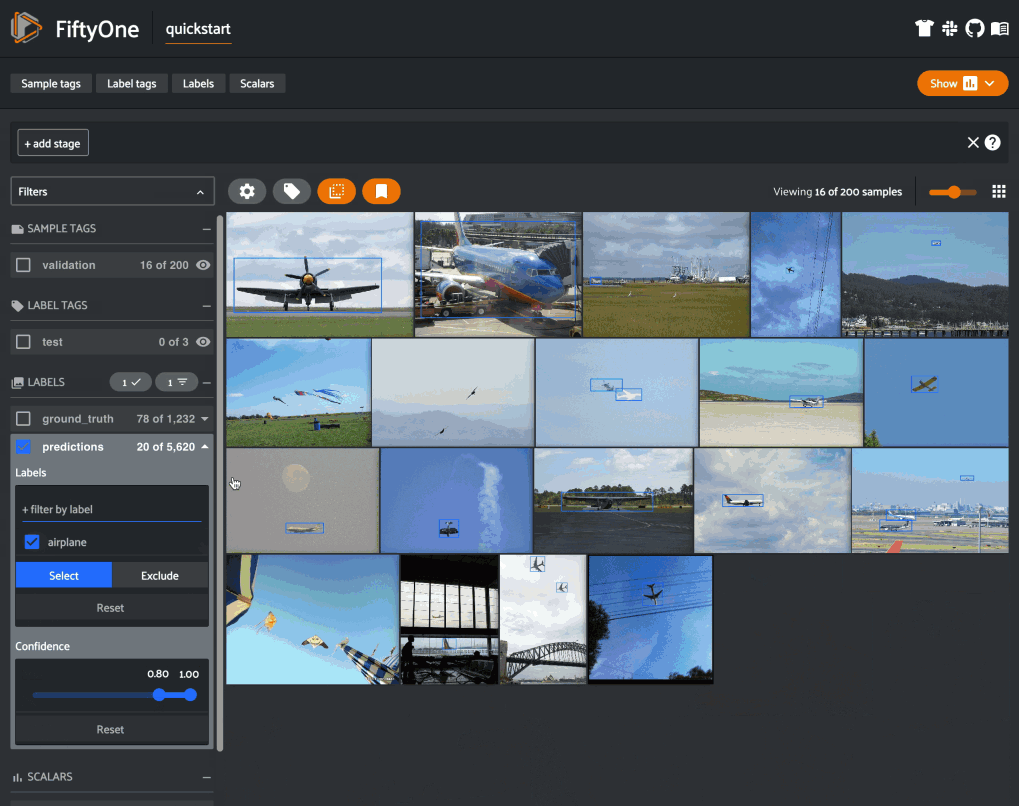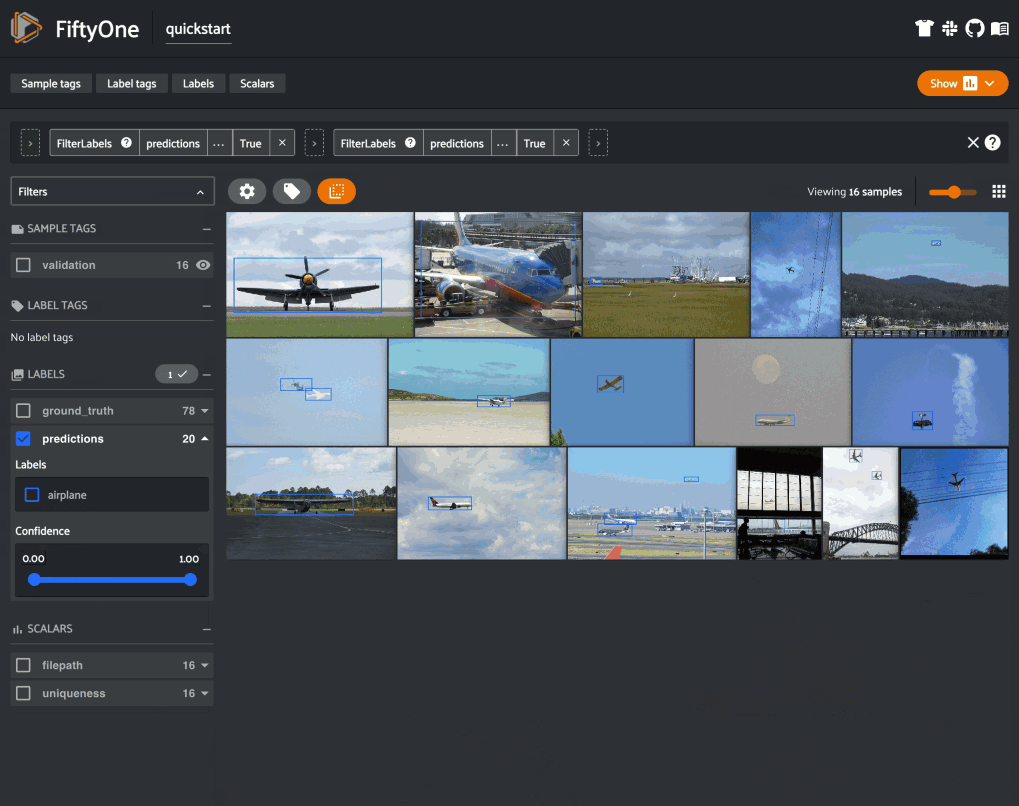
To programmatically isolate all high-confidence predictions of an airplane, for instance, we could run:
from fiftyone import ViewField as F
view = dataset.filter_labels(
"predictions",
(F("label") == "airplane") & (F("confidence") > 0.8)
)
Note that this achieves the same result as the UI-based filtering in the last GIF.
This querying functionality is incredibly powerful. For a full list of supported view stages, check out this View Stages cheat sheet. What’s more, these operations readily scale to billions of samples. How? Simply put, they are built on MongoDB aggregation pipelines!
When you print out the DatasetView, you can see a summary of the applied aggregation under “View stages”:
# view the dataset and summary
print(view)
Dataset: quickstart
Media type: image
Num samples: 14
Sample fields:
id: fiftyone.core.fields.ObjectIdField
filepath: fiftyone.core.fields.StringField
tags: fiftyone.core.fields.ListField(fiftyone.core.fields.StringField)
metadata: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.metadata.ImageMetadata)
ground_truth: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.labels.Detections)
uniqueness: fiftyone.core.fields.FloatField
predictions: fiftyone.core.fields.EmbeddedDocumentField(fiftyone.core.labels.Detections)
View stages:
1. FilterLabels(field='predictions', filter={'$and': [{...}, {...}]}, only_matches=True, trajectories=False)
We can explicitly obtain the MongoDB aggregation pipeline when we create directly with the _pipeline() method:
## Inspect the MongoDB agg pipeline
print(view._pipeline())
[{'$addFields': {'predictions.detections': {'$filter': {'input': '$predictions.detections',
'cond': {'$and': [{'$eq': ['$$this.label', 'airplane']},
{'$gt': ['$$this.confidence', 0.8]}]}}}}},
{'$match': {'$expr': {'$gt': [{'$size': {'$ifNull': ['$predictions.detections',
[]]}},
0]}}}]
You can also inspect the underlying MongoDB document for a sample with the to_mongo() method.
You can even create a DatasetView by applying a MongoDB aggregation pipeline directly to your dataset using the Mongo view stage and the add_stage() method:
# Sort by the number of objects in the `ground_truth` field
stage = fo.Mongo([
{
"$addFields": {
"_sort_field": {
"$size": {"$ifNull": ["$ground_truth.detections", []]}
}
}
},
{"$sort": {"_sort_field": -1}},
{"$project": {"_sort_field": False}},
])
view = dataset.add_stage(stage)
Vector Search With FiftyOne and MongoDB Atlas
Vector search is a technique for indexing unstructured data like text and images by representing them with high-dimensional numerical vectors called embeddings, generated from a machine learning model. This makes the unstructured data searchable, as inputs can be compared and assigned similarity scores based on the alignment between their embedding vectors. The indexing and searching of these vectors are efficiently performed by purpose-built vector databases like MongoDB Atlas Vector Search.
Vector search is an essential ingredient in retrieval-augmented generation (RAG) pipelines for LLMs. Additionally, it enables a plethora of visual and multimodal applications in data understanding, like finding similar images, searching for objects within your images, and even semantically searching your visual data using natural language.
Now, with the integration between FiftyOne and MongoDB Atlas, it is easier than ever to apply vector search to your visual data! When you use FiftyOne and MongoDB Atlas, your traditional queries and vector search queries are connected by the same underlying data infrastructure. This streamlines development, leaving you with fewer services to manage and less time spent on tedious ETL tasks. Just as importantly, when you mix and match traditional queries with vector search queries, MongoDB can optimize efficiency over the entire aggregation pipeline.
Connecting FiftyOne and MongoDB Atlas
To get started, first configure a MongoDB Atlas cluster:
export FIFTYONE_DATABASE_NAME=fiftyone
export FIFTYONE_DATABASE_URI='mongodb+srv://$USERNAME:$PASSWORD@fiftyone.XXXXXX.mongodb.net/?retryWrites=true&w=majority'
Then, set MongoDB Atlas as your default vector search back end:
export FIFTYONE_BRAIN_DEFAULT_SIMILARITY_BACKEND=mongodb
Generating the similarity index
You can then create a similarity index on your dataset (or dataset view) by using the FiftyOne Brain’s compute_similarity() method. To do so, you can provide any of the following:
- An array of embeddings for your samples
- The name of a field on your samples containing embeddings
- The name of a model from the FiftyOne Model Zoo (CLIP, OpenCLIP, DINOv2, etc.), to use to generate embeddings
- A
fiftyone.Modelinstance to use to generate embeddings - A Hugging Face transformers model to use to generate embeddings
For more information on these options, check out the documentation for compute_similarity().
import fiftyone.brain as fob
fob.compute_similarity(
dataset,
model="clip-vit-base32-torch", ### Use a CLIP model
brain_key="your_key",
embeddings='clip_embeddings',
)
When you generate the similarity index, you can also pass in configuration parameters for the MongoDB Atlas Vector Search index: the index_name and what metric to use to measure similarity between vectors.
Sorting by Similarity
Once you have run compute_similarity() to generate the index, you can sort by similarity using the MongoDB Atlas Vector Search engine with the sort_by_similarity() view stage. In Python, you can specify the sample (whose image) you want to find the most similar images to by passing in the ID of the sample:
## get ID of third sample
query = dataset.skip(2).first().id
## get 25 most similar images
view = dataset.sort_by_similarity(query, k=25, brain_key="your_key")
session = fo.launch_app(view)
If you only have one similarity index on your dataset, you don’t need to specify the brain_key.
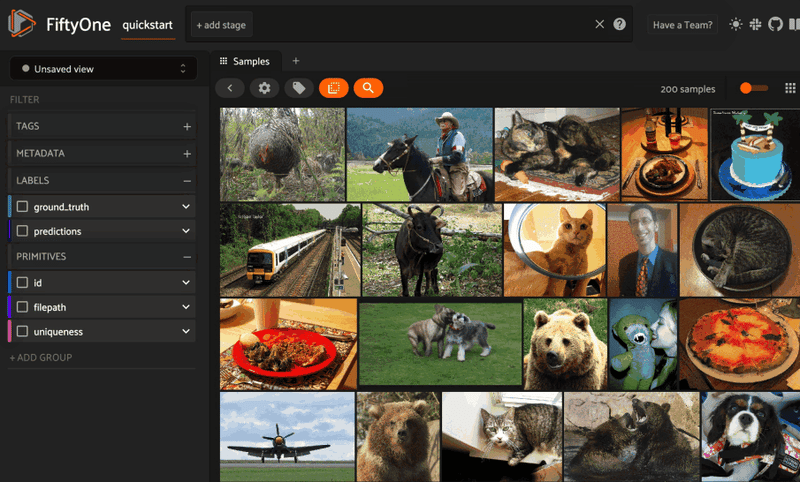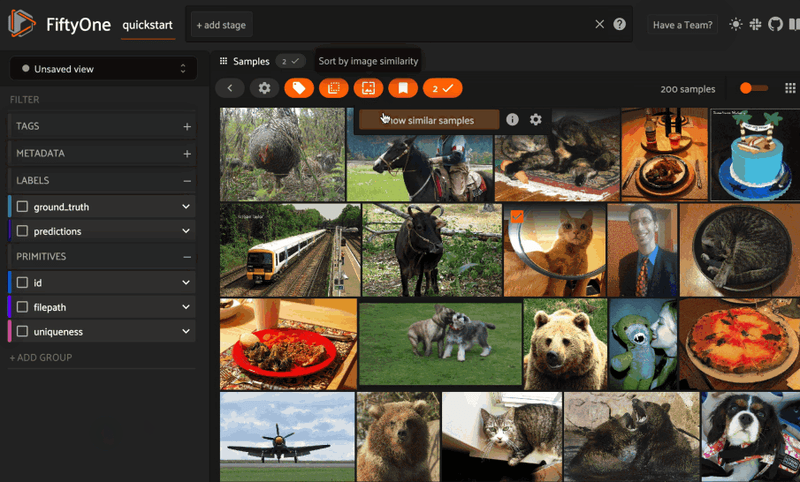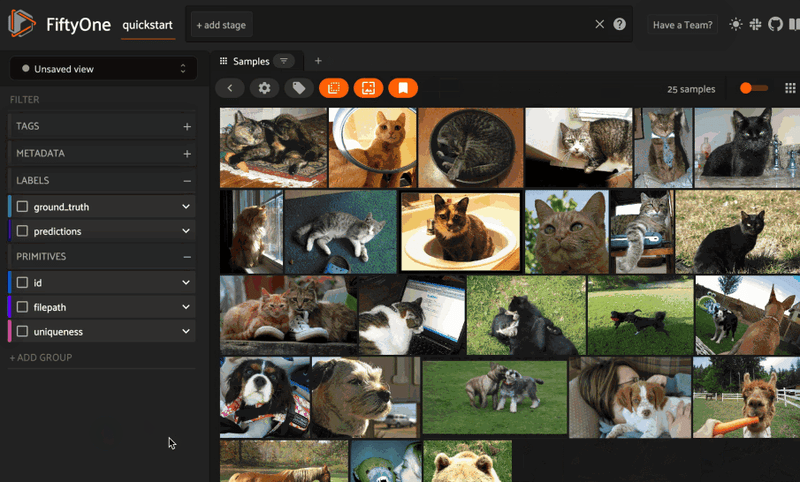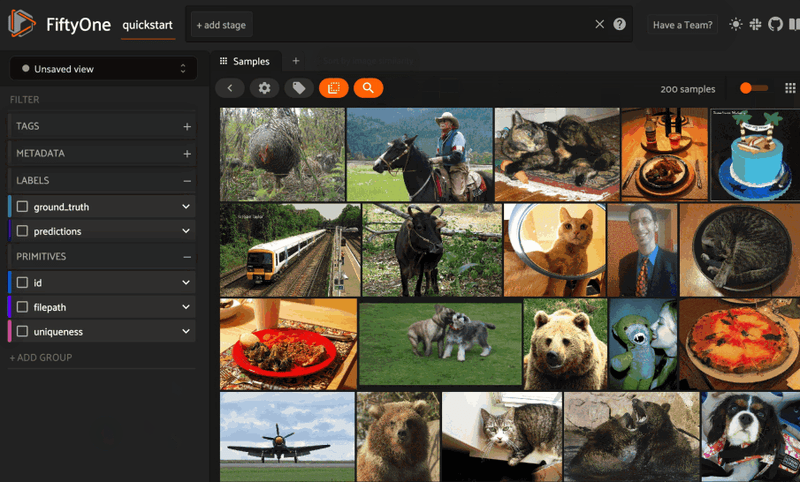
We can achieve the same result with UI alone by selecting an image and then pressing the button with the image icon in the menu bar:
The coolest part is that sort_by_similarity() can be interleaved with other view stages — no need to write custom pre- and post-processing scripts. Keep everything in the same query language and underlying data model. Here’s a simple example, just to get the point across:
query = dataset.first().id
# shuffle,
# then vector search against 1st sample,
# finally skip top 5 restuls
view = dataset.sort_by_similarity(query, k = 20).skip(5)
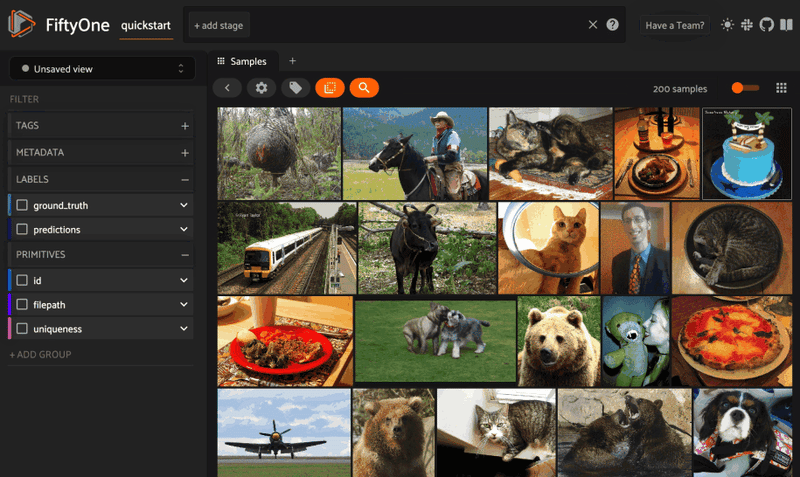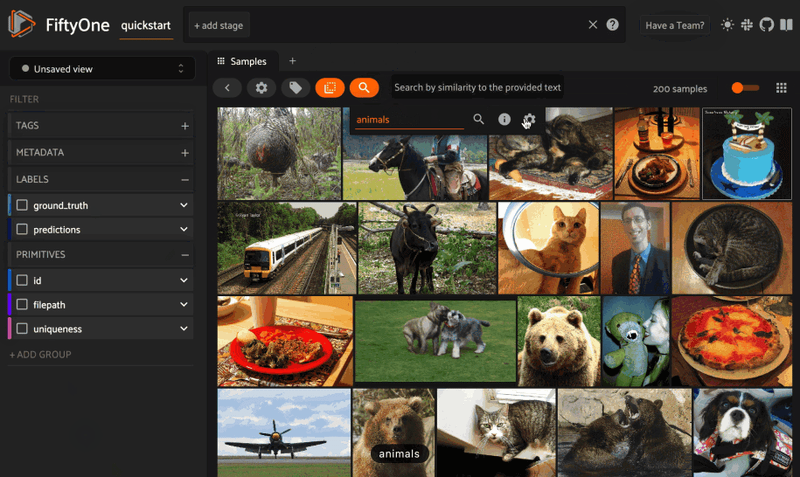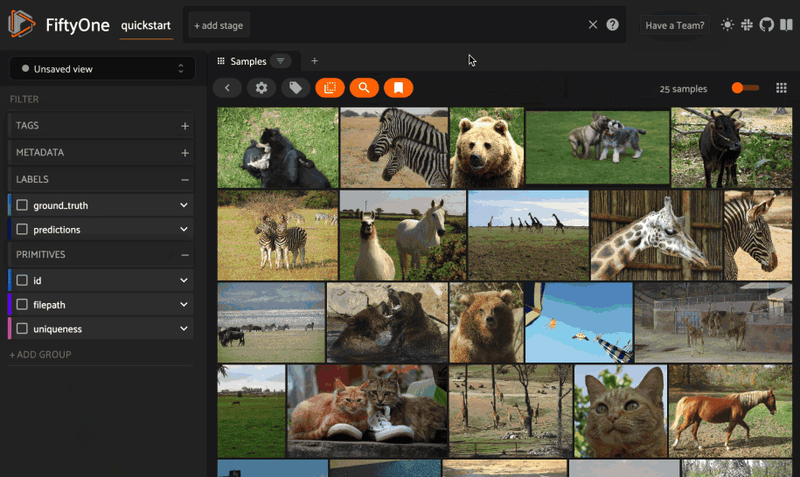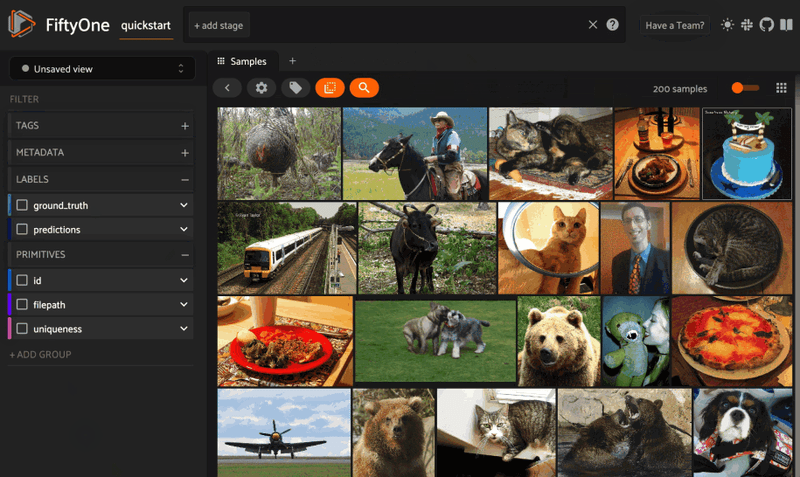
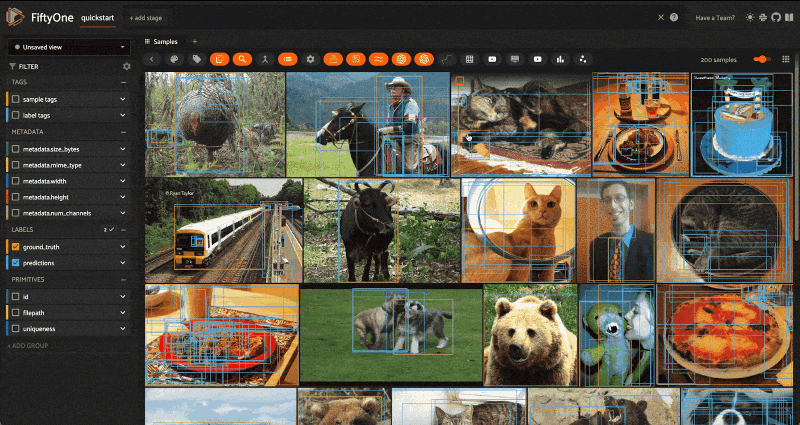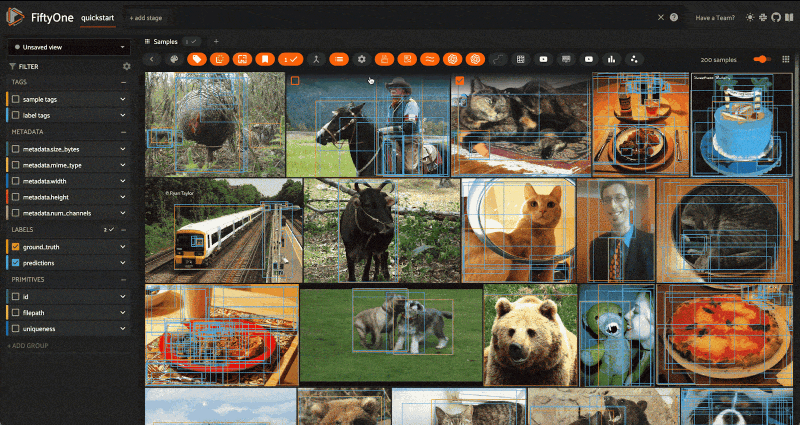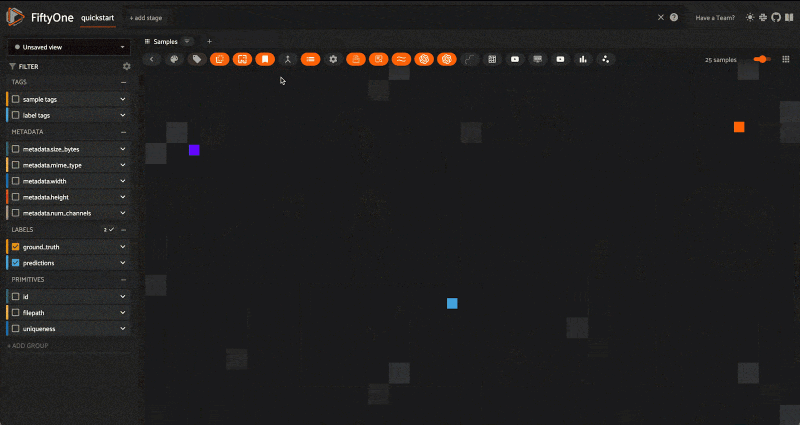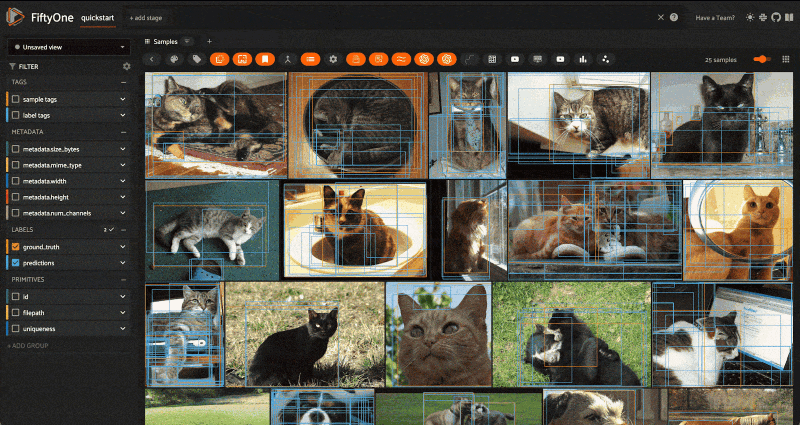
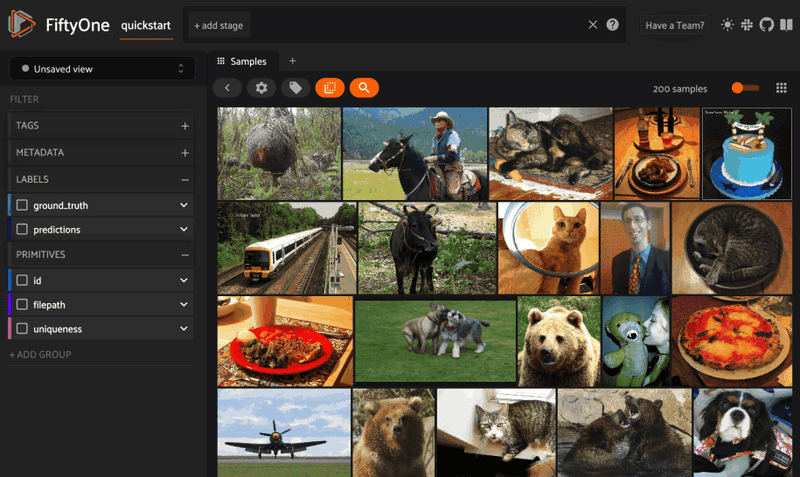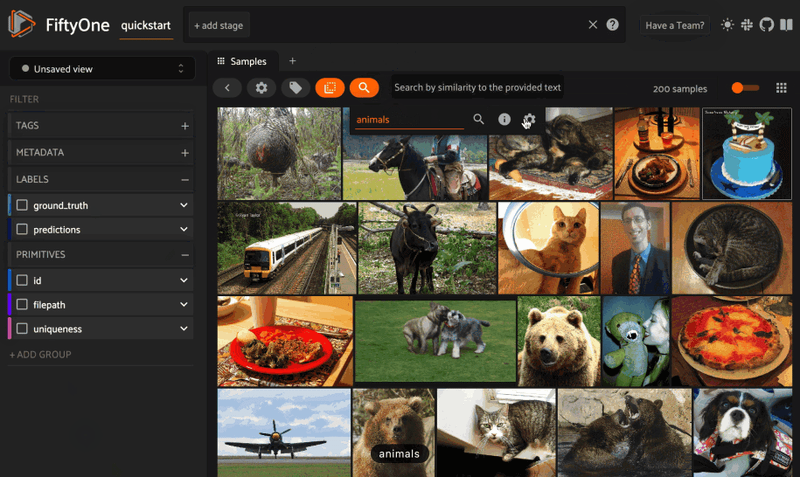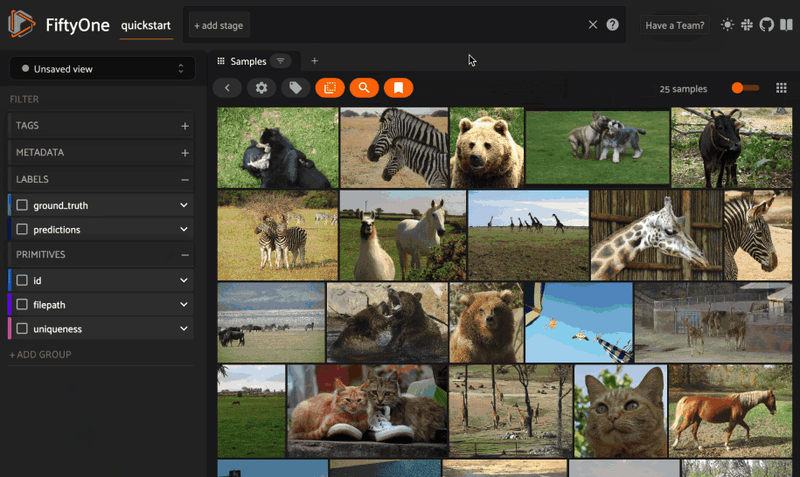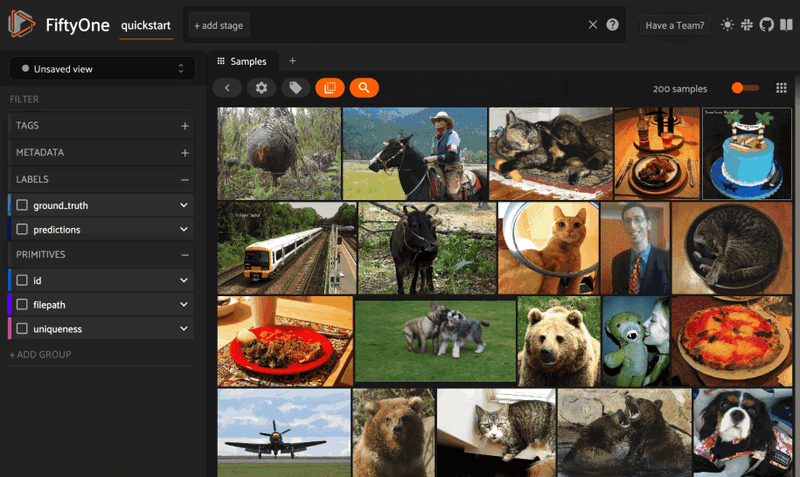
But wait, there’s so much more! The FiftyOne and MongoDB Atlas Vector Search integration also natively supports semantically searching your data with natural language queries. As long as the model you specify can embed both text and images — think CLIP, OpenCLIP models, and any of the zero-shot classification or detection models from Hugging Face’s transformers library — you can pass a string in as a query:
query = "animals"
view = dataset.sort_by_similarity(query, k = 25)
session = fo.launch_app(view)
Or in the FiftyOne App via the button with the magnifying glass icon:
Conclusion
Filtering, querying, and visualizing your unstructured data doesn’t have to be hard.
Together, MongoDB and FiftyOne offer a flexible and powerful yet still remarkably simple and efficient way to get the most out of your visual data!
👋Try FiftyOne for free in your browser at try.fiftyone.ai!
Posted on March 18, 2024
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related


October 11, 2024


