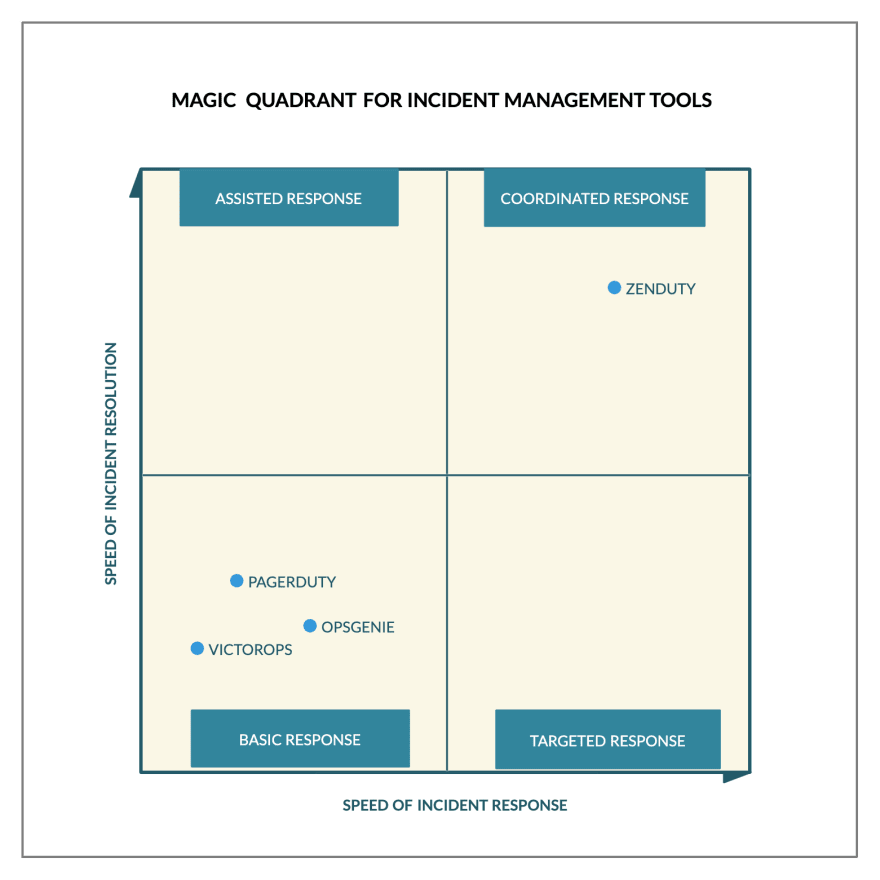
5 reasons why Zenduty is a great alternative to Opsgenie, Pagerduty, and VictorOps

Vishwa Krishnakumar
Posted on September 8, 2020
5 reasons why Zenduty is a great alternative to Opsgenie, Pagerduty, and VictorOps(O/P/V)
Reason 1: Zenduty’s Custom Routing Rule(s)!
Every integration(with a monitoring source) within O/P/V sends alerts according to a single escalation policy that is linked to that monitoring source(service), no matter what the nature of the alert is, what time of the day or week it is triggered, what the severity of the alert is, which component is affected.


For instance, if you have a Prometheus/Grafana monitoring system that is monitoring components built or maintained by multiple teams, and you integrate that alert source with O/P/V every alert generated by Prometheus will always go to the same escalation policy and alert to standard on-call rotations. If the on-call engineer does not have the expertise in dealing with the incident, he or she will have to bring in the team or the person that’s responsible for the component/service affected. While O/P/V might let you filter the alert, the custom actions are limited to suppressing the incident depending on the alert message.
But what if, depending on the alert data that the monitoring source sends, the alert also went to a specific team with the subject matter experts and the on-call engineer? Or what if the alert automatically bypassed the on-call engineer and went straight to the team?
Enter Zenduty’s Custom Routing Rules.

Payload Search — Every alert from a monitoring integration sends its own custom payload along with the alert parameters. For example, a critical alert from Jenkins will also contain a payload like — {“job”: “build-prod”, “job-number”:5, “status”: “SUCCESS”}. You can run a key search on the alert payload and use the above operators on the value
Incident Message and Incident Summary — Route if you find a keyword in the alert message or summary
Alert Time of the day — Route depending on the time of the day
Alert Day of the week — Route depending on the day of the week
Alert Date — Route if the incident falls on or between specific dates
Alert Type — Route depending on the type of the alert(critical, error, warning, acknowledged, resolved and info)
Following are the actions you can take if the alert routing conditions are met:
Suppress — Suppress the incident
Add Note — Automatically add a not to the resultant incident that will help the on-call engineers and incident commander to determine the RCA and triaging steps
Route to a custom Escalation Policy — Route to an escalation policy that is not the default on the service affected. This may be useful in cases where you might need a more aggressive or less aggressive escalation depending on the type of alert that has come in.
Assign to a specific user — Assign the incident to a specific user. This is useful where a known component is affected and the fastest way to resolve the incident is by assigning it to a known subject matter expert
Change Incident Urgency — change the urgency of the incident. If the alert creates a low priority incident and your conditions detect a potentially high priority incident, you can conditionally change the priority to high and vice-versa.
Change Alert Message — create your own custom Incident Title from the alert payload
Change Alert Summary — create your own custom Incident Summary from the alert payload
Change Alert Entity ID — change the alert entity_id to implement custom deduplication
Assign Role to User — after the alert creates an incident, assign a particular role to a particular user
Assign incident tag — automatically add a tag to the newly created incident depending on the matching condition. For example, if a backend component is affected, add a tag “backend”
Add incident task and template(coming soon) — Automatically add an incident task template or a task to the incident
The Zenduty Alert Rules allow you to fine-tune your incident alerting at many levels and make sure that the right team members are alerted when specific conditions are met, add notes and tags, route the incident alert to a different escalation policy than the service default policy, customize the incident title and summary, and most importantly suppress the incident.
Reason 2: Zenduty offers a solid and frictionless path to incident resolution
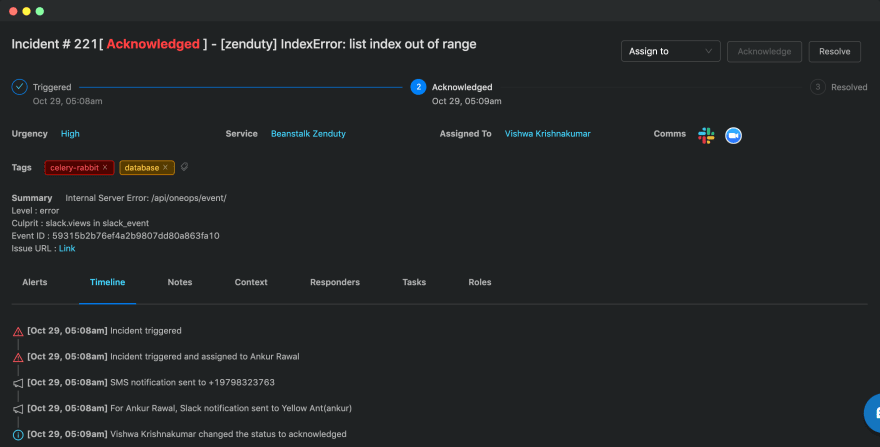
Every critical incident has four main stages: The detection, the alert, the response(triage->investigate->mitigate), and the postmortem. While Opsgenie/Pagerduty/VictorOps(O/P/V) have done a great job with incident alerting, escalations, and on-call scheduling, they never really focused on the incident response side of things. It is no wonder that 79%+ of SREs feel anxiety and stress during and after an incident. What do you do once you receiving that dreaded page? For one, you can stop dreading those pages by improving your preparedness and by having a solid incident response process in place.
Companies like Google, Dropbox, Slack, and Shopify have pioneered the incident response by borrowing best practices from the Incident Command System(ICS) developed by the US National Incident Management System(NIMS). Here’s a video featuring Honeycomb’s Liz Fong Jones and Google’s Seth Vargo explaining the ICS practiced at Google.
At Zenduty, we took a good look at the incident response best practices by the companies that we and the world admire for their reliability and brought those best practices into our product, which we collectively refer to as the Zenduty ICS.
There are four central pieces of the Zenduty ICS: Incident Roles, Tasks, Tags, and Task Templates. These four pieces combined will give anyone the entire high-level overview of the progress of any incident. Whenever an incident is triggered in Zenduty, the on-call engineer, after receiving the page, may acknowledge the incident and then claim the incident commander or ask someone else to take command. The incident commander will then add relevant responders, invite users to take up specific roles, assign tasks to those roles and update the incident status on the go.

Depending on your org structure and business, you can define roles like :
Incident Commander — leads the incident, and assigns roles and tasks to different people
Comms Lead — communicates about the incident to customers and stakeholders
Ops Lead — making changes and pushing the fix
Incident Tags
Incident tags let you classify the incident based on component, service, priority, customers or any other segment. These tags can then be used in your analytics dashboard to measure tag-wise service, team, and user performance.

Reason 3: Task Templates(Incident Playbooks)
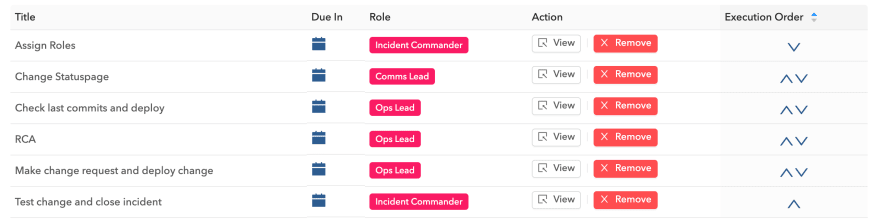
The task template is the starting point for any incident. In the task template, you can define standard operating procedures and point them to specific roles. When a particular service encounters an incident, the task from the task template will automatically be added to the incident task list and after the incident commander assigns roles to specific individuals, these individuals will automatically inherit the tasks in the incident. At any given point, anybody in the team or company will know exactly who is leading the incident and who is dealing with specific aspects of the incident.
Reason 4: End-to-end incident management in Slack and Teams
Zenduty’s Slack and Teams integrations/bots allow you to manage your incidents **end-to-end **from your favorite chat application. Track your incident tasks, assign roles, fetch alerts and context, add responders and ack/resolve incidents.



Reason 5: Fair and affordable pricing
At $0(Freemium), $5(Starter) and $15(Growth) per user per month, Zenduty is the most affordable alternative in the market. Zenduty offers you all the alerting capabilities offered by O/P/V in addition to powerful incident response capabilities. Compare with Pagerduty, Opsgenie, VictorOps
If you’re looking for an end-to-end incident management platform with awesome alert routing and response management capabilities, do give Zenduty a spin and leave us your feedback in the comments below.
And finally, be zen!
P.S: Check out the feature-wise comparison - Pagerduty, Opsgenie, VictorOps
Posted on September 8, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related



November 30, 2024
November 30, 2024