Scale your apps using KEDA in Kubernetes

Vinod Kumar
Posted on February 11, 2024
KEDA (or, Kubernetes Event-Driven Autoscaling) is a Kubernetes-based event-driven auto-scaler for Pods. With KEDA, we can scale out our application easily and then scale back to 0 which is not possible when it comes to the default HPA (Horizontal Pod Autoscaler) of Kubernetes. With HPA, we can only bring it down to 1 pod and not 0 with metric support of only CPU & Memory. Whereas, KEDA has a huge support of external metrics/services that can act as a source of events providing the event data to scale the apps. For instance, we can have KEDA Scalers like AWS SQS, Datadog, RabbitMQ, Kafka, CloudWatch, DynamoDB, Elasticsearch, etc.

The major advantage to go with KEDA over simple Kubernetes HPA are:-
- Supports multiple metrics/events for scaling
- Pods can be scaled down to Zero
Architecture:
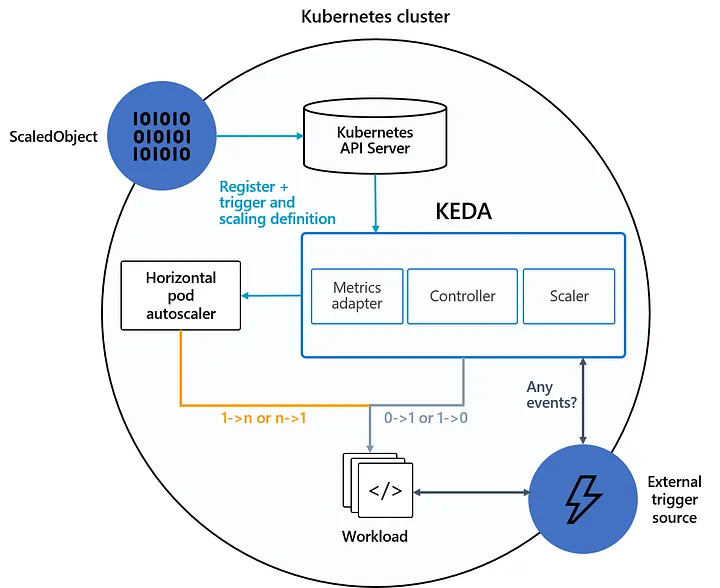
In this article, we will see how we can use KEDA to scale our application running in the AWS EKS (Elastic Kubernetes Service) based on the message received in the AWS SQS (Simple Queue Service).
Step 1: Create an EKS Cluster (optional, in case the cluster is not available)
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: eks-keda-test
region: us-east-2
version: '1.21'
managedNodeGroups:
- name: ng
instanceType: m4.xlarge
minSize: 1
maxSize: 2
Step 2: Install KEDA in Kubernetes using Helm
#Adding the Helm repo
helm repo add kedacore https://kedacore.github.io/charts
#Update the Helm repo
helm repo update
#Install Keda helm chart
kubectl create namespace keda
helm install keda kedacore/keda --namespace keda
Check if the KEDA Operators and Metric API Server is up or not in the KEDA namespace:-
kubectl get pod -n keda
NAME READY STATUS RESTARTS AGE
keda-operator-68cd48977c-swztq 1/1 Running 0 23h
keda-operator-metrics-apiserver-7d888bf9b5-s2fqs 1/1 Running 0 23h
Step 3: Deploy a test appliation in a Kubernetes cluster
Here, I’m running the nginx deployment with 1 replica
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: my-nginx
name: my-nginx
spec:
replicas: 1
selector:
matchLabels:
app: my-nginx
strategy: {}
template:
metadata:
labels:
app: my-nginx
spec:
containers:
- image: nginx
name: nginx
resources: {}
status: {}
Step 4: Create an AWS SQS Queue (Standard Queue)
Head to AWS Console -> AWS SQS and create a Standard Queue. Copy its region, Queue URL
Step 5: Create KEDA Scaler (SQS) using the ScaledObject
(Note, SQS-based KEDA Scaler for different types of integration of scaler (say CloudWatch, Datadog, etc), please refer to the official documentation here.)
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: aws-sqs-queue-scaledobject
namespace: default
spec:
scaleTargetRef:
name: my-nginx
pollingInterval: 5 #Interval for polling
cooldownPeriod: 10
idleReplicaCount: 0 # When idle, scale-in to 0 pods
minReplicaCount: 1
maxReplicaCount: 3
fallback: # Fallback strategy when metrics are unavailable for the apps
failureThreshold: 5 #when metrics are unavailable, match the desired state of replicas -> 2
replicas: 2 #Keep this desired state when metrics are unavailable
triggers:
- type: aws-sqs-queue
authenticationRef:
name: keda-trigger-auth-aws-credentials
metadata:
queueURL: https://sqs.us-east-2.amazonaws.com/711164302624/my-sqs-keda
queueLength: "5" #batch size
awsRegion: "us-east-2"
identityOwner: operator #when node role has required permission
KEDA has support for both ScaledObjects (like Kubernetes Deployment, StatefulSet, Custom Resource) and ScaledJobs (like Kubernetes Job). The above example is based on ScaledObject for Deployment.
Few things to note here in the above ScaledObject:-
- The ScaledObject will be created in the default namespace
- It will manage the deployment called ‘my-nginx’
- The event source is AWS SQS with queue URL as https://sqs.us-east-2.amazonaws.com/711164302624/my-sqs-keda in region us-east-2. Note, that you can give the Queue name as well. The URL is better in case of any ambiguity.
- The queue length is 5 which means it will get triggered once the batch size of 5 messages arrives in the queue.
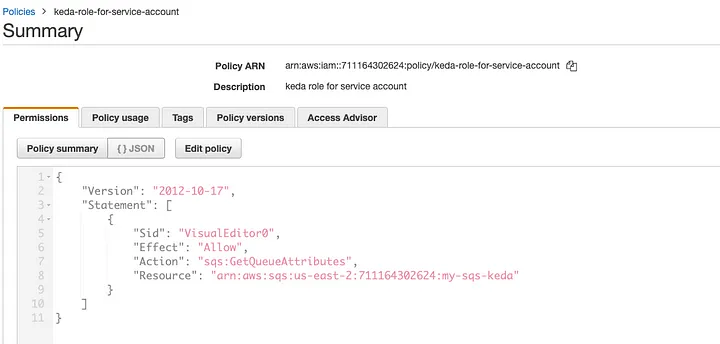
- The identityOwner is the operator (or can be pod as a default) which means the EKS Node role should have permission to communicate with the SQS. The required policy is sqs:GetQueueAttributes attached to its node role.
- The idleReplicaCount is 0 which brings the pod to 0 when idle
Step 6: Creating KEDA TriggerAuthentication (optional)
If the KEDA operator requires to authenticate with the source event (in my case SQS) then we need to follow one of the following authentication mechanisms here:-
6.1) Using IAM role attached to EKS Node — This is the most simplest way by creating an IAM policy of sqs:GetQueueAttributes and then attaching it with the existing/new IAM role to Node Instance. We need to ensure that we keep identityOwner as operator in the ScaledObject (my above example follows this). This gives KEDA access to SQS to get the metric data.
6.2) Using IAM User credentials — In this, we need to create an IAM user in AWS, create a secret in Kubernetes, create a TriggerAuthentication in Kubernetes, and use this TriggerAuthentication in the ScaledObject in Kubernetes as shown below:-
(a) Create an IAM User in AWS with a policy to access the SQS. Note down its Base64 encoded version of access and secret access keys and use it to create the secret.
(b) Create a secret in Kubernetes with the IAM user’s BASE64 encoded access and secret access keys
apiVersion: v1
kind: Secret
metadata:
name: iam-user-secret
namespace: default
data:
AWS_ACCESS_KEY_ID: <base64-encoded-key>
AWS_SECRET_ACCESS_KEY: <base64-encoded-secret-key>
(c) Create a Trigger Authentication
apiVersion: keda.sh/v1alpha1
kind: TriggerAuthentication
metadata:
name: keda-trigger-auth-aws-credentials
namespace: default
spec:
secretTargetRef:
- parameter: awsAccessKeyID # Required.
name: iam-user-secret # Required.
key: AWS_ACCESS_KEY_ID # Required.
- parameter: awsSecretAccessKey # Required.
name: test-secrets # Required.
key: AWS_SECRET_ACCESS_KEY # Required.
(d) Create a ScaledObject using the TriggerAuthentication
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: aws-sqs-queue-scaledobject
namespace: default
spec:
scaleTargetRef:
name: my-nginx
minReplicaCount: 0
maxReplicaCount: 2
triggers:
- type: aws-sqs-queue
authenticationRef:
name: keda-trigger-auth-aws-credentials
metadata:
queueURL: https://sqs.us-east-1.amazonaws.com/012345678912/Queue
queueLength: "5"
awsRegion: "us-east-2"
Voila! It is all ready now. Let’s test it :)
Demo Time:-
Step 1 — Keep the deployment in the watch mode
kubectl get deploy --watch
NAME READY UP-TO-DATE AVAILABLE AGE
my-nginx 0/0 0 0 4h52m
Step 2 — Add some messages to SQS queue (note put more than 5 messages in the queue, as the batch size given is 5 in the ScaledObject)
Result:-
KEDA scaled the application to 2 replicas automatically as messages arrived in the queue.
NAME READY UP-TO-DATE AVAILABLE AGE
my-nginx 0/0 0 0 4h52m
my-nginx 0/1 0 0 4h54m
my-nginx 0/1 0 0 4h54m
my-nginx 0/1 0 0 4h54m
my-nginx 0/1 1 0 4h54m
my-nginx 1/1 1 1 4h54m
my-nginx 1/2 1 1 4h54m
my-nginx 1/2 1 1 4h54m
my-nginx 1/2 1 1 4h54m
my-nginx 1/2 2 1 4h54m
my-nginx 2/2 2 2 4h54m
After a while during the idle state, the pod will scale down to 0 automatically.
my-nginx 0/0 0 0 4h57m
Summary:
In this article, we have seen how we can use KEDA to scale our apps from 0 replicas to the ’n’ number of replicas based on external metrics/events especially based on the messages in the AWS SQS Queue.
As always, you can find the entire source code used in this article in this GitHub link:-
https://github.com/vinod827/k8s-nest/tree/main/iac/aws/eks/keda
Feel free to fork this project and add more IaC (Infrastructure as Code), feedback, and issues in it.
Reference:
Posted on February 11, 2024
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.