SubQuery Network : the Future of Decentralized Web3 Infrastructure

Vanshika Srivastava
Posted on March 6, 2024

TL ; DR
Blockchain technology is rapidly advancing, processing numerous transactions every second. However, unlike traditional databases, blockchain data is not easily searchable due to its ledger structure. To query the blockchain, data must be indexed. This data is extremely valuable for developers to track activities happening on-chain. The Subquery network offers decentralized middleware services like indexers and RPC providers, supporting over 150 ecosystems across the web3 ecosystem. It provides decentralized APIs to dApp developers, allowing data aggregation across multiple chains within a single project.
But first, what is data indexing ?
In the context of databases, the concept of data indexing is well-known.However, in the web3 ecosystem, it has a slightly different objective. Essentially, indexing involves organizing, structuring, and formatting data which includes contracts, events, transactions residing on various blockchain networks such as Ethereum, etc. As a developer, one can streamline the data retrieval from these various chains and also understand the user behavior and interaction on-chain. Indexers are tools that help you to query the data stored on blockchain and can index smart contract events based on certain conditional statements provided by developers.
Due to blockchain’s decentralized nature, the data is spread across thousands of nodes which can make it difficult to aggregate and utilize as per the needs. It would be really difficult for anyone to fetch data around a specific wallet address, to be able to run an efficient query that requires indexers. It's important to highlight this because, for example, accessing details like the first transaction of wallet "XYZ" with a token "TKN" or the largest transaction in the smart contract "SC" is impossible unless the smart contract explicitly stores this data.
A truly decentralized set of indexers will perform better as the nodes are distributed and will keep the system away from the DDOS attack. Secondly, decentralized indexers are not reliant on a single server so there is no single point of failure if one server goes down.
With that being mentioned, let me introduce you to SubQuery Network, a true decentralized infrastructure provider with an open-source data indexer that is fast, flexible and supports to 100+ ecosystems including Osmosis, Cosmos, Ethereum, Polygon, Polkadot, Algorand,etc.
A developer introduction to SubQuery Network
Decentralised Data Indexers provided by SubQuery offer fast, reliable, and customized APIs for web3 projects. By providing an indexed data layer, one can easily retrieve data and enable intuitive user experiences across the dApp. The process of building, testing, deploying, and running these Data Indexers is simplified, making dApp development a breeze with SubQuery.
The SubQuery Network can accommodate any SubQuery Project from any Layer 1 network, whether it's within Polkadot or not. Its design and construction are inherently multi-chain, which allows for indexing of projects from various networks side by side.
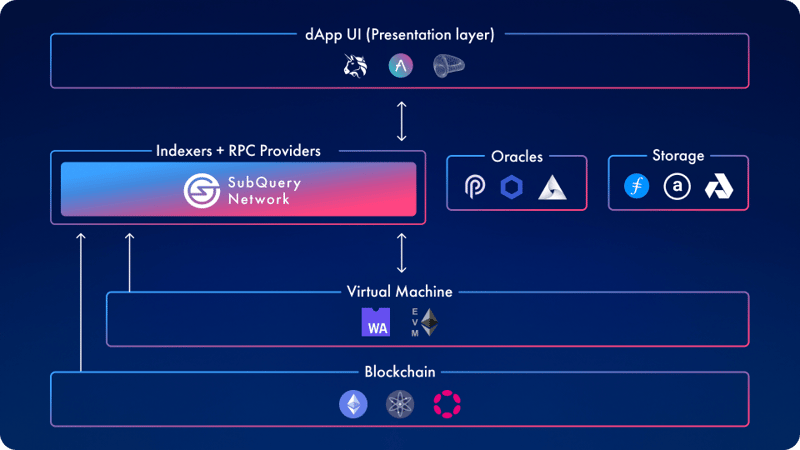
Key Features of the SubQuery’s Comprehensive Multi-chain Indexer
EVM, WASM, and more: The indexer supports a wide range of smart contract execution languages, providing users with maximum flexibility.
Write once, run anywhere: With the capacity to index multiple networks into a single database, it simplifies and streamlines operations.
Absolute performance: The indexer boasts rapid syncing and indexing optimizations, ensuring superior performance at all times.
The power of GraphQL: Supporting filtering, subscriptions, and aggregation, the indexer is equipped with all the features necessary for any project.
Faster reindexing: Thanks to automated historical state tracking, partial data can be reindexed more quickly, saving valuable time.
Lightweight and portable: The indexer doesn't require an expensive archive and can connect directly to any RPC, making it a cost-effective and efficient solution.
The SubQuery network has four primary participants.
Consumers: These are the entities that request specific data for their decentralized applications (dApps) or tools from the SubQuery Network. For each data request, they pay a predetermined amount of SQT. For more information, refer to the section on Consumers.
RPC Providers: Also known as Node Operators, RPC Providers operate the SubQuery Data Node optimized for performance. They are compensated in SQT for offering reliable, affordable, and scalable RPC services to the network. For more insights, look into the RPC Providers section.
Data Indexers: As Node Operators, Data Indexers manage and maintain high-quality SubQuery projects within their infrastructure. This includes running both the indexer and query service. They receive SQT rewards for the data requests they cater to. Further details are available in the Data Indexers section.
Delegators: Delegators participate in the network by supporting their preferred Node Operators. They earn rewards based on the work performed by these Node Operators. More information can be found in the Delegators section.
Building your first project with SubQuery :
Now its time to Build ⚒️ We will try to spin up necessary dependencies for our SubQuery project.
Prerequisities :
NodeJS: You will need a recent version of NodeJS installed, preferably the LTS version.
Docker: This tutorial will utilize Docker for running a local variant of SubQuery's node.
- Install the SubQuery CLI:
Install SubQuery CLI globally on your terminal by using NPM.
# npm installation
npm install -g @subq/cli
# Testing installation with command argument
subql --help
- Initialising a new SubQuery project :
Run the following command inside the directory that you want to create a SubQuery project in:
subql init
- Once you have successfully initialised the package, you will be asked certain questions around the project.
- Project name: A project name for your SubQuery project.
- Network family: The layer-1 blockchain network family that this SubQuery project will index. Use the arrow keys to select from the available options (scroll down as there are multiple pages).
- Network: The specific network that this SubQuery project will index. Use the arrow keys to select from the available options (scroll down as there are multiple pages).
- Template project: Select a SubQuery template project that will provide a starting point in the development. For some networks we provide multiple examples.
- RPC endpoint: Provide an HTTP or websocket URL to a running RPC endpoint, which will be used by default for this project. You can use public endpoints for different networks, your own private dedicated node, or just use the default endpoint. This RPC node must have the entire state of the data that you wish to index, so we recommend an archive node.
- Git repository: Provide a Git URL to a repo that this SubQuery project will be hosted in.
- Authors: Enter the owner of this SubQuery project here (e.g. your name!) or accept the provided default.
- Description: Provide a short paragraph about your project that describes what data it contains and what users can do with it, or accept the provided default.
-
Version: Enter a custom version number or use the default (
1.0.0). -
License: Provide the software license for this project or accept the default (
MIT).
subql init
Project name [subql-starter]: demo-subquery
? Select a network family Ethereum
? Select a network Ethereum
? Select a template project ethereum-starter Starter project for Ethereum networks
RPC endpoint: [https://eth.api.onfinality.io/public]:
Git repository [https://github.com/subquery/ethereum-subql-starter]: [https://github.com](https://github.com/jamesbayly/test-subquery-project)/vanshika-srivastava/demo-subquery
Description [This project can be use as a starting po...]: A demo project for showcasing subquery
Version [0.0.1]:
License [MIT]:
Preparing project... done
demo-subquery is ready
- Once initialised, your directory structure would look something like this :
demo-subquery
L .github
L abis
L docker
L src
L mappings
L mappingHandlers.ts
L test
L index.ts
L .gitignore
L LICENSE
L [README.md](http://readme.md/)
L docker-compose.yml
L package.json
L project.ts
L schema.graphql
L tsconfig.json
- Now, let run the following command to install the right dependencies inside the directory we just had set up. I am using npm, but if you like you can use yarn as well.
npm
cd demo-subquery
npm install
To have more reference of other command line arguments supported by SubQuery you can simply checkout this section of docs.
Post initialisation modifications :
There are 3 important files that needs to be modified. These are:
- The GraphQL Schema in
schema.graphql. - The Project Manifest in
project.ts. - The Mapping functions in
src/mappings/directory.
Based on the chain network that you would have opted, you can checkout the specific guide related to setting up the project. Here is the quickstart guide for the chains.
💡 You can generate a project from a JSON ABIs to save you time when creating your project in EVM chains. Scaffolding saves time during SubQuery project creation by automatically generating typescript facades for EVM transactions, logs, and types. Please see more here on EVM Project Scaffolding
What’s next for developers ?
SubQuery offers a managed service solution that allows you to effortlessly publish your project. You can deploy your new project to the SubQuery Managed Service and use the SubQuery Explorer for querying. For a comprehensive guide on how to publish your new project to SubQuery Projects, refer to the provided instructions.
For an in-depth understanding of the developer documentation, refer to the Build section. Here, you'll learn more about the three essential files: the manifest file, the GraphQL schema, and the mappings file.
SubQuery allows you to run a local SubQuery node which includes indexer and query service along with the Managed service. You can run this service using Docker or running individual components using NodeJS.
You can checkout some of the advance features of SubQuery Network here :
- Multi-chain indexing support - SubQuery allows you to index data from across different layer-1 networks into the same database, this allows you to query a single endpoint to get data for all supported networks.
- Dynamic Data Sources - When you want to index factory contracts, for example on a DEX or generative NFT project.
- GraphQL Subscriptions - Build more reactive front end applications that subscribe to changes in your SubQuery project.
If you are someone using The Graph and would like to migrate to SubQuery, here is how you can migrate your project. You can also read more on how SubQuery is different compared to The Graph.
SubQuery's Future Roadmap: Enhancing RPC Performance and Democratizing Access
SubQuery has already achieved significant breakthroughs in decentralized data indexing. The focus now shifts to enhancing the performance of RPCs with the SubQuery Data Node and transitioning RPC access with SubQuery's Sharded Data Nodes. These initiatives are expected to unlock the next level of performance improvements in the web3 sphere.
Historically, the performance of data indexers and numerous other applications has been confined by the limitations of RPC endpoints. Developers have primarily concentrated on developing nodes that ensure efficient validation, thereby safeguarding the network. As a result, RPCs are not optimized for querying and impose high operational costs.
The introduction of L2 chains increases transaction speed, but their limited querying capabilities make data retrieval inefficient. In Q2 2024, SubQuery plans to launch the Data Node, a heavily modified RPC node that is optimized for querying. This includes optimized endpoints like eth_getLog and the ability to filter transactions in a single API call. The Data Node will be open-source, inviting contributions, extensions, or forks from the community. Initially, it will support leading layer-2s and other EVM networks, and it will be optimized to function on the SubQuery Network in a decentralized manner.
By the end of 2024, SubQuery aims to democratize RPCs by introducing the Sharded Data Node. This will make RPCs more affordable to run and operate for node providers.
You can join SubQuery’s community here to stay updated with everything that’s being worked on by SubQuery team. If you are developer like me and would like to contribute to the project itself, you can checkout the contribution guide here .
Posted on March 6, 2024
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related

November 29, 2024