Transparency: Illusions of a Single System (Part 2)

Vaidehi Joshi
Posted on January 30, 2019

One of the (many) reasons that distributed systems can feel like a really hard topic is because they are often trying to do many things at once. A distributed system makes a system feel seamless to its end user; however, in order to achieve that goal, we often have to account for many things along the way.
In part one of this series, we started diving into what kinds of illusions a distributed system presents to its user. As a quick recap, distribution transparency is what allows a distributed system — which is made up of multiple, self-sufficient, autonomous nodes — to masquerade as a single image system. There are many different ways that a distributed system can be transparent, and we’ve already explored three of those (namely, access, location, and relocation transparency).
Let’s continue our investigation into the forms of transparency and see what else we find!
(Even more) forms of transparency
Migration transparency
We have already learned about a form of transparency called “relocation transparency”, which allows a distributed system to move some resource from node A to node B, even though some user might be accessing it. But, it is also possible that a resource could be accessed by a user, then it could move to a new node, and then be accessed again by that same user. Migration transparency is what allows for the movement of resources within a system without the consumer (user) of the resource noticing.
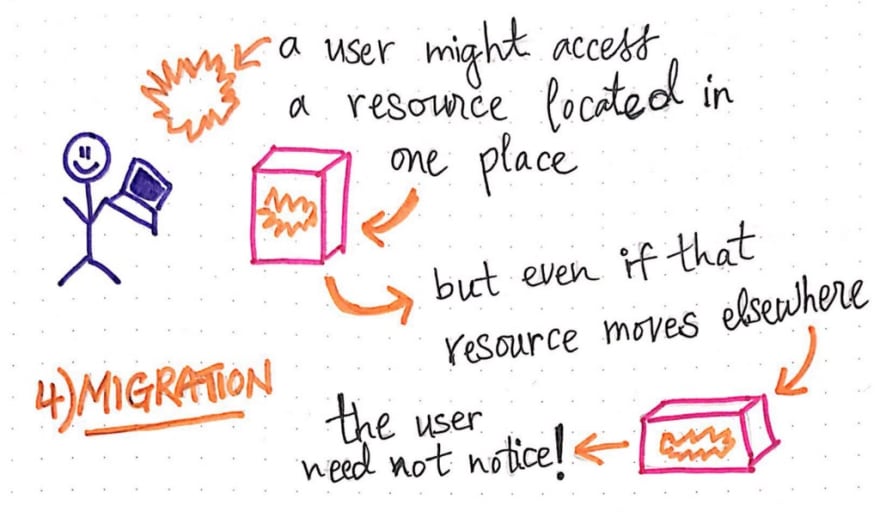
We can think of migration transparency as a “less strict” version of relocation transparency; the reason that it is “less” strict is because we’re assuming that the system isn’t moving the resource while it is being consumed by the user, as is the case in relocation transparency.
When it comes to migration transparency, the way that a resource moves from location A to location B could mean a variety of different things. The resource could change its physical address in the system, and everything that pointed to the resource and referenced it would have to change in accordance with its new location. Migration transparency is what ensures the fact that a resource can move to a different location within the system and still be accessible in the same manner by a user; this also means that a resource shouldn’t have to change its name if it moves locations, either.
Replication transparency
As we might begin to imagine, being able to access, migrate, and relocate a resource can get quite dicey. This becomes especially tricky if we only have a single resource that all of the users of our system can access!
But that’s where replication transparency can come in to help us out. Replication transparency allows for multiple instances of a resource to exist at once. With this form of transparency, users or programs can access a resource without knowing which instance of the resource they’re working with, much less the fact that there is more than one copy of the resource that even exists!
When designing a distributed system to be replication transparent, we generally have to consider three things: creating , maintaining , and accessing the replicated resource.
Considering these aspects of how a resource will be replicated (and later accessed and used) is crucial. This is because transparency of any kind is all about illusion.
Making multiple replicas of a resource is something that requires a certain amount of thought and care.
Take, for example, the creating and accessing of a replicated resource. In order to mask the fact that there are multiple copies of a resource, replication transparency must be able to ensure that all of the replicas of a resource have the same name, and that they can all be accessed in the same way. In order to create a replica of a resource, we’d need to consider how we would name and access that replica. We can imagine that, if two copies of the same resource had different names, or if they both weren’t all retrieved in the same manner, then the end user would clearly get to the know about the multiple copies of the resource they were trying to retrieve! Thus, any form of replication transparency must operate within the goal of ensuring that an end user would only ever think that there is one resource that they are interacting with.

Replication transparency is particularly interesting because it provides us with many hidden benefits. Having multiple instances of a resource affords us with increased reliability within our system. If the resource that we’re dealing with is a form of data (a file, for example), then replication transparency ensures that we can read from another copy of the same file if something happens to the first one.
Similarly, if the resource is a process, then this transparency will make it such that another, identical (replicated) process can step into the same state as the first (unavailable) process and continue whatever operation it was performing. In fact, a replicated process is a great example of how important it is to be able to maintain the state different copies of the same resource!
In addition to heightened reliability, replication transparency also provides us with the added benefit of increased performance. Having multiple replicas of some data on the same server means that all of the users who are accessing a single resource via the same server will be able to access reliable data fairly quickly, especially because they aren’t all trying to just get to one single, shared resource. Replication for the win!
Concurrency transparency
Sharing resources is obviously an important part of making a distributed system work. As we now know, replication transparency allows users to unwittingly “share” access to a resource by creating and maintaining multiple versions of it. However, what happens if the resource is being modified, or “written to” by a user (and not just being accessed or “read by” a user)? Or, what if something about a resource changes and two users are sharing access to it at once?
Concurrency transparency (also sometimes known as transaction transparency ) allows multiple users of a distributed system to compete for access to a resource and perform actions concurrently on the resource without any of the users knowing about it.
Handling concurrent operations in a distributed system is a much trickier task than it is in a single, non-distributed, central system.
In a true single system, a single resource would exist in one location, and race conditions (such as two users trying to modify one resource) would likely be a matter of first come, first serve (or first come, first “modify” in this case!). True concurrency doesn’t exist.

In a distributed system however, there could be multiple copies of a resource, the shared resources could be accessed by different end users at the same time. For example, imagine two users accessing a shared file; what happens if something about that file changes while it is being accessed? Or consider an ATM network or an e-commerce store; at a minimum, a distributed system would need to account for the ever-changing state of the data involved. Most likely, it would need to gracefully lock down a database while it is being written to, and be able to handle two modifications happening to some shared process at once.
Accounting for the state of a shared resource between multiple users, as well as handling changes to that shared resource while it is being accessed by users is no easy task. In fact, within the world of distributed systems, concurrency control algorithms are an entire topic unto themselves!
Failure transparency
Given all of the things that a distributed system must hide from its users, there is one aspect that is just sometimes beyond anyone’s control: parts of a system failing. Even in a single system, failure is possibility; in a distributed system — which has so many more moving parts working together as once — failure is just a reality.
Failure transparency allows for an end user of a distributed system to continue using the system and accessing any resource without noticing that part of the system has failed. The failures in a distributed system are also referred to as the faults of the system.

Since system faults are just a reality, it is up to us, the designers of the distributed system, to consider what the faults of a system might be, and how we plan to recover from them. Sometimes it is difficult to identify all the faults of a system, particularly because it often encompasses not just software failures, but hardware failures as well!
Oftentimes, ensuring failure transparency might mean a surfacing a delayed response to the user while the system determines what exactly is the fault, finds the cause of it, and handles it in the way that the programmer of the system intended. However, a delayed response to the end user could be confusing; for example, if a server fails, and a user is unaware of the fault in the system, it is possible that they might assume that the process didn’t work, rather than thinking that they process is just delayed. In some cases, replication transparency can help step in here, because having multiple copies of a resource means that we can leverage another copy in case one ends up being the root of the failure.
Failure transparency is more ubiquitous that we may realize, and many distributed systems that we use every day account for some subset of (potential) faults in their system. For example, database management systems have some method of ensuring failure transparency. Handling failure transparency is one of the most difficult aspects of designing and maintaining a distributed system.
How transparent can we really be?

Now that we’ve covered the main forms of transparency, we can start to see that some forms of transparency seem to be easier to account for than others. Depending on the size and scale of a system, it might even be impossible to achieve true failure or true concurrency transparency! All of these different things we need to “hide” from our end users may even feel a bit overwhelming; how can we possibly account for all of these illusions while designing a distributed system?!
In reality, achieving full distribution transparency and successfully ensuring access , location , relocation , migration , replication , concurrency , and failure transparency in a single distributed system is impossible.
There are, indeed, limits to what we, as designers of distributed systems can really do, and what we can truly account for! And sometimes, it is actually not even in our best interest (or even in our user’s best interest) to maintain the illusion of our system. Transparency is a hard problem, and we don’t need to beat ourselves up if we can’t be fully transparent (because in reality, we actually can’t even do that). However, it is good to know the ways in which we can start to think about the different ways that we might want to be transparent with our users, and keep them in the dark about some of the deep, dark, and messy parts of our system.
Resources
Distribution transparency is a deep topic in the world of distributed systems, and this post just scratches the surface. If you’d like to learn more about some of the more complex transparencies, check out the resources below!
- Transparencies, Professor Jon Crowcroft
- Transparency in Distributed Systems, Professor Sudheer Mantena
- Distributed System Principles, Professor Wolfgang Emmerich
- Goals of Distributed Systems, Professor Lu Ruan
- Distribution Transparency, Professor Juhani Toivonen
- A brief introduction to distributed systems, Maarten van Steen & Andrew S. Tanenbaum
Posted on January 30, 2019
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related




