Let’s Understand Chrome V8--Chapter 21: Compiler Workflow: Token, AST

灰豆
Posted on October 11, 2022

Original source: https://javascript.plainenglish.io/lets-understand-chrome-v8-compiler-workflow-token-ast-8f629bd79803
Welcome to other chapters of Let’s Understand Chrome V8
In the last article, we talked about the parser, we knew that the scanner is passive and needs to be waked up by the parser. Here, I go on with walking you through the compiler workflow, watching tokens, and AST in detail.
1. Scanner and Token
The following function is responsible for generating AST, it contains the scanner initialization, scanner execution, and parser token, where you can watch compiler workflow in detail.
1. FunctionLiteral* Parser::ParseProgram(Isolate* isolate, ParseInfo* info) {
2. //omit.................
3. scanner_.Initialize();
4. scanner_.SkipHashBang();
5. FunctionLiteral* result = DoParseProgram(isolate, info);
6. MaybeResetCharacterStream(info, result);
7. MaybeProcessSourceRanges(info, result, stack_limit_);
8. HandleSourceURLComments(isolate, info->script());
9. //omit..................
10. return result;
11. }
Line 3 is the scanner initialization, below is the source code.
1. void Scanner::Initialize() {
2. Init();
3. next().after_line_terminator = true;
4. Scan();
5. }
In line 3, the Init() initializes the scanner. In line 5, the Scan() generates only a token, remember that the scanner is driven by the parser, this token is used to wake up the parser first and then trigger a token-cache miss in soon, ends up starting the compiler pipeline. Let's examine the Init() in more depth.
1. void Init() {
2. Advance();
3. current_ = &token_storage_[0];
4. next_ = &token_storage_[1];
5. next_next_ = &token_storage_[2];
6. found_html_comment_ = false;
7. scanner_error_ = MessageTemplate::kNone;
8. }
9. //.........................
10. template <bool capture_raw = false>
11. void Advance() {
12. if (capture_raw) {
13. AddRawLiteralChar(c0_);
14. }
15. c0_ = source_->Advance();
16. }
17. //................
18. inline uc32 Advance() {
19. uc32 result = Peek();
20. buffer_cursor_++;
21. return result;
22. }
23. //...................
24. inline uc32 Peek() {
25. if (V8_LIKELY(buffer_cursor_ < buffer_end_)) {
26. return static_cast<uc32>(*buffer_cursor_);
27. } else if (ReadBlockChecked()) {
28. return static_cast<uc32>(*buffer_cursor_);
29. } else {
30. return kEndOfInput;
31. }
32. }
In line 2, the Advance() gets out a character from JavaScript code that you as developers are writing actually.
Line 11 shows the Advance() source code. In line 15, the keyword c0_ points to the next character that the Advance() will take out. The definition of source_->Advance is at line 18. Please look at line 24, the Peek() is the actual function that gets out a character from your JavaScript, since in lines 25-28, it is reading the buffer stream that holds your JavaScript.
Back to void Scanner::Initialize(), let's dive into the Scan().
1. void Scanner::Scan() { Scan(next_); }
2. //....................
3. void Scanner::Scan(TokenDesc* next_desc) {
4. next_desc->token = ScanSingleToken();
5. DCHECK_IMPLIES(has_parser_error(), next_desc->token == Token::ILLEGAL);
6. next_desc->location.end_pos = source_pos();
7. }
8. //.....................
9. V8_INLINE Token::Value Scanner::ScanSingleToken() {
10. Token::Value token;
11. do {
12. next().location.beg_pos = source_pos();
13. if (V8_LIKELY(static_cast<unsigned>(c0_) <= kMaxAscii)) {
14. token = one_char_tokens[c0_];
15. switch (token) {//omit.....................
16. case Token::IDENTIFIER:
17. return ScanIdentifierOrKeyword();
18. default:
19. UNREACHABLE();
20. }
21. }
22. if (IsIdentifierStart(c0_) ||
23. (CombineSurrogatePair() && IsIdentifierStart(c0_))) {
24. return ScanIdentifierOrKeyword();
25. }
26. if (c0_ == kEndOfInput) {
27. return source_->has_parser_error() ? Token::ILLEGAL : Token::EOS;
28. }
29. token = SkipWhiteSpace();
30. // Continue scanning for tokens as long as we're just skipping whitespace.
31. } while (token == Token::WHITESPACE);
32. return token;
33. }
In line 4, the ScanSingleToken() uses the Advance() to get out characters one by one until meeting a terminator.
In our case, the started character is an f, we know that the f may mean the keyword function or a normal user-defined variable, depending on the next characters. Since our case is the keyword function, step into lines 16-17.
The fundamental of the scanner is the finite state automaton, V8 uses the pre-defined macro template and switch-case to scan characters and then organize related characters together as a token that will be filled into the cache.
Let's get a glance at the ScanIdentifierOrKeyword().
1. V8_INLINE Token::Value Scanner::ScanIdentifierOrKeywordInner() {
2. STATIC_ASSERT(arraysize(character_scan_flags) == kMaxAscii + 1);
3. if (V8_LIKELY(static_cast<uint32_t>(c0_) <= kMaxAscii)) {
4. if (V8_LIKELY(c0_ != '\\')) {
5. uint8_t scan_flags = character_scan_flags[c0_];
6. DCHECK(!TerminatesLiteral(scan_flags));
7. //omit....................
8. AdvanceUntil([this, &scan_flags](uc32 c0) {
9. if (V8_UNLIKELY(static_cast<uint32_t>(c0) > kMaxAscii)) {
10. scan_flags |=
11. static_cast<uint8_t>(ScanFlags::kIdentifierNeedsSlowPath);
12. return true;
13. }
14. uint8_t char_flags = character_scan_flags[c0];
15. scan_flags |= char_flags;
16. });
17. if (V8_LIKELY(!IdentifierNeedsSlowPath(scan_flags))) {
18. //omit...................
19. }
20. can_be_keyword = CanBeKeyword(scan_flags);
21. } else {
22. //omit................
23. }
24. }
25. return ScanIdentifierOrKeywordInnerSlow(escaped, can_be_keyword);
26. }
The ScanIdentifierOrKeywordInner() generates one token at one execution.
2 Generate AST
The DoParseProgram() is responsible for generating AST tree.
1. FunctionLiteral* Parser::DoParseProgram(Isolate* isolate, ParseInfo* info) {
2. ParsingModeScope mode(this, allow_lazy_ ? PARSE_LAZILY : PARSE_EAGERLY);
3. FunctionLiteral* result = nullptr;
4. {
5. DeclarationScope* scope = outer->AsDeclarationScope();
6. scope->set_start_position(0);
7. FunctionState function_state(&function_state_, &scope_, scope);
8. ScopedPtrList<Statement> body(pointer_buffer());
9. int beg_pos = scanner()->location().beg_pos;
10. if (parsing_module_) {
11. //omit................
12. } else if (info->is_wrapped_as_function()) {
13. ParseWrapped(isolate, info, &body, scope, zone());
14. } else {
15. this->scope()->SetLanguageMode(info->language_mode());
16. ParseStatementList(&body, Token::EOS);
17. }
18. scope->set_end_position(peek_position());
19. if (is_strict(language_mode())) {
20. CheckStrictOctalLiteral(beg_pos, end_position());
21. }
22. if (is_sloppy(language_mode())) {
23. InsertSloppyBlockFunctionVarBindings(scope);
24. }
25. if (info->is_eval()) {
26. DCHECK(parsing_on_main_thread_);
27. info->ast_value_factory()->Internalize(isolate);
28. }
29. CheckConflictingVarDeclarations(scope);
30. }
31. info->set_max_function_literal_id(GetLastFunctionLiteralId());
32. return result;
33. }
Line 2 get out lazy option, in default, lazy is true and is defined in flag-definitions.h. Line 8 creates an empty AST body.
In line 16, the ParseStatementList() parses tokens and generates AST.
1. void ParserBase<Impl>::ParseStatementList(StatementListT* body,
2. Token::Value end_token) {
3. DCHECK_NOT_NULL(body);
4. while (peek() == Token::STRING) {
5. //omit.........
6. }
7. TargetScopeT target_scope(this);
8. while (peek() != end_token) {
9. StatementT stat = ParseStatementListItem();
10. if (impl()->IsNull(stat)) return;
11. if (stat->IsEmptyStatement()) continue;
12. body->Add(stat);
13. }
14. }
In line 4, the peek() gets back the type of the current token. In our case, the first token is Token::FUNCTION which is neither Token::STRING nor end_token, so go into ParseStatementListItem().
1. ParserBase<Impl>::ParseStatementListItem() {
2. switch (peek()) {
3. case Token::FUNCTION:
4. return ParseHoistableDeclaration(nullptr, false);
5. case Token::CLASS:
6. Consume(Token::CLASS);
7. return ParseClassDeclaration(nullptr, false);
8. case Token::VAR:
9. case Token::CONST:
10. return ParseVariableStatement(kStatementListItem, nullptr);
11. case Token::LET:
12. if (IsNextLetKeyword()) {
13. return ParseVariableStatement(kStatementListItem, nullptr);
14. }
15. break;
16. case Token::ASYNC:
17. if (PeekAhead() == Token::FUNCTION &&
18. !scanner()->HasLineTerminatorAfterNext()) {
19. Consume(Token::ASYNC);
20. return ParseAsyncFunctionDeclaration(nullptr, false);
21. }
22. break;
23. default:
24. break;
25. }
26. return ParseStatement(nullptr, nullptr, kAllowLabelledFunctionStatement);
27. }
In ParseStatementListItem, according to the Token type, do the next actions. Precisely, the ParseStatementListItem also is a finite state automaton which uses pre-defined macro templates and switch-case to match and analyze characters.
Figure 1 shows the call stack.
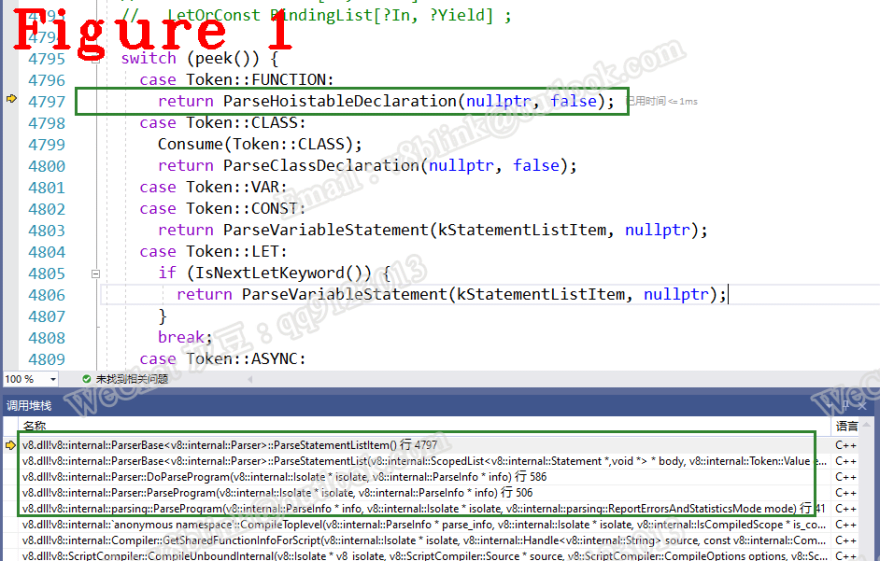
In JavaScript, a statement may be a variable definition, a function, or a statement block, so the ParseStatementListItem() recursively calls itself frequently.
Takeaways
(1) The fundamental of the compiler is used the finite state automaton to analyze characters. Specifically, V8 uses macro templates and switch-case;
(2) The compiler's minimal granularity is a JavaScript function;
(3) Since lazy compilation is here, a function is compiled when it will execute in soon;
(4) The FunctionLiteral holds the AST tree that represents your JavaScript function;
(5) The following is the macro template that defines Token.
1. #define IGNORE_TOKEN(name, string, precedence)
2. /* Binary operators */
3. /* ADD and SUB are at the end since they are UnaryOp */
4. #define BINARY_OP_TOKEN_LIST(T, E) \
5. #define EXPAND_BINOP_ASSIGN_TOKEN(T, name, string, precedence) \
6. T(ASSIGN_##name, string "=", 2)
7. #define EXPAND_BINOP_TOKEN(T, name, string, precedence) \
8. T(name, string, precedence)
9. #define TOKEN_LIST(T, K) \
10. T(TEMPLATE_SPAN, nullptr, 0) \
11. T(TEMPLATE_TAIL, nullptr, 0) \
12. /* BEGIN Property */ \
13. T(PERIOD, ".", 0) \
14. T(LBRACK, "[", 0) \
15. /* END Property */ \
16. /* END Member */ \
17. T(QUESTION_PERIOD, "?.", 0) \
18. T(LPAREN, "(", 0) \
19. /* END PropertyOrCall */ \
Okay, that wraps it up for this share. I’ll see you guys next time, take care!
Please reach out to me if you have any issues. WeChat: qq9123013 Email: v8blink@outlook.com
Posted on October 11, 2022
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related


November 29, 2024