Minha experiência na 2ª rinha de backend com Ruby + Sinatra

Victor de Oliveira Marinho
Posted on February 27, 2024
Introdução
Fala minha tropa, hoje venho aqui contar um pouco da minha experência na 2ª edição da rinha de backend. Ano passado acabei não conseguindo participar, devido ao prazo ter ficado um pouco apertado. Esse ano com o prazo mais largo, consegui fazer com folga minha versãozinha. Para conseguir submeter uma versão, pensei em utilizar o ruby com sinatra, para ver algo um pouco mais diferente - no trabalho acabo usando muito rails, dessa vez queria ver que outras possibilidades conseguiria fazer com ruby, só que de forma mais enxuta.
Inspirado em algumas lives do Leandro Proença, até pensei na alternativa de fazer com ruby puro, mas preferi ficar no seguro e fazer com sinatrinha que já tinha tido oportunidade de mexer num módulo extra do treinamento da Campus Code - tendo sido também com o Leandro.
Pois bem, decidido a stack, eu fiquei pensando no nome do projeto. Infelizmente é meu modus operandi (desde a época de escrever ensaios na faculdade de Letras). Peguei umas músicas do Frank Sinatra e escolhi My Way, sobretudo pelo trecho que mais parecia um meme do resultado final após rodar o Gatling:
O Processo
A partir disso, fiz um README boladão, e diferente do ano passado, esse ano decidi ir por baby steps. Ano passado, além de prazo apertado, eu fiquei muito ansioso com a infinidade de coisas que eu não tinha tanto conhecimento e que precisava - como o Nginx e Gatling. Isso acabou me travando. Dessa vez, me preocupei primeiro em construir as rotas, depois fui construir os serviços no docker, depois a partir do repositório agostinho do Leandro, pensei num adaptador de conexão com o banco junto com um pool de conexões. Trabalhei em cima das validações, em grande parte me ajudou a ler os testes do Gatling, para atender aos requisitos.
Terminado a parte de desenvolvimento em si, fui criar o docker-compose baseado no repositório da rinha e fui alinhando conforme zapeava entre os repositórios. Conseguindo rodar o docker-compose, parti para instalar o JDK e baixar o Gatling para rodar os testes. Feito isso, rodei os testes do Gatling e aí começa a saga.
Bugs e mais bugs…
Ao rodar o Gatling as primeiras vezes, já estourava uns 70% as validações, tive que rever a lógica. Mas o que eu ainda não tinha percebido é que era no fluxo de requisições concorrentes que estourava os erros. Visto isso, foi quando entre inúmeros tweets da rinha, vi a importância do uso das transactions. Esse foi o primeiro item que aprendi algo, e que me ajudou a sanar grande parte dos erros.
Acompanhando via Portainer, eu comecei a observar alguns erros do Nginx, então para entender o que eu estava configurando de errado, fui entender o que cada linha do Nginx significava, e com isso consegui ter maior consciência do que estava fazendo de fato. Uma abordagem que eu insistentemente tinha era de aumentar no talo as worker_connections, cheguei a colocar 60000. Não percebia que esse aumento em si não adiantava, já que minhas APIs não conseguiam atender esse volume.
Após entender isso, comecei a rever as threads da aplicação e trabalhei um bom tempo em entender como orquestrar isso. Comecei a subir o puma com workers + threads, e comecei a ter alguns resultados positivos - estava usando 3 workers + 5 threads e com isso conseguia atender um pouco mais da enxurrada de requisições. Mas ainda assim após algum tempo começava a derrubar as connections do Nginx, e estourava inúmeros erros 502 e 500.
Foi então que o Leandro, outra vez, me mandou uma thread do twitter em que explicou os aprendizados dele com a rinha anterior, thread essa que deixo abaixo:
Alguns ajustes no NGINX e PostgreSQL e minha versão Ruby ganha um aumento de tput que garante 46k inserts.
— leandro • nsp (@leandronsp) September 6, 2023
"Ajuste pra cima", eles dizem.
Não. É pra baixo.
As queries são rápidas, ñ preciso floodar a stack toda com mtos requests à espera: latência gera custo.
Detalhes na 🧵 pic.twitter.com/cAj8Ew3XWu
O que me ajudou foi entender que para conseguir atender de forma efetiva eu deveria fechar a torneira no Nginx e nas threads e workers das APIs, e focar em tunar as respostas do BD. Retornei a aplicação para apenas 5 threads, no Nginx limitei à 256 worker_connections e fui entender como funcionava a pool de conexões. Foi ali que demorei grande parte. Quando retornava à essas configurações mais sóbrias, acontecia de muito cedo dropar as conexões do Nginx e das APIs, não entendia porque havia um gargalo no banco de dados. Depois de muito conversar e estudar documentações, não chegava a nenhuma conclusão. No desespero, fui ver como trabalhar com I/O assíncrono, vi alguns web servers (como o falcon, thin etc), mas nada funcionava direito. Entre bugs e mais bugs desfiz tudo e fui ler a documentação da gem Connection Pool.
Bug com a gem Connection Pool
Não sei por qual motivo, estava tendo problemas com o método checkout do pool de conexões. Aparentemente, ele após o uso não estava realizando a devolução da conexão pro pool, fazendo com que a cada transaction fosse criada uma nova conexão com o banco. Isso explicava o gargalo, mas como contornar? Bom, havia o método checkin, com isso, criei um método de abertura e de fechamento da conexão e isso começou a surtir efeito.
Porém, o melhor foi utilizar o método with - por indicação do Leandro. Indo na documentação, inclusive, eles falam que é melhor o método with em vez do checkout devido a instabilidades que poderiam ocorrer (às vezes é só ler a documentação né? kkkk).
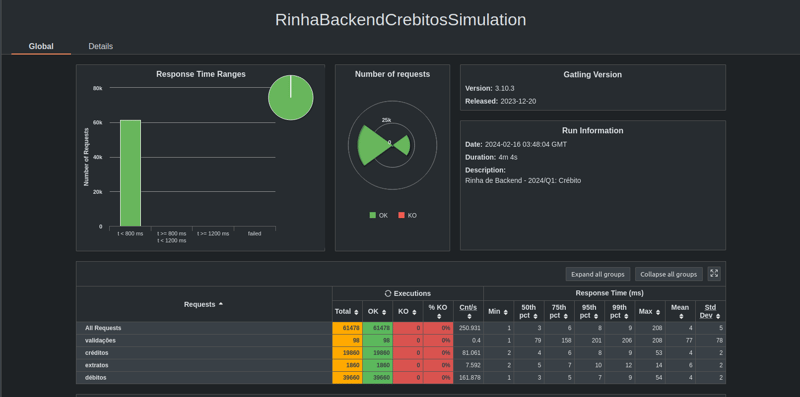
Enfim, com o método ajustado, consegui atender a maioria das requests, mas ainda sim tinha erros. Os últimos ajustes foi configurar no PostgreSQL 30 max_connections e 30 io_concurrency para atender o pool de 15 conexões das duas APIs. Cada API tinha 5 threadzinhas e com folga conseguiu atender as conexões repassadas pelo Nginx. Os resultados estão abaixo de uma das execuções:
Considerações finais
Lição aprendida é que nem sempre escalar recursos, colocar mais power de máquina, pods, réplicas etc é um caminho indicado. Às vezes é mais produtivo identificar onde é o gargalo e como otimizar e, sobretudo, fechar a torneira pode ser mais eficaz em termos de performance (e também de grana em cenários reais de empresas).
Bom, dos vários temas que pude aprender nessa rinha - seja do uso de transactions, pool de conexões, threads, concorrência - foi muito importante também esse compartilhamento dos problemas e das ajudas dos colegas (seja pessoalmente, seja via tweets compartilhando as soluções). A possibilidade de ver várias das submissões e as soluções que cada um fazia me ajudou muito no processo também.
Só tenho a agradecer ao Francisco Zanfranceschi por ter criado a rinha e ter fornecido essa oportunidade de tanto aprendizado. Agradecer também ao Leandro Proença pela ajuda e por todos os conteúdos que ele tem produzido. Agora vamos aguardar a live do dia 14/03 para ver em que posição fiquei, e já aguardo ansiosamente a próxima edição da rinha.
Pra você que se interessou, ainda tem tempo pra fazer a sua submissão, até o dia 10/03, o link do repo é esse aqui: https://github.com/zanfranceschi/rinha-de-backend-2024-q1
Link da minha versão Ruby + Sinatra pra Ruby: https://github.com/v1t4o/my_way
Posted on February 27, 2024
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.