Team Leadership Toolkit: Assessing risk

Nico Riedmann
Posted on September 17, 2023

Team Leadership Toolkit: Assessing risk
Unlike the previous TLTK articles, this one is pretty specific to my experience in software engineering and a "you build it, you run it" mindset in which teams are fully responsible for their software products working in production.
If you're leading a team that's not responsible for operating something that is used by others, this likely won't be too helpful for you.
You might know this question. You might have heard it from your team as "Hey, everyone else took that week off, can I do as well?".
Or from your lead as "What do we do if something fails while people are on vacation?".
There are two pretty easy answers to that question of whether it's okay for everyone to be off.
Either it's a "No", or it's "Sure, it's Jane's on-call rotation week, though, so her vacation won't be great."
Or if you're very confident, it might be, "Sure, nothing will happen!".
Where's that confidence coming from though? Is it based on facts, or just your gut feeling?
Even with an on-call rotation, are you sure that Jane can address any issue that might come up?
Especially if you happen to be on a team that owns several interconnected services, she might be missing something.
One of the most useful tools I've found to answer this question is not my gut but taking a close look at risks and remediation strategies.
Collecting data
To take a structured approach to this, let's start by collecting some basic data in your team's shared documentation tool of choice.
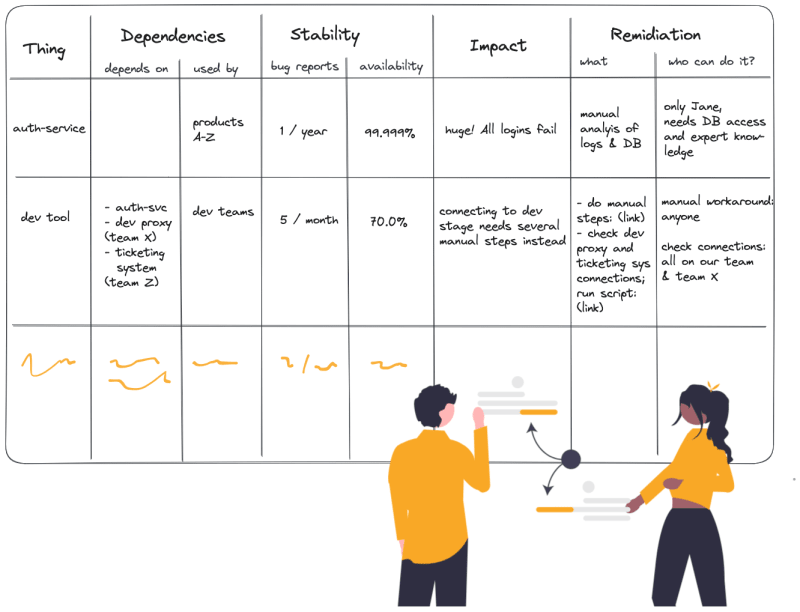
Start by making a complete list of things your team is responsible for.
Note: I'll be using 'thing' consistently. Your team might own several microservices, physical hardware, CI/CD pipelines, some internal dev tooling, etc.
Whatever your 'things' may be, if someone calls you if they're having issues with it, write it on your list.
Then, for each of them, note down any known dependencies:
- What do they depend on, and who owns it?
- Note the thing and people responsible. In the best case, you can even link to their risk assessments.
- What depends on your thing, and who owns that?
Risk: How likely do things go wrong?
We'll need that in a moment, but for now, let's collect some data about the stability of your thing:
- How many reported production issues did you have with this thing in the last month, quarter, and year?
- You can probably pull that information from your ticketing system bug reports quite easily.
- Bonus points if you can find out if they usually relate to new releases or if there are other causes for people running into issues with your thing.
- What's the availability of your things in the last month, quarter, year?
- If you don't yet track this, apply your team's collective gut-feeling or skip this for now. But do start thinking about how you'll know in the future. Consider that if your thing is running, but everything users do with it fails, it's not really available, so don't just track uptime.
With that, you should already be able to answer the question, "How likely is it that something will go wrong?".
If your team owns more than one thing, each will of course, have a different likelihood of something going wrong - when thinking of the risk for your team, look at the most risky thing you own.
Impact: Just how bad will everyone's day be if things go wrong?
The next part needs a bit more thinking and is a great exercise to do as the whole team:
- What's the impact if your thing fails? Do other things that depend on it fail as well? Are customers impacted? Are internal processes impacted? How important are those? Are there fallbacks or workarounds?
Remediation: What do you do when things go wrong?
Still as a team, ask yourselves two more questions:
- What can you do if your thing fails? Are there several ways it might fail? Is it directly obvious something is wrong? What do you need to check what has gone wrong? What specific actions can you take to get your thing working again?
- Who can find out what's wrong and resolve the issue? Does it need special knowledge only that one guy on your team has? Does it need specific tools or permissions, like access to a production database?
This will likely show you a few things your gut feeling didn't.
That super unstable thing you've been worried about can be fixed by restarting it, and because it happens a lot, there are many people allowed to do this.
On the other hand, that thing you know is one of the most important ones in the company and is built well enough to only fail once in a blue moon, is so complex to fix that only the most senior engineer and your CTO know to troubleshoot what's wrong - after all they've built it years ago. And your CTO doesn't even have permission to access it anymore because he doesn't need it.
Now, what do you do with all this information?
What to do with those facts
For one, it helps you answer the "Can we all go on vacation for a month, and everything will just keep working?" question.
If your experience is anything like mine, that answer will probably contradict your gut feeling and be some variation of "No. Nope. Never!".
But the risk assessment exercise already gave you all the information you need to start working on making that answer a "Yes. For sure!".
You know what things you actually need to focus your attention on and take steps to improve stability, simplify troubleshooting, and ensure everyone on your team has enough knowledge and can get the right access needed to solve problems if they should occur.
And if "I want my whole team to go on vacation without worrying." is not a convincing enough argument to get improvements and knowledge-sharing time on your roadmap, "I want a consistent, high-quality experience for our customers with minimal issues and service interruptions." most certainly is.
What's next
There are a few reasonable followups to this exercise:
Think about your remediation strategies
If you followed the steps, you've already started writing down what to do when things go wrong. Keep doing that and start thinking about how to make things easier to handle.
Could your remediation steps be automated or at least simplified with scripts?
If there are manual steps, can you turn them into well-defined playbooks and runbooks that anyone can follow?
Think about SLIs, SLOs and SLAs
You might already be thinking to yourself, "Hey, this whole thing is just about defining SLOs!" - and at least one early reviewer did as well.
I would argue it isn't. You can start taking a structured approach to risks without diving deep into SLOs, and you shouldn't ever feel like you need tooling in place before you can start thinking about risk.
Yes, the two 'stability metrics' are very basic samples of service level indicators. But they're one's that make sense for most 'things' and for which you very likely have data available if you use any kind of issue management tool.
That's what makes them a great starting point!
As a next step, it might, of course, be time to find a way to measure more detailed SLIs and think about defining SLOs and SLAs based on the availability and the impact of downtimes you've discovered.
The 'team leadership toolkit' is a series of bite-sized articles on techniques I find helpful as a software engineering team lead.
Having shared most of this with peers and mentees in an unstructured way, I've started this to concisely describe the What, Why and How of things that work for me and might be helpful for others.
What about you? What's in your 'leadership toolkit'?
I'd love to hear your comments or posts!
Posted on September 17, 2023
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related



