survey: GENERATE RATHER THAN RETRIEVE: LARGE LANGUAGE MODELS ARE STRONG CONTEXT GENERATORS

Tutty
Posted on December 24, 2023
選定理由
ICLR2023採択。MSR(Microsoft Research)の Cognitive Service チーム。
Paper: https://arxiv.org/pdf/2209.10063.pdf
Code: https://github.com/wyu97/GenRead
サーベイ論文[Gao2023]でも参照された。
two-tower architecture の課題は binary passage retriever[Yamada2021]や[Shan2023]でも扱われている。
概要
【技術課題】
Open-Domain Question AnsweringやFact Checkingといった知識集約型タスク(knowledge-intensive task)では外部コーパスから関連しているドキュメントを効率的に回収し、情報の構造化を行わなければならない。
【従来技術】
従来のRAGは Retrieve-then-Read であったが、1.外部コーパスの関連文書が有効な情報を持っているとは限らない、2.質問と文書の埋め込みが別々の推論でコンテキストが考慮されにくい(いわゆるtwo-tower architectureと呼ばれる)、3.インデックスの作成には全文書の埋め込みを計算しなければならない、といった課題がある。
【提案】
検索する代わりに質問に基づいて文脈に合う文書をLLMから直接生成する、Generate-then-Read(GenRead)アプローチを提案。さらに異なるプロンプトを選択するクラスタリングベースの方法を採用し、多様性のある文書を生成するようにした。RAGで生成モデルを検索に使用するのは[Mao2023]があるが、これはプロンプトを拡張している形であり、文書そのものを生成させるのは本研究が初。
【効果】
GenReadはTriviaQAとWebQで EM score (exact match) 基準にて従来手法を上回った。外部コーパスからの文書取得が不要で、迅速かつ包括的な回答提供が可能。取得と生成の組み合わせにより、モデルのパフォーマンスがさらに向上する可能性がある。
GenRead

図1がGenReadの全体像である。学習データを使用しない zero-shot での利用と学習データでFiDなど軽量の言語モデルを教師あり学習する方法がある。
Zero-shot GenRead
![]()
上記が通常のRAGの定式化で、質問(q)とretrieverとgeneratorのパラメータ(θ)に対するMAP(事後確率最大化推定)が応答(a)とみなすことができる。この定式化には外部ドキュメントが入っておらず、十分な外部知識の活用を行うことができない。
![]()
![]()
上記が本研究での定式化で、補助ドキュメント(d)を生成し、この変数について周辺化することで応答(a)に関する分布を得る。当然、この計算は困難であるため、ビームサーチを用いて上記尤度を最大化するようなdを推定値とする(事後確率最大化推定)。生成する際のプロンプトは以下である。
– Open-domain Question Answering “Generate a background document from Wikipedia to answer the given question. \n\n {query} \n\n”
– Fact checking “Generate a background document from Wikipedia to support or refute the statement. \n\n Statement: {claim} \n\n”
– Open-domain Dialogue System “Generate a background document from Wikipedia to answer the given question. \n\n {utterance} \n\n”
生成した補助文書(d)をいわゆる zero-shot reading [Lazaridou2022] によって応答を生成する。プロンプト例は以下である。
– (1) “Refer to the passage below and answer the following question with just a few words. Passage:
{background} \n\n Question: {query} \n\n The answer is”
– (2) “Passage: {background} \n\n Question: {query} \n\n Referring to the passage above, the
correct answer (just one entity) to the given question is”
– (3) “Refer to the passage below and answer the following question with just one entity. \n\n Passage:
background \n\n Question: query \n\n The answer is”
For fact checking and dialogue system, we chose the simplest prompt from P3.
– Fact Checking “{background} \n\n claim: {claim} \n\n Is the claim true or false?”
– Open-domain Dialogue System “{background} \n\n utterance \n\n”
Supervised GenRead
LLMによるテキストの生成はデコーディングアルゴリズムが同一である以上、同じようなテキストになりやすい。そこで多様性を取り入れるために手動でのプロンプト調整による多様性の追加とクラスタリングベースの方法を提案した。クラスタリングベースでは古典的な k-means を用いて生成された補助ドキュメント(d)をクラスタリングし、セントロイドを使用した。(図1)
Experiment
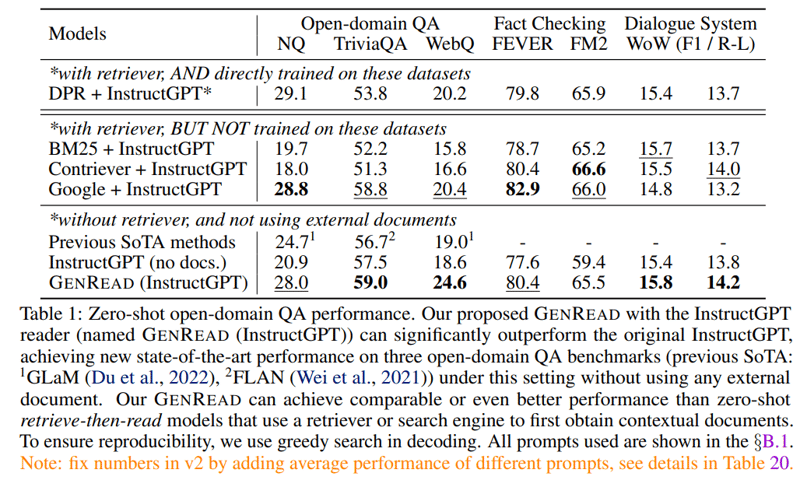
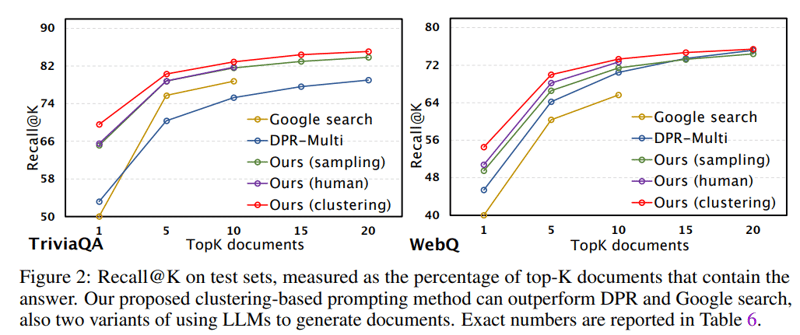
GenReadは従来のRetrieve-then-ReadのDPRを上回る結果となり、google検索を上回る場合もあった。
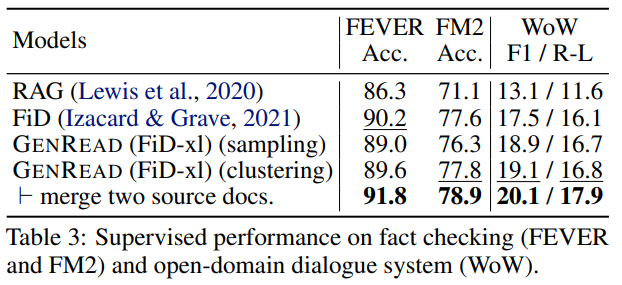
Fact Checkingのタスク(FEVER, FM2)ではデータセットによってはdense retrieverだけで十分な情報を回収できる場合、従来手法より精度が下がる場合があった。
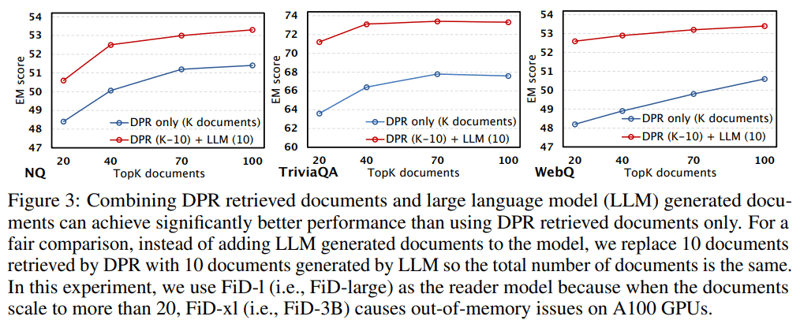
DPRによる文書取得に加えて context generator が生成した文書(d)を加えた方が明らかに精度は高くなっている。(図3)
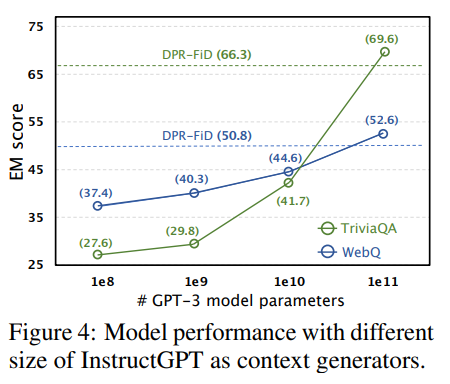
context generator のモデルサイズと EM score の推移。retriever やresponse generator とは別にスケーラビリティによる恩恵を受けることができる。
Posted on December 24, 2023
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.