survey: Enhancing Retrieval-Augmented Large Language Models with Iterative Retrieval-Generation Synergy

Tutty
Posted on January 7, 2024
選定理由
EMNLP2023採択。MSRAのAzure AIチームと Tsinghua University (清華大学)の共同研究。
Paper: https://openreview.net/forum?id=QtOybganmT&referrer=%5Bthe%20profile%20of%20Minlie%20Huang%5D(%2Fprofile%3Fid%3D~Minlie_Huang1)
Code: N/A
RAGに関するサーベイ論文[Gao2023]でも Iterative Retrieval の手法の1つとして言及されている。
概要
【技術課題】
質問1つに対して検索を1回しか行わない Naive-RAG は複雑な要求を持つ質問文(multi-hop reasoning や long-form question)に対して、正しく回答を行うことが難しい。又、文書リポジトリが巨大で、ノイズとなる文書が多い場合は検索結果の文書集合は low recall, low precision になり、hallucination を誘発しやすい[Gao2023]
【提案】
情報検索と応答生成を反復的に実行することにより、質問文に対してより関連性の高い文書集合へと徐々に近づけていくITER-RETGEN (Iterative Retrieval-Generation)を提案。
【効果】
ITER-RETGENは、multi-hop reasoning(多段推論), Fact Verification(事実検証), Commonsense Reasoning(常識推論) といった複雑なタスクにおいて、柔軟にパラメトリックな知識(モデルが学習した知識)とノンパラメトリックな知識(外部から取得した知識)の両方を活用することができる。RAG関連手法のベースラインより高精度であり、さらに検索や生成のオーバーヘッドを低減化した。
Iterative Retrieval-Generation

ITER-RETGEN は、与えられた質問(q)に対して、必要な情報が含まれる検索コーパス(D)から情報を検索し、LLMを使用して t 反復目の回答(y)を t-1 反復目の生成結果を用いて生成するプロセスを繰り返す(式1)
![]()
多くのNLPタスクでは、質問に答えるために必要な情報が、(部分タスクを解くための)サブクエスチョンに答えることによってのみ明らかになることがある。反復を繰り返すうちに、前回の反復で生成された出力を用いて、このセマンティックギャップを埋め、より関連性の高い情報を検索することが可能になる。本研究ではサブクエスチョンの生成にCoTを使用するが、CoTより高度な思考ステップ推論(ToT等)やリファイン手法を組み合わせる点は今後の研究課題とする。
![]()
Retriver は dense retriver を用いている。検索時のスコアの計算は式2を用いた。(この式からわかるようにエンコードするパラメータが二種類存在する two tower architectureの課題があるが、本研究ではこの課題を扱わない)
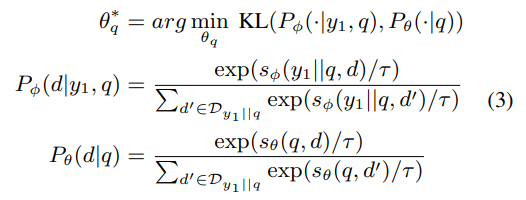
多くの場合、Reranker は Retriver よりクエリと文書の関連性をよく捉える知識を持っている。そこで、知識蒸留法を用いてRerankerからRetriever へ知識転移を行った(式3)。
実験
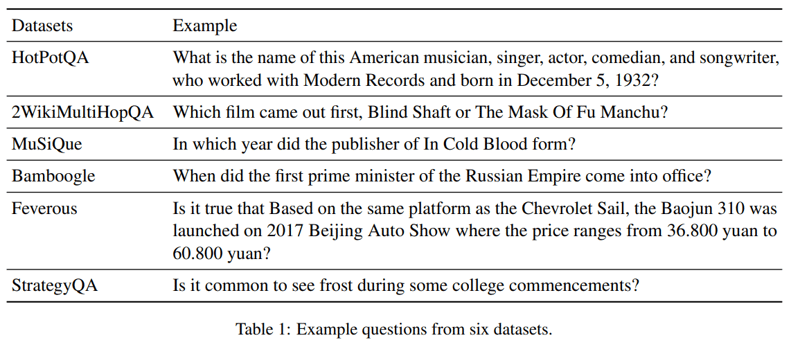
multi-hop reasoning(多段推論), Fact Verification(事実検証), Commonsense Reasoning(常識推論)の3つのタスクで表1のような様々なデータセットで評価した。表1は質問文サンプルである。比較対象となるベースラインは表2にあるように、Direct Prompting, CoT Prompting, ReAct, Self-Ask, DSP である。
GeneratorはGPTの text-davinci-003 と Llama-2 で、デコーディングは greedy を使用した。Retriever は Contriever-MSMARCO を使用し、Re-ranker はTART[Asai2022] を用いた。
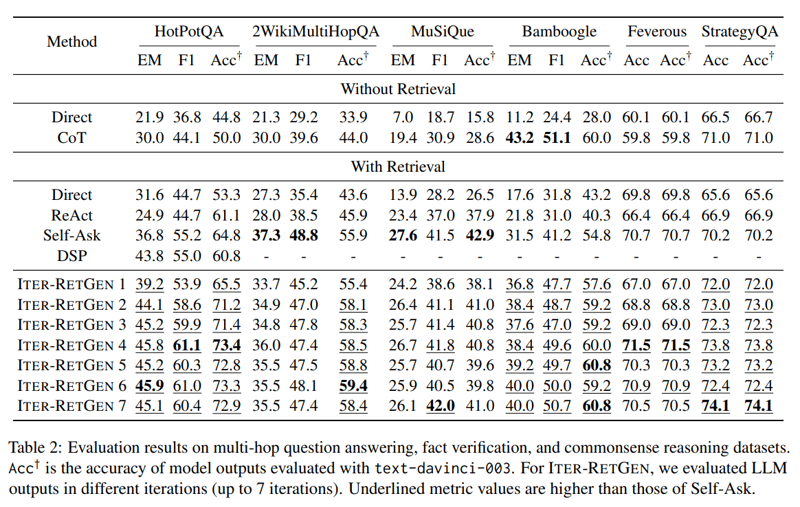
メインの実験結果は表2である。多くのタスク・データセットにおいて、ITER-RETGEN が上回っているのがわかる。反復数の増加とともに改善するが、特に2回目の反復における改善幅が大きい。
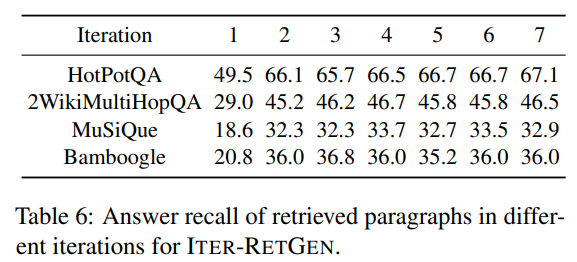
recallでの評価は表6であり、こちらでも2反復目で大きく改善しているのがわかる。
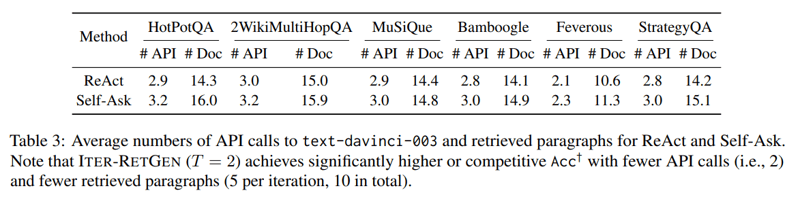
表3が示すように ITER-RETGEN はAPIのコール回数も少なく、ランニングコストを抑えることもできる。
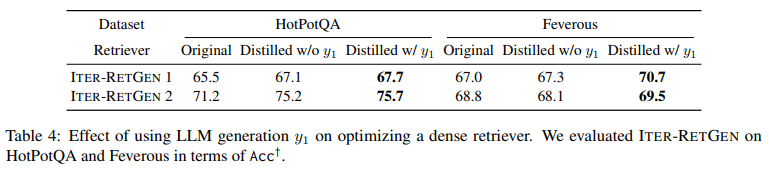
知識蒸留によるAccの改善効果を検証したのが表4である。知識蒸留時に質問文(q)を使用する方がより効果があった。

生成結果のサンプルは表7である。赤い文字は hallucination であるが、反復することで修正されているのがわかる。
エラー解析では必要な情報の取得には成功したが、正しい推論ができなかったケースは10%であった。一方で、エラーの65%は検索に関連しており、そのうち76.9%では、最初の推論が大きく間違っているため次の検索が誤った方向に誘導されているのが観察された。
Posted on January 7, 2024
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related




November 30, 2024