Smooth Sailing With Simulcast

Tasha
Posted on March 2, 2023

Daily powers real-time audio and video for millions of people all over the world. Our customers are developers who use our APIs and client SDKs to build audio and video features into applications and websites.
This week at Daily, we are writing about the infrastructure that underpins everything we do. This infrastructure is mostly invisible when it is working as intended. But it's critically important and we're very proud of our infrastructure work.
Our kickoff post this week goes into more detail about what topics we’re diving into and how we think about our infrastructure’s “job to be done.” Feel free to click over and read that intro before (or after) reading this post. You also can listen to our teammate Chad, a Solutions Engineer extraordinaire here at Daily, who's sharing videos on topics throughout the week.
Today, we'll talk about video simulcast. Simulcast is a technique for delivering the best possible video quality during a multi-participant call.
The most important thing we do at Daily is ensure a reliable video call experience for our customers' customers. We view it as critically important that video calls work well all the time, for users on every device, anywhere in the world, for all possible use cases.
A mature, well-tuned, flexible simulcast implementation is a big part of delivering a high-quality video experience. Simulcast is the single most powerful tool that WebRTC developers have for adapting to bandwidth and CPU constraints.
We've had simulcast support in the Daily platform since 2017 and have devoted thousands of engineering hours to improving our simulcast implementation and tracking the observed, real-world video quality and reliability increases that result. In our opinion, a well-designed video platform should provide heavily tested, robust, adaptive simulcast configurations that work well for a wide variety of use cases, and also allow complete configuration of simulcast for applications that have specific needs. Much more on these topics, below!
Given Daily's long-standing experience with simulcast, we thought it would be fun to take a step back and write an overview of why simulcast matters and how we think about simulcast from the perspective of video engineering and API architecture.
We try to cover a lot of ground, here. This post discusses:
- How group video calls work
- Video routing, SFUs, and implementing simulcast at the infrastructure level
- Upstream and downstream bandwidth requirements
- Application-level use of simulcast
- Future video codec capabilities
Our Solutions Engineer colleague Chad has posted a video walkthrough of these topics here. If you have questions or are interested in discussing any of this in more detail, please feel free to start a thread on the peerConnection WebRTC community forum.
Group video calls, or the problem of that one user with a bad connection
To understand why simulcast is helpful, we need an example of the real-world challenge that simulcast addresses.
Imagine a video call with three participants. Two have fast, stable Internet connections. The third participant has limited bandwidth and can only send and receive relatively low-quality video.
This is a very common situation. A participant's Internet connection may be slow for the entire length of a session, or may just be slow for part of a session. If you don't do anything to compensate for a slow connection, the user on that slow connection will see frozen video or black video frames.
There are three general approaches to accommodating participants with slow network connections:
- Use a low-bitrate video setting for everyone, all the time. This is simple to implement. But the obvious drawback is that video quality is limited for everyone, all the time.
- Dynamically adjust everyone's video bitrate to accommodate the slowest client. This is better, but still penalizes the user experience of all participants.
- Send multiple video streams, at different quality levels, and allow slower participants to receive a lower-bitrate stream when necessary. This is simulcast.

Video routing and SFUs
Daily's real-time audio and video capabilities are built on top of a standard called WebRTC. For more about WebRTC, and Daily's infrastructure in general, see our Global Mesh Network post from yesterday.
As a quick refresher, there are two ways to route video in a WebRTC session: directly between participants or by relaying through a media server. Daily supports both types of routing (and you can even switch between them during a live session). However, because peer-to-peer routing can't scale beyond a few participants in a call, the vast majority of our video minutes are routed through our media servers.
The WebRTC specification is flexible enough that there are many ways to design media servers. This ability to support a wide variety of use cases (and innovation and experimentation) is a strength of WebRTC!
Over the past few years, though, an approach called “selective forwarding” has become the standard used by almost all WebRTC platforms. Simulcast and selective forwarding have evolved together as WebRTC usage has grown.
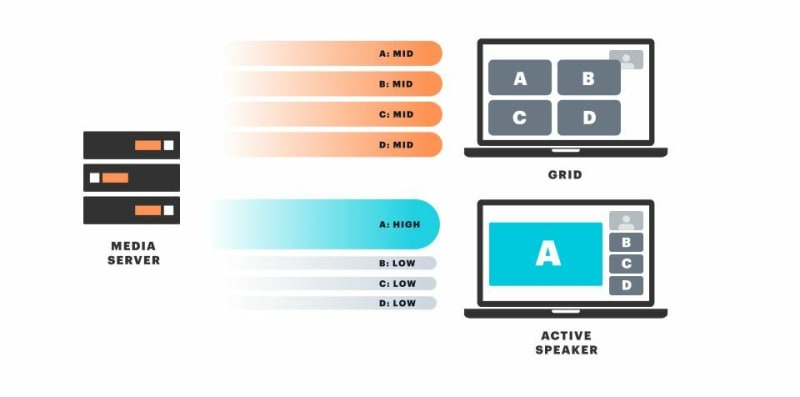
A media server that implements selective forwarding can receive multiple media streams from each participant and then dynamically — selectively — forward all, some, or none of those streams to the other participants. In the WebRTC world, we call this kind of media server a Selective Forwarding Unit, or SFU.
One way to think about the SFU architecture is that the SFU's job is to support smart client-side code.
SFUs enable clients to choose which streams to receive (and to switch between different streams quickly). Giving clients control over stream selection is an important building block for bandwidth and quality management. It's also important for implementing features like breakout rooms, active and passive participant roles, and switching between active speaker and grid-layout user interfaces.
How much bandwidth do you need for a video call?
So, let's continue to build up a mental model of how multi-participant video calls work, and how SFUs facilitate both bandwidth management and scaling to large participant counts.
One question we're often asked is, “how much bandwidth do you need for a video call?”
One nice property of the SFU architecture is that you only need to receive video streams for video that is being displayed on the screen. This means you can lower the bitrate of an incoming video stream if you are displaying the video in a smaller tile, without sacrificing quality at all.
Let's unpack that a little bit.
Here's a video call with 7 participants and an active speaker UI layout.

We'd like to display the active speaker at high resolution. Ideally, the video stream at this resolution would take up about 700 kbits/second. The local participant camera view doesn't take up any network bandwidth (we're just displaying the local camera feed). The other five video tiles are quite small, and 80 kbits/second is enough to deliver acceptable quality at a small display size.
Active speaker: 700 kbs Other videos: 5 x 80 kbs Audio: 5 x 40 kbs (*)
Total: 2.6 mbs
Now let's look at the same numbers for 7 participants in a grid layout.
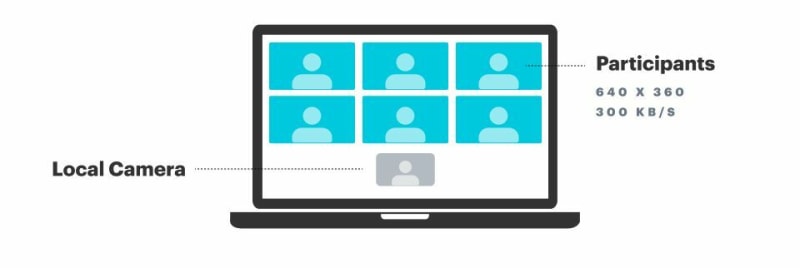
We're displaying each participant at equal size. All of the video tiles have to fit together on one screen, so none of them are rendered at high resolution. A bitrate of 300 kilobits per second is appropriate for these medium-sized video tiles.
All videos: 6 * 300 kbs Audio: 5 * 40 kbs (*)
Total: 2 mbs
If we think about how many participants we want to display on screen at one time in a real-world UI, we can calculate the maximum amount of bandwidth needed for almost any video call. Most video UIs today have a maximum grid view size of 7x7. This is 49 participants visible per "page."
All videos: 49 * 80 kbs Audio: 5 * 40 kbs (*)
Total: 4.1 mbs
So this is a good answer for how much bandwidth is needed to support the largest video sessions: 4.1 mbs downstream. (Note that we can reduce the bandwidth requirement by displaying fewer video tiles on the screen at once. 49 tiles is a lot!)
It's also useful to calculate the upstream — sending — bandwidth needed. We can do that by thinking through how simulcast supports these three examples. In the active speaker case, we need two video bitrates available: 700 kbs and 80 kbs. In the 7 participant grid view, we need a bitrate in between those two.
So upstream from each client, we'll need the following bandwidth.
Simulcast video high quality: 700 kbs
Simulcast video middle quality: 300 kbs
Simulcast video low quality: 80 kbs Audio: 40 kbs
Total: 1.1 mbs
Crucially, this "configuration" of simulcast bitrates also allows us to support participants on slower connections. Let's go back to the active speaker example. Here we can downgrade the active speaker video from 700 kbs to 300 kbs to save bandwidth, and then if that's not enough, all the way to 80 kbs. At 80 kbs the active speaker video will be noticeably pixelated. But it will still display on almost any network connection – there will not be blank tiles or frozen frames.

Active speaker: 80 kbs Other videos: 5 x 80 kbs Audio: 5 x 40 kbs (*)
Total: 680 kbs
Similarly, on the sending side, if we detect that there's not enough bandwidth to send all three video streams, we can send two streams, or even just one (low-bitrate) stream.
(*) Note about audio bitrates. For almost all use cases, it makes sense to limit the number of audio streams that are streamed and played. Most of the time on a typical video call, only a handful of people will be unmuted at once. In addition, Chrome and Safari play a limited number of audio streams in parallel. So we can generally assume that we'll only need about 5 separate audio streams at any time.
Implementing simulcast
Let's look at a few more considerations as we continue to think about how simulcast helps us ensure a reliable and high-quality user experience, support a variety of use cases, and scale sessions to large numbers of participants.
First, let's introduce a new piece of terminology. So far we've talked about SFUs routing video and audio “streams.” When we're discussing simulcast, specifically, we usually talk about simulcast “layers.” A simulcast layer is one encoding of a video source (a “track”). Each layer is sent over the network as a separate RTP stream, but conceptually it makes sense to think about the layers as alternative versions of the same source track.
Configuring simulcast layers
A client that is using simulcast to send video needs to decide how many layers to use and needs to configure a few properties for each layer. The most important properties are the target encoding bitrate, target framerate, and resolution.
If you're using a helper library or an SDK, the library should provide sensible defaults that work for most use cases. A good SDK will also let you configure simulcast settings yourself, though it's important to be careful when experimenting with layer configurations.
There are lots of non-obvious considerations, browser bugs, and long-tail issues, so testing heavily across browsers and under various network conditions is crucial before shipping new configurations to production!
At Daily, our default simulcast layer configuration on desktop devices is three layers, with target bitrates pretty close to the ones we sketched from first principles in the previous section. On mobile devices, Daily's client SDKs default to two layers.
Daily's SDKs also allow you to specify arbitrary layer configurations for any video stream. Our solutions support team often helps customers think through, implement, and test these configurations. We log per-session and per-participant metrics that allow for both debugging individual session issues and tracking the aggregate impact of simulcast configuration changes.
Based on our experience supporting a wide range of use cases, we're experimenting with a higher-level abstraction that makes it easier to switch on the fly between simulcast configurations. Internally, we're calling this “video quality profiles.” Stay tuned for more, soon.
Selecting a layer to receive
On the sending side, a stream will usually consist of multiple layers. But on the receiving side, a stream just looks like a single layer!
There are different ways to think about this, from an API design perspective. In general, the most useful approach is to specify which layer we'd prefer to receive for each stream. When there's not enough bandwidth to receive all of our preferred layers, the SFU will automatically send us some lower-bitrate layers.
A helper library, SDK, or component framework can also make some common patterns easier to implement. For example, a library can automatically detect when a video tile is small and call an internal method to set a lower bitrate layer preference.
Best practices bandwidth recommendations
It's important for applications to be proactive about using as little bandwidth as possible. For example, as noted above, an app should switch to receiving a low bitrate simulcast layer whenever a small video tile is used.
The percentage of users who experience real-world issues with video and audio tracks pretty closely with how much bandwidth an app uses.
At Daily, we capture anonymized logs and metrics from all of the video sessions we serve. So we have a lot of empirical data about the long tail of issues that real-world users experience.
Based on our data, we recommend the following best practices:
- default to sending at or below one megabit per second
- limit initial receive-side bandwidth to three megabits per second or less
- monitor packet loss and switch to a lower bitrate mode if there is significant packet loss
- monitor cpu usage and if cpu usage is too high, take steps to reduce it
It's worth talking a little more about that last item, CPU usage. Most video issues can be traced back to a poor network connection (packet loss or low available bandwidth). But high CPU usage is a secondary cause of quality and reliability problems.
High CPU usage usually traces back to one of three things:
- In a web application, doing lots of work on the JavaScript main thread will cause noticeable video performance issues. In the worst case, a busy main thread will also cause slow network performance and web socket disconnections. The most common bug of this kind that we see is a super-busy React render loop. This can be a hard issue to track down and fix, but if you know what you're looking for in the React dev tools it's a very easy issue to identify.
- On older devices, rendering high-resolution video can be challenging. This is one reason that we recommend a maximum video resolution of 1280x720 (not 1920x1080). For more information about video resolution, see our Call Quality Guide.
- Rendering multiple videos can use a lot of CPU. It's important to receive the lowest-resolution simulcast layer that's appropriate for the video tile size, because decoding lower resolution video takes much less CPU. It's also useful to monitor CPU usage and automatically fall back to rendering fewer videos, if possible. Zoom, for example, limits the number of videos displayed per page in grid mode on lower-powered devices.
Server-side simulcast implementation details
The SFU's job is to seamlessly switch between simulcast layers as needed. The mechanical part of this job is (relatively) simple. The SFU just rewrites RTP packet headers and video frame headers so that the receiver has enough metadata to interpret and decode each frame.
But there are two open-ended, complicated, "there be dragons" topics that stretch the brain cells of people who implement SFUs. These are important to get right, and good code in these areas plays a big part in how well an SFU delivers the best possible performance for real-world clients, at scale.
First, bandwidth management. The SFU is responsible for deciding how much bandwidth is available downstream to each client (bandwidth estimation), and for falling back to lower-bitrate layers as necessary (the management part).
The preferred approach to bandwidth estimation, today, is Transport-wide Congestion Control, also called transport-cc or TWCC. A mechanism for reporting on packet timings for transport-cc is part of the WebRTC standard. But exactly how an SFU makes use of the timing information to estimate available bandwidth is not standardized.
Google Chrome's transport-cc code is open source, and is the basis for the transport-cc implementations in a number of other open source projects. In general, bandwidth estimation continues to be an active area of development, experimentation, and research.
Second, scaling to thousands of participants in a session involves optimizing the performance of core SFU code, developing coordination mechanisms so that multiple SFUs can cooperate to manage sessions and route packets, and tying all of that together with devops tooling that can manage big distributed clusters of lots of SFUs. This is a big topic in its own right. See our post about Daily's Global Mesh Network for some notes on designing and operating WebRTC infrastructure at scale.
Video codecs of today and tomorrow
So far, we've completely glossed over what the video “streams” and “layers” we've been talking about actually are. We often use the terms streams and layers interchangeably because the main distinction between the two is how the video codec and the networking stack coordinate to send media over the wire to the SFU. In general, when we design APIs we try to hide some of this complexity. But it's worth briefly discussing video codecs.
Today, two video codecs are supported by all WebRTC implementations: VP8 and H.264. These codecs are standard, mature, very widely used, and quite similar.
Both VP8 and H.264 work well for low-latency video, though both codecs need to be tuned specifically for low-latency use cases. Implementing simulcast encoding in a CPU-efficient way is particularly important (and tricky). Google's VP8 simulcast implementation is used in Chrome, Edge, and Safari and is quite good. As a result, most WebRTC platforms use VP8 for calls with large numbers of participants. (For 1:1 calls, where simulcast is less important, H.264 can be an equally good choice.)
VP8 and the H.264 Constrained Baseline Profile that is most widely supported by WebRTC implementations can include what video engineers call temporal scalability within a single encoded layer. This means that it's possible to simply drop some frames to reduce the frame rate and bitrate of the video. In other words, you get multiple bitrates for free from a single encoding, with the limitation that the multiple bitrates are achieved by lowering the frame rate.
Neither VP8 nor H.264 Baseline support spatial scalability directly. Spatial scalability is the same thing as video resolution. So to support, for example, both a high-bitrate 1280x720 stream and a lower-bitrate 640x360 stream, it's necessary to encode the video twice. Which explains why we use simulcast for our WebRTC sessions.
There is a newer generation of Scalable Video Codecs that can pack both temporal and spatial scalability into a single encoding. This makes simulcast unnecessary and saves significant network bandwidth! At the network level, SVC layers are packaged into one stream. So with SVC, the SFU just chooses which frames to forward to a particular user rather than switching between several different simulcast layers.
The drawback is that these new codecs require too much CPU for general-purpose use, today. However, implementations are steadily getting more efficient, hardware in general is getting faster, and hardware support for new codecs is increasing. Today, these new codecs can be used in some circumstances (often in combination with logic to fallback to VP8 or H264). Over time, VP9, H.265/HEVC, AV1 and perhaps other, even more advanced Scalable Video Codecs will gradually replace VP8 and H.264, and simulcast will become a historical curiosity.
Conclusion
We've written a lot of words, here, but we've barely scratched the surface of topics like layer configuration, bandwidth estimation, and how video codecs work. For example, we didn't even mention keyframes. Keyframes are a favorite topic of video engineers everywhere. But they'll have to wait for another post.
As always, if you have questions, thoughts, or comments (including about keyframes), please come over to the peerConnection WebRTC community and start a thread.
Posted on March 2, 2023
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related

November 29, 2024