Streaming SIMD in JS

Tracy Gilmore
Posted on August 20, 2023

In my previous post on this topic I described how we could use the concept behind SIMD to enhance JS performance. The implementation was limited to using a single data array/vector. In the implementation that follows, I have taken inspiration from Streaming SIMD Extensions (SSE) to extend my implementation to support multiple data streams.
Things to know before reading this post.
Quick recap of sim-simd
My simd() function takes a regular function as its only parameter and returns a new function instrumented for SIMD operation. The simd-version of the function returned, expects one or more homogeneous (all of the same data type) arguments. When called, the original function will be applied to each parameter (using a map method) but with the execution performed inside their own Promise to leverage the benefit of concurrent execution. The allSettled Promise method is used to collate the results, that are returned from the function, in an array.
export default function simd(instruction) {
return function (...data) {
const executions = data.map(
datum =>
new Promise((resolve, reject) => {
try {
resolve(instruction(datum));
} catch (error) {
reject(error);
}
})
);
return Promise.allSettled(executions);
};
}
NB, the execution interface will be changing to support multiple data feeds. Although they are different things, the 'data feeds' can be streams, vectors or regular arrays in the case of JS.
Enhanced SIMD (esimd)
Being able to process multiple data feeds at the same time raises a significant question but also offers a considerable opportunity.
What does the function do if the data feeds (arrays) are of different lengths?
In my mind there are three options, which we will call no-cache, cached and matrix execution modes.
export const ExecutionMode = {
NO_CACHE: 0,
CACHED: 1,
MATRIX: 2,
};
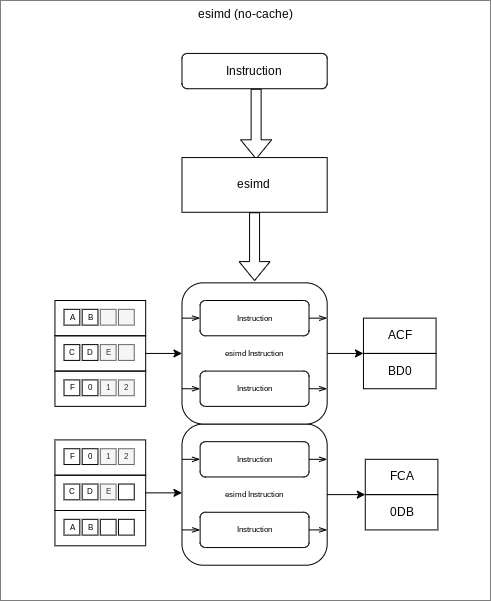
- No-cache is by far the simplest as we only use what data we can and disregard the rest. This might seem wasteful but in time critical applications this might be the best option.
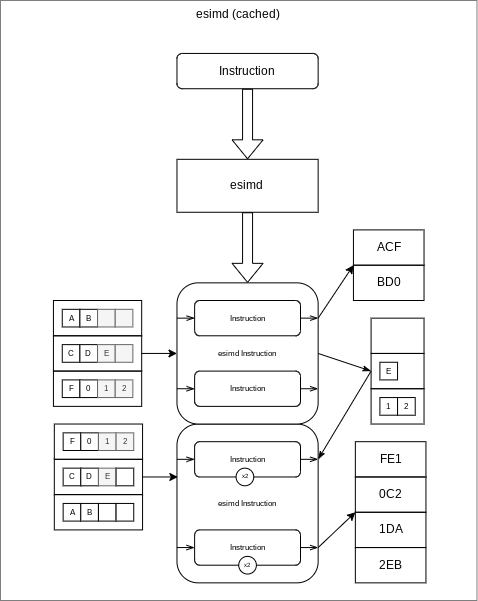
- Cached retains any unused values to prepend them to the beginning of the next wave of data. Data is not lost but there has to be an upper limit and a way to clear the cache.
- Finally we have the Matrix execution mode, which could be very effective. In this mode all the data is used because the original function is applied with every combination of input values.
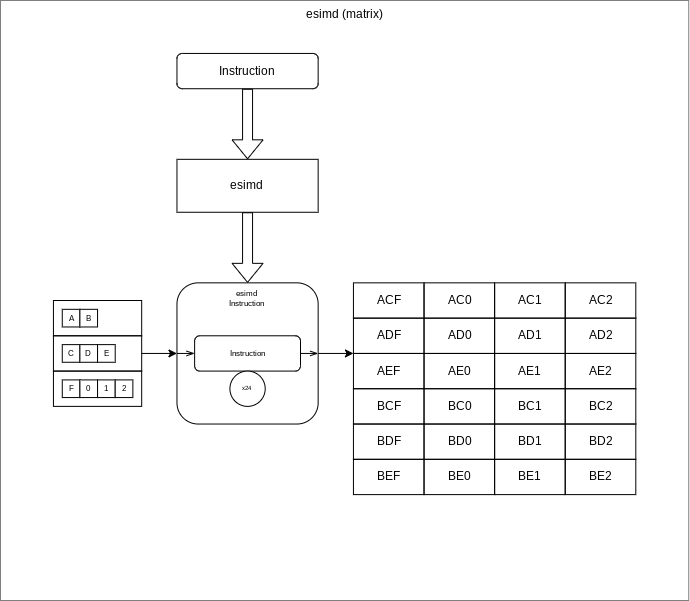
For example, if the original function expects two parameters and its esimd version is presented with [2, 3], [4, 5], the original function would be called 4 times in total with the following arguments: (2, 4), (2, 5), (3, 4) & (3, 5). If the original function was a simple multiplication, its esimd function would return the following 2-dimensional array: [[8, 10], [12, 15]]. Similar to its simpler cousin, all four operations will be executed in concurrently courtesy of Promises.
Exceptions
The number of data feeds needs to match the number of parameters expected by the original function, otherwise an exception will be thrown. If one of the executions of the instruction fails (status !== "fulfilled") an exception will also be raised, but if execution of the instruction results in an exception the return status will be "rejected" and the value undefined.
In matrix mode there are three additional exceptions to limit resource consumption from:
- too many dimensions stipulated for the matrix (default max 10)
- too large a dimension stipulated for the matrix (default max 10)
- too great a resultant matrix (default max 10,000 values)
Testing
As illustrated by the graphic at the head of this post, we will be exercising each of the three modes described above by passing in an instruction (function) that excepts three inputs (characters) and returns the values concatenated into a string. However, after converting the instruction process into an enhanced-simd (esimd) version (esimdInstruction) we will pass in the data as arrays of characters. The test instruction is defined in such a way that, should the concatenated string be '666' an exception will be thrown.
The test instruction and data
// process.js (CJS module)
async function process(a,b,c) {
const result = `${a}${b}${c}`;
if (result === '666') {
throw Error('Number of the beast');
}
return result;
}
// Un-exceptional test data (imported JSON)
[
["A", "B"],
["C", "D", "E"],
["F", "0", "1", "2"]
]
// Exceptional test data
const testData = [
["A", "6", "B"],
["C", "6", "D", "E"],
["F", "6", "0", "1", "2"]
];
Reference the unit tests in my GitHub repository so see how these were used to exercise the source code.
Implementation
The following section will demonstrate the construction of the function to deliver each of the three modes described above, individually. We will conclude the section by combining the code to manage all three modes on demand. In preparation we will start by reviewing some of the supplementary code.
Supplementary code
The following four code fragments are used, in combination, at the core of the three modes. Extracting these functions will greatly simplify the functions fro each mode.
executeInstruction
If the following fragment of code appears familiar, it should. It is at the heart of the simd implementation and is responsible for converting an instruction (fnInstruction) and a dataset (array) argument into a Promise.resolve, or a Promise.reject should the function fail (throw an exception).
function executeInstruction(fnInstruction) {
return (dataset) =>
new Promise(async (resolve, reject) => {
try {
resolve(await fnInstruction(...dataset));
} catch (error) {
reject(error);
}
});
}
The above function is used by all three modes to perform the operation and generate the Promise.
transform
Both the no-cache and cached modes need to convert the data before it is processed. Instead of an array for each argument, we need a set of arrays, each containing a value for each argument.
For example, instead of the two arrays containing the data feeds ['A', 'B'] and ['C', 'D'] where each array contains the values for a specific argument, we want ['A', 'C'] and ['B', 'D'] so each array contains a single value for each argument. This rotation of the arrays are performed by the transform function, with the swapRowColumn (sub)function performing the replacement of rows for columns.
function transform(fn, dataSources, caches) {
const swapRowColumn = (_, row) =>
row.map((__, i) => [...(_[i] || []), row[i]]);
return cacheSurplus(caches, dataSources)
.reduce(swapRowColumn, [])
.map(executeInstruction(fn));
}
The cacheSurplus function used in transform is described next.
cacheSurplus
This function performs two operations, which I accept conflicts with the Single Responsibility principle, but the two operations are closely related.
First we need to extract the groups of data from the input to feed the arguments of the instruction. The second operation is to preserve any excess data in a cache and prefix it to the next feed, where required (caches is populated).
function cacheSurplus(caches, dataFeeds) {
const dataFeedSize = dataFeeds.reduce(
(feedSize, dataFeed, index) => {
if (caches) dataFeed.unshift(...caches[index]);
return Math.min(feedSize, dataFeed.length);
},
Infinity
);
const newCache = dataFeeds.map((dataFeed) =>
dataFeed.splice(dataFeedSize));
if (caches) {
caches.length = 0;
caches.push(...newCache);
}
return dataFeeds;
}
permute
The permute function contains a recursive function _permute that generates a multi-dimensional array of Promises. The array is flattend into a single dimensional array so it can be used with the Promise.allSettled method.
By multi-dimensional array I mean a set of nested arrays. One dimension has no nesting and can be imagined as a simple list. Two dimensions (2D) form an array of arrays, that can be visualised as a plain, rectangle or grid. A 3D array is an array of arrays of arrays, and is analogous to a solid-box, or array of grids. Trying to visualise more than 3 dimensions gets rather difficult, but by now you probably see the pattern.
function permute(fn, dataFeeds) {
const dataFeedLength = dataFeeds.length;
return _permute().flat(dataFeedLength - 1);
function _permute(...buffers) {
const buffersLength = buffers.length;
return buffersLength === dataFeedLength
? executeInstruction(fn)(buffers)
: dataFeeds[buffersLength].map((dataFeed) =>
_permute(...buffers, dataFeed)
);
}
}
Notice that the permute function calls the executeInstruction indirectly using partial-application, where a call to executeInstruction with the instruction function (fn) to create a new function executeFn.
No-Cache mode
In my preparation for this post I decided to develop the code for each mode individually although the cached mode is built on the no-cache mode because they are so similar.
function esimd(instruction) {
return async function (...dataSources) {
const executions = transform(instruction,
structuredClone(dataSources));
const results = await Promise.allSettled(executions);
return results.map((result) => result.value);
};
}
The no-cache example is relatively simple. Like all of the esimd modes, it started by taking in a function that is the instruction we want to perform of the data sets, and returns a function in a typical closure pattern. The 'esimd'-ised version of the instruction is based on Promises so operates _async_hronously and is expected to be called with the name number of array arguments as the number instruction parameters.
The executions variable is the result of transforming the input arrays (one per parameter) into a collection of arrays, one per execution containing a single set of arguments. The structuredClone function is new to JS and is used to duplicate the data so the original source is not mutated by esimd. The transform function does more than rearrange the values into argument sets, it also executes to instruction that generates a Promise, the result being an new array of Promises for each complete set of arguments.
In the no-cache version of esimd any data that cannot be used to form a complete argument set is discarded. We then await the results to be settled using the Promise.allSettled method and extract the values to return to the caller. There are a number of exceptions that we can manage, as described above, but we will leave discussing those for now and only consider the 'happy path'.
Cached mode
The cached mode builds on the no-cache version with the main difference being we include a caches array (of arrays) to retain any data that did not form part of a complete argument set. The caches is passed into the transform function where that values can be prefixed to the new data feeds.
function esimd(instruction) {
let caches = [...Array(instruction.length)].map((_) => []);
return async function (...dataSources) {
const executions = transform(
instruction,
structuredClone(dataSources),
caches
);
const results = await Promise.allSettled(executions);
return results.map((result) => result.value);
};
}
Matrix mode
Supporting matrix mode is very different to the previous two modes. Here we try to use very permutation (permute) of the argument arrays, as described much earlier. Otherwise the actual esimd function is extremely simple.
function esimd(instruction) {
return async function (...dataSources) {
const executions = permute(instruction,
structuredClone(dataSources));
const results = await Promise.allSettled(executions);
return results.map((result) => result.value);
};
}
Bringing it all together
With a single function to manage all three modes we need a way to inform the function which mode to use. This is indicated by the second parameter executionMode of the initial call, which (is optional, defaulting to no-cache) uses one of three values provided by the ExecutionMode object (pseudo-enumeration). We, optionally, initialise a caches array depending on the mode and execute either the permute or transform function, again depending on the mode of execution.
function esimd(
instruction,
executionMode = ExecutionMode.NO_CACHE
) {
const caches =
executionMode === ExecutionMode.CACHED
? [...Array(instruction.length)].map((_) => [])
: null;
return async function (...dataSources) {
checkAlignment(instruction, dataSources);
checkCapacity(executionMode, dataSources);
const executions = (
executionMode === ExecutionMode.MATRIX
? permute : transform
)(instruction, structuredClone(dataSources), caches);
const results = await Promise.allSettled(executions);
validateResults(results);
return results.map((result) => result.value);
};
}
In this final version we also include some protection against anticipated exception conditions:
-
checkAlignmentensures the number of data sources matches the number of parameters of theinstructionfunction. -
checkCapacityattempts to protect the computer from managing matrix operations that are too large in terms of source data or the expected result output. -
validateResultsflags up when any of theinstructionexecutions resulted in an error/exception.
The source code for this post can be found in my GitHub repository. However, it is not up to production grade and should only be used for educational purposes.
Besides the obvious support for multiple data feeds, there are two significant differences between enhanced-simd and sim-simd.
-
The simulated edition returns the result of the
Promise.allSettledin its unrefined form, which might be confusing for some developers. Instead of an array of return values, they will receive an array of objects containing properties of:-
status('fulfilled' or 'rejected') indicating if the function was successful or not. -
valueis the actual return value from the function call. -
reasonis included only if the function was 'rejected' and states the cause of the failure.
-
To protect the developer and the system, there is far more use of exception handling and reporting. We need to make sure that, if the input provided is going to impact system performance, we are aware of it prior to it affecting end users. We, as developers, can then make a determination as to how best to manage it.
Another minor difference between the two implementations is that simd is provided as an ES6 module but esimd is coded using the Common JS module approach. It is a minor issue to change from CJS to ESM but the unit testings is a little more complicated and adds nothing to the topic at hand.
I have included unit tests in the GitHub repo to aid understanding on how esimd can be used. The unit tests include several that exercise the asynchronous function such that it throws an exception. I found this unit test quite challenging, but this Dev.to post from Alessio Michelini was exceptional useful.
Update April 1st, 2024 (no fooling)
In response to a comment I received on this topic, I had previously confused the term parallel with concurrent in the context of processing models. I have, hopefully, now corrected the error in this and the previous article but it also raises an interesting point for this article.
Whilst JS is, by default, single threaded, especially in the browser where it is primarily concerned with updating the DOM and responding to user actions, there is a Web API called Web Workers that can provide additional threads of execution.
Web Worker enable computationally intensive activity to be conducted away from the main thread, which reduces the potential impact on the user experience by having the browser blocking interaction. I would advise that the architecture of an application should first try to relocate such processing to the server but this might be a reasonable trade-off in some circumstances.
In order to make use of Web Workers in a SIMD fashion, it would be necessary to replace the function parameter with the URL of a JS script, prepared in a particular way. The SIMD wrapper could then fame out the work over a number of threads. This would utilise more than one processor on the machine, adopting a more parallel module of execution rather than concurrent.
If you would like an article (and code) demonstrating how this could be achieved, please leave a comment below.
Posted on August 20, 2023
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related


