Getting Started With Kafka with Node JS

Chundru Teja
Posted on February 26, 2023
Getting Started With Kafka with Node JS

This is the part 1 of the series , this part let’s understand the kafka
Why Kafka?
Kafka solves several problems that arise in traditional messaging systems :-
Scalability: Designed to scale horizontally, which means that you can add more brokers to the cluster to increase throughput. This is in contrast to other messaging systems, which are typically limited to a single server.
Reliability: Designed to be fault-tolerant. With techniques such as message acknowledgments and replicas, ensuring that messages are delivered even in the presence of failures.
Performance: Designed to be fast. It uses a log-structured storage system and a custom TCP protocol to achieve high throughput. This is in contrast to other messaging systems, which typically use a queue-based system. Learn more from the video :- https://youtu.be/UNUz1-msbOM
Complexity: Designed to be simple. It uses a simple consumer model with a publish-subscribe messaging paradigm and stores messages on disk. It provides a simple and straightforward API.
What is Kafka mainly used for?
Real-time data streaming : Kafka is distributed streaming platform that can handle real-time data feeds , that can be used to build real-time data pipelines and streaming apps.
Log aggregation: Kafka can be used to aggregate logs/events from multiple sources, making it easier to analyse and process large amounts of log data.
Microservices communication : Kafka can be used to in a microservices architecture. It can be used to decouple services and enable asynchronous communication between them. It can also be used to build event-driven systems.
Web analytics :- Kafka can be used to build a data pipeline for collecting, aggregating, and analysing web activity data and metrics. This was the original use case at LinkedIn that led to its creation.
Ok , Now that we know why and what Kafka is used for
Let’s us familiarize ourselves with the basic terminologies of Kafka :-
Cluster: The collective group of machines that Kafka is running on. Kafka uses quorum based replication to ensure fault tolerance. This means that each partition has a leader and zero or more followers. The leader handles all read and write requests for the partition. The followers replicate the leader. If the leader fails, one of the followers will automatically become the new leader. If the old leader comes back online, it will join the follower as a follower. This way, we ensure that we don’t lose any messages in the event of a failure.
https://cwiki.apache.org/confluence/display/KAFKA/Kafka+Replication
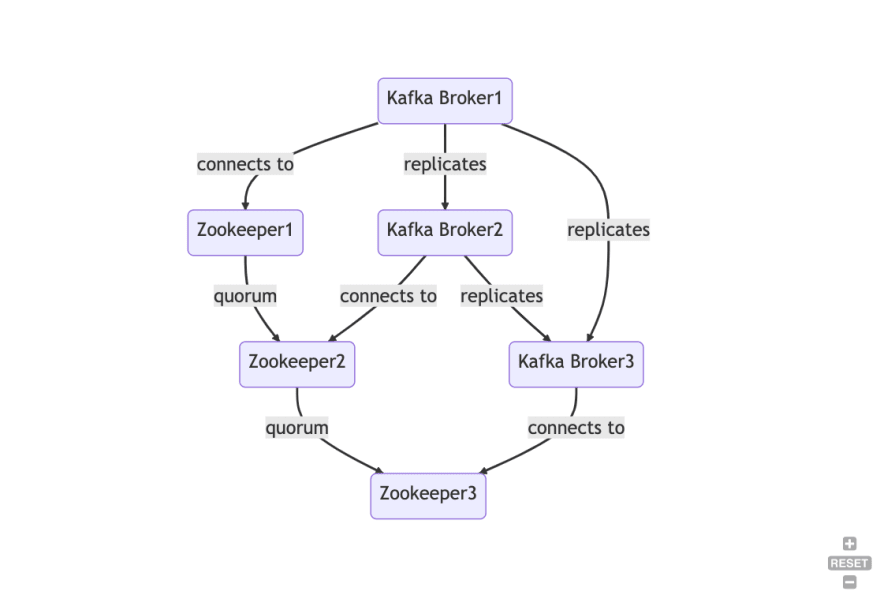
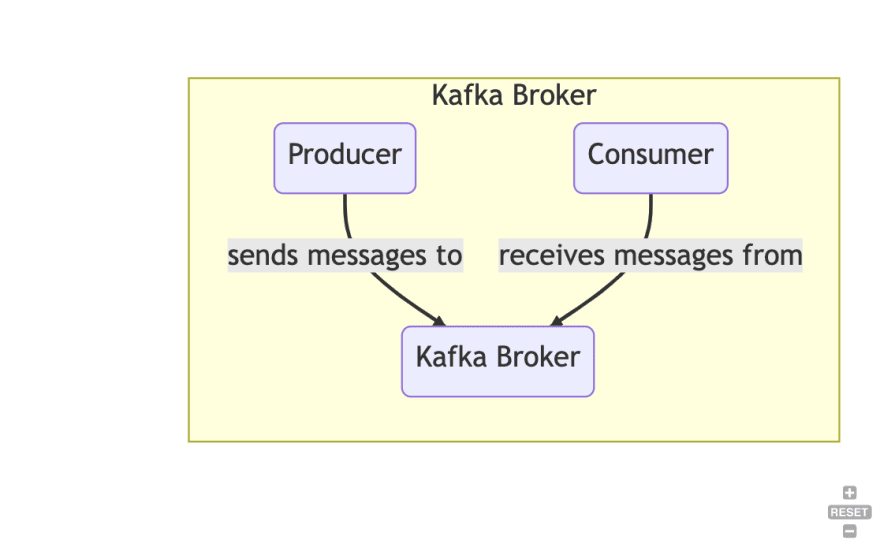
Broker: A single Kafka instance is called a broker. A Kafka cluster is made up of multiple brokers. Each broker is identified by a unique ID called a broker ID.
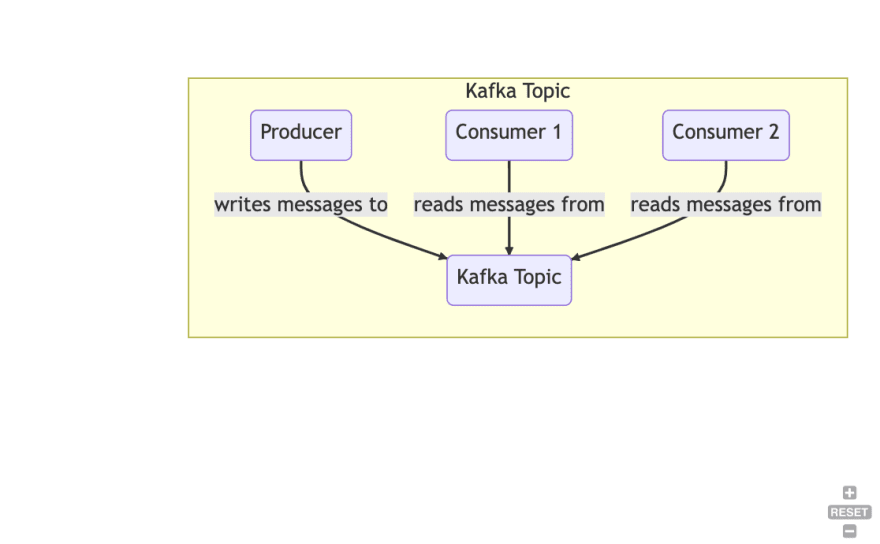
Topic: Topics are used to organize data. You always read and write to and from a particular topic
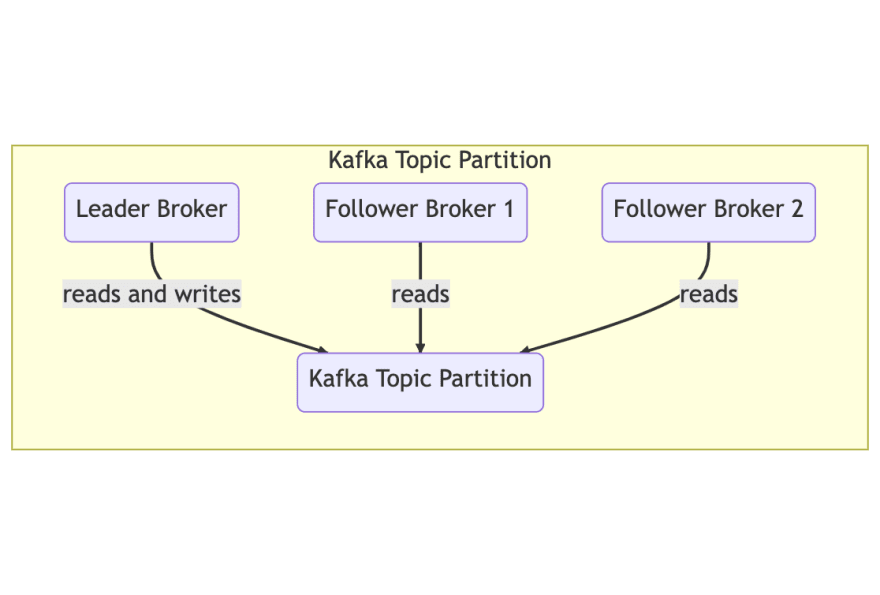
Partition: Data in a topic is spread across a number of partitions. Each partition can be thought of as a log file, ordered by time. To guarantee that you read messages in the correct order, only one member of a consumer group can read from a particular partition at a time.
Producer: A client that writes data to one or more Kafka topics
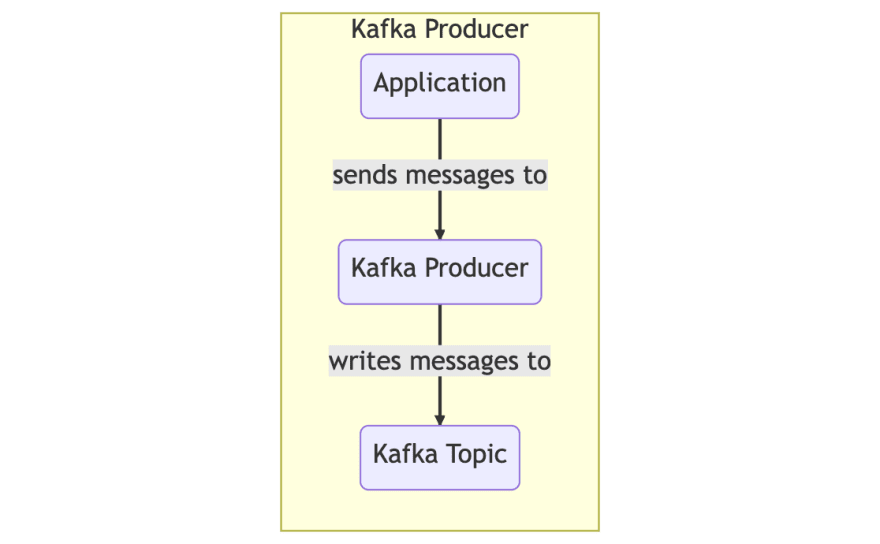
Consumer: A client that reads data from one or more Kafka topics

Replica:Partitions are typically replicated to one or more brokers to avoid data loss.
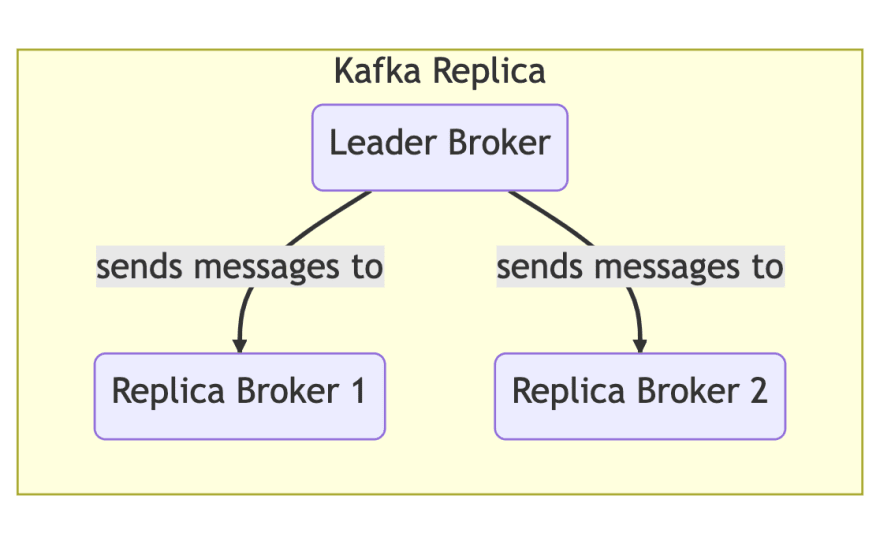
Leader: Although a partition may be replicated to one or more brokers, a single broker is elected the leader for that partition, and is the only one who is allowed to write or read to/from that partition

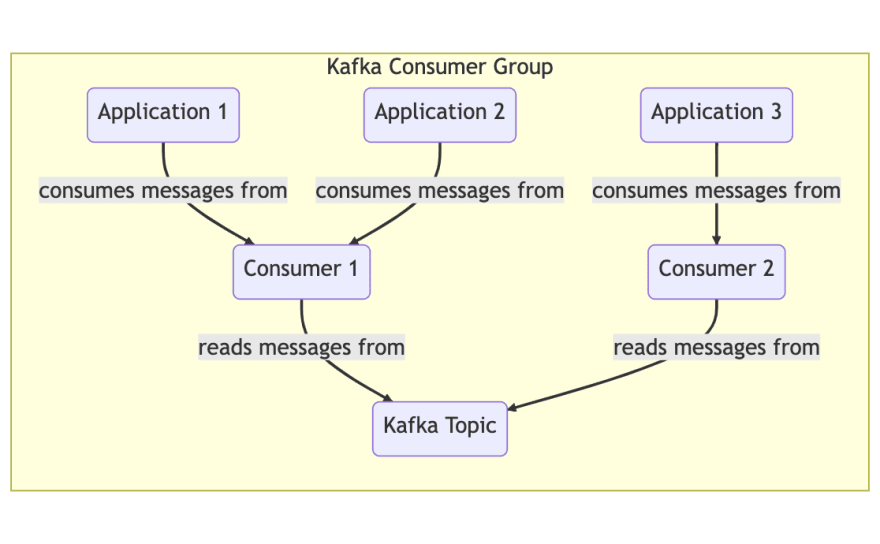
Consumer group: A collective group of consumer instances, identified by a groupId. In a horizontally scaled application, each instance would be a consumer and together they would act as a consumer group.
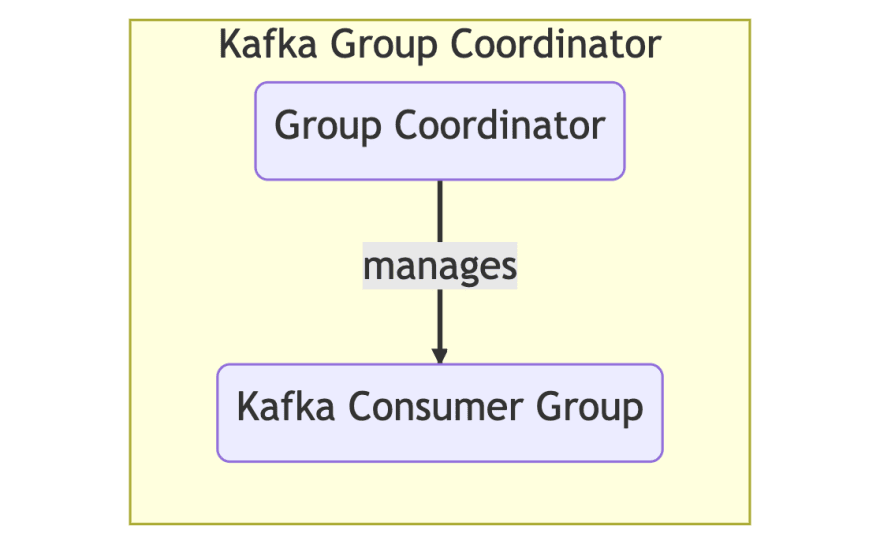
Group Coordinator: An instance in the consumer group that is responsible for assigning partitions to consume from to the consumers in the group
Offset: A certain point in the partition log. When a consumer has consumed a message, it “commits” that offset, meaning that it tells the broker that the consumer group has consumed that message. If the consumer group is restarted, it will restart from the highest committed offset.
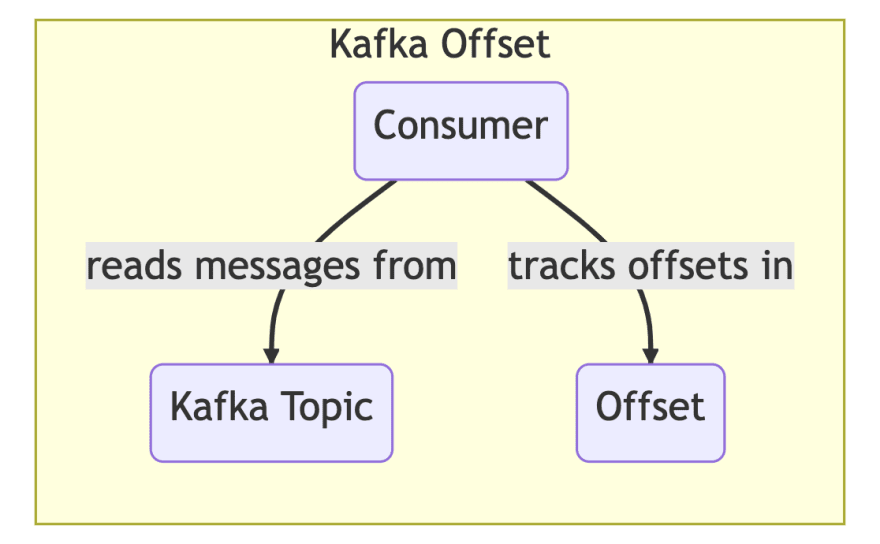
Rebalance : When a consumer has joined or left a consumer group (such as during booting or shutdown), the group has to “rebalance”, meaning that a group coordinator has to be chosen and partitions need to be assigned to the members of the consumer group.

Heartbeat: The mechanism by which the cluster knows which consumers are alive. Every now and then (heartbeatInterval), each consumer has to send a heartbeat request to the cluster leader. If one fails to do so for a certain period (sessionTimeout), it is considered dead and will be removed from the consumer group, triggering a rebalance.
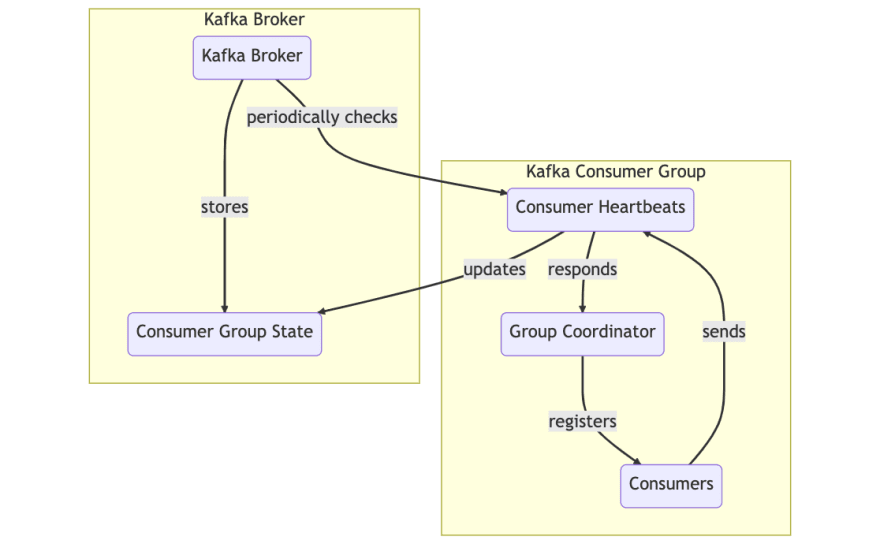
Reference : https://kafka.js.org/docs/introduction#glossary
Overall Message Flow :
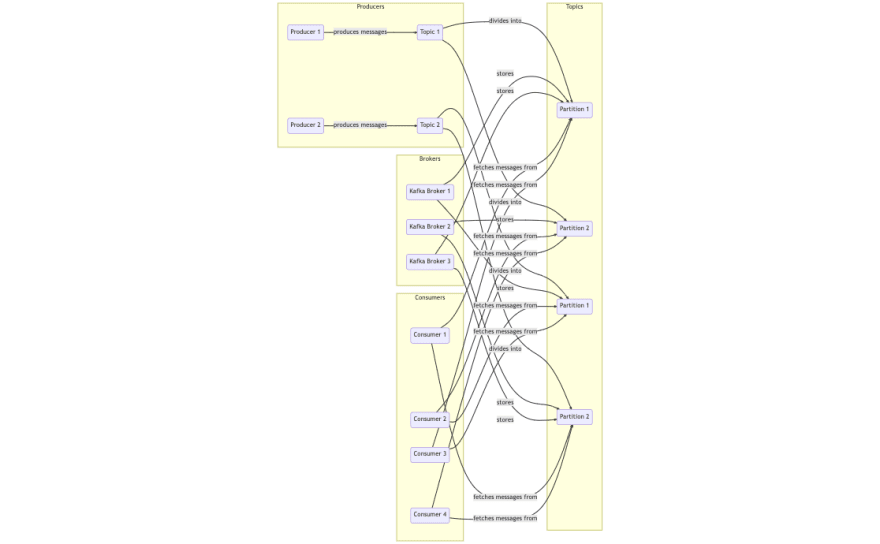
So this is the part 1 of the series , in the part 2(Coming Soon) of the series let’s get our hands dirty with the code.
References :-
https://kafka.js.org/docs/introduction
https://developer.confluent.io/learn-kafka/architecture/get-started/
Posted on February 26, 2023
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related
