Why a SQL Statement Often Consists of Hundreds of Lines, Measured by KBs?

Sushrut Mishra
Posted on March 11, 2023
Obviously, one of the original purposes of SQL is to make data query processing easy. The language uses many English-like terms and syntax in an effort to make it easy to learn, particularly for non-IT people. Simple SQL statements read like English, and even people without any programming experience can write them.
However, the language becomes clumsy as query needs become even slightly more complicated. It often needs hundreds of rows of multilevel nested statements to achieve a computing task. Even professional programmers often find it hard to write, let alone the non-IT people. As a result, such computing tasks become the popular main question in programmer recruitment tests of many software companies. In real-world business situations, the size of SQL code for report queries is usually measured by KBs. The several-line SQL statements only exist in programming textbooks and training courses.
SQL problem analysis
What is the reason behind the sheer bulk of the code? Let’s try to find the answer, that is, SQL’s weaknesses, through an example.
Suppose we have sales performance table sales_amount consisting of three fields (date information is omitted to make the analysis simpler):

We are trying to find salespeople whose sales amounts rank in top 10 in terms of both air conditioners and TV sets.
The task is not difficult. It is easy for us to think of the following natural computing process:
- Sort the sales performance table by sales amount of air conditioners and get the top 10;
- Sort the sales performance table by sales amount of TV sets and get the top 10;
- Perform intersection operation on step 1 and step 2’s result sets to get the final result.
Let's try to solve it in SQL.
Early SQL did not support stepwise coding. The first two steps had to be written in subqueries, and the whole process looked a little complicated:
select *from (select top 10 sales from sales_amount where product='AC' order by amount desc) intersect (select top 10 sales from sales_amount where product='TV' order by amount desc)
The language later identified the issue and specifically offers CTE syntax, which uses WITH keyword to name an intermediate result set that can be referenced in subsequent parts of the computation:
withAas select top 10 sales from sales_amount where product='AC' order by amount desc Bas select top 10 sales from sales_amount where product='TV' order by amount desc select *fromA intersect B
The statement is still long but becomes clearer.
Now, we make the task a little harder. We will find salespeople whose sales amounts for all products rank in top 10. It’s easy to think up the following algorithm according to the above solution:
- List all products;
- Find salespeople whose sales amounts rank in top 10 for each product and store them separately;
- Calculate the intersection between all top-10 result sets.
The problem is that CTE only works when the number of intermediate results is already known. In this case, we do not know the number of products. This means that the number of clauses under WITH keyword is indefinite and we are not able to write the statement.
Let’s try a different approach:
- Group the original table by product, sort each group, and find top 10 records meeting the specified condition in each group;
- Calculate intersection of all top 10 records.
But it requires to store the grouping result in step 1. The intermediate result is a table where one field will store the top 10 of members in each group, which means the field values will be sets. As SQL does not support set-type values, the solution becomes infeasible.
If we have window functions at hand, we can switch to another route. It will group the original table by product, calculate the number of appearances of every salesperson in the top 10 sales amounts of each group, and find those whose total appearances are equal to the number of products – they are the ones whose sales amounts rank in top 10 for all products.
select sales from( select sales, from( select sales, rank()over(partition by product order by amount desc ) ranking from sales_amount) where ranking <=10) group by sales having count(*)=(select count(distinct product) from sales_amount)
This way we are able to accomplish the computing task in SQL. But such a complicated SQL statement is beyond most users.
As the first two simple algorithms cannot be implemented in SQL, we have to adopt the roundabout third one. This reveals one important weakness of SQL - insufficient set-orientation.
Though SQL has the concept of sets, it does not offer them as a basic data type. A variable or field in the SQL context cannot have set type values. The only set type SQL object is table. This results in roundabout algorithms and complicated code for the large number of set-oriented calculations.
The keyword top is used in the above SQL sample programs. Actually, there isn’t such an operator in relational algebra (but it can be constructed using a series of other operations), and the code is not standard SQL.
Let me show you how difficult it is when the top keyword is not available for finding top N.
Here’s the general way of thinking: For each member, get the number of members where the sales amounts are greater than the current amount, define ranking of the current salesperson according to the number, and get members whose rankings are not greater than 10. Below is the SQL query:
select sales from( select A.sales sales,A.product product, (select count(*)+1 from sales_amount where A.product=product ANDA.amount<=amount) ranking from sales_amount A) where product='AC'AND ranking<=10
Or
select sales from( select A.sales sales,A.product product,count(*)+1 ranking from sales_amount A, sales_amount B where A.sales=B.sales and A.product=B.product ANDA.amount<=B.amount group by A.sales,A.product ) where product='AC'AND ranking<=10
Even professional programmers find it hard to write. The code is too complicated for such a simple top 10 computation.
Even if SQL supports the keyword top, it can only solve top N problem conveniently. If the task becomes a bit more complex, such as getting members/values from the 6th to the 10th and finding salespeople whose sales amounts are 10% higher than their directly next, the above problems still exist and we have to resort to a roundabout way if we still trying to achieve it in SQL.
This is due to SQL’s another key weakness – lack of order-based syntax. SQL inherits mathematical unordered sets, which is the direct cause of difficulties in handling order-based calculations that are prevalent in real-world business situations (such as calculating link relative ratio, YOY, top 20%, and rankings).
SQL2003 standard adds window functions to try to improve the computing ability for dealing with order-based calculations. They have enabled simpler solutions to the above computing tasks and helped mitigate this SQL problem. However, the use of window functions is usually accompanied by nested queries, and the inability to let users access members of a set directly according to their positions leaves many order-based calculations hard to solve.
Suppose we are trying to find the gender ratio among the above top salespeople by calculating the number of females and that of males. Generally, the gender information of salespeople is recorded in employee table instead of the sales performance table, as shown below:

As the list of top salespeople is available, our first thought might be finding their genders from the employee table and then count the numbers. To achieve this cross-table query, SQL needs a table join. So, the SQL code following the above top 10 task is:
select employee.gender,count(*) from employee, (( select top 10 sales from sales_amount where product='AC' order by amount desc ) intersect ( select top 10 sales from sales_amount where product='TV' order by amount desc ))A where A.sales=employee.name group by employee.gender
Only one table join has already made the code complicated enough. In fact, related information is, on many occasions, stored in multiple tables and often of multilevel structure. For instance, salespeople have their departments and the latter has managers, and we might want to know the managers under whom those top salespeople work. A three-table join is needed to accomplish this, and it is not easy to write smooth and clear WHERE and GROUP for this join.
Now we find out the next SQL weakness – lack of object reference mechanism. In relational algebra, the relationship between objects is maintained purely by foreign keys match. This results in slow data searching and the inability to treat the member record in the related table pointed by the foreign key directly as an attribute of the current record. Try rewriting the above SQL as follows:
select sales.gender,count(*) from(…)// … is the SQL statement for getting the top 10 records of salespeople group by sales.gender
Apparently, this query is clearer and will be executed more efficiently (as there are no joins).
The several SQL key weaknesses shown through a simple example are causes of hard to write and lengthy SQL statements. The process of solving business problems based on a certain computational system is one that expressing an algorithm with the syntax of a formalized language (like solving word problems in primary school by transforming them into formalized four arithmetic operations). The SQL defects are great obstacles to translation of solutions computing problems. In extreme cases, the strangest thing happens – the process of converting algorithms to syntax of a formalized language turns out to be much harder and more complicated than finding a solution.
In other words, using SQL to compute data is like using an assembly language to accomplish four arithmetic operations – which might be easier to understand for programmers. A simple formula like 3+5*7 will become as follows if it is written in an assembly language, say X86:
mov ax,3 mov bx,5 mul bx,7 add ax,bx
Compared with the simple formula 3+5*7, the above code is complicated to write and hard to read (it is even more difficult when fractions are involved). Though it may be not a big deal for veteran programmers, it is almost unintelligible for most business people. In this regard, FORTRAN is a great invention.
Our examples are simple because I want you to understand my point easily. But real-world computing tasks are far more complicated, and users will face various SQL difficulties. Several more lines here and a few more lines there, it is therefore no wonder that SQL generates multilevel nested statements of hundreds of lines for a slightly complicated task. What’s worse, often the hundreds of lines of code are a single statement, making it hard to debug in terms of engineering aspect and increasing difficulty in handling complex queries.
More examples
Let’s look at SQL problems through more examples.
In order to simplify the SQL statement as much as possible, the above sample programs use many window functions and thus the Oracle syntax that supports window functions well. Syntax of the other databases will only make the SQL statement more complicated.
Even for these simple tasks that are common in daily analytic work, SQL is already sufficiently hard to use.
Unordered sets
Order-based calculations are prevalent in batch data processing (such as getting top 3 or record/value in 3rd position, and calculating link relative ratio). SQL switches to an unusual way of thinking and take a circuitous route because it cannot perform such a calculation directly thanks to its inheritance of the concept of mathematical unordered sets.
Task 1: Find employees whose ages are equal to the median.
select name, birthday from(select name, birthday,row_number()over(order by birthday) ranking from employee ) where ranking=(select floor((count(*)+1)/2) from employee)
Median calculation is common, and the process is simple. We just need to sort the original set and get the member at the middle position. SQL’s unordered-sets-based computational mechanism does not offer position-based member access method. It will invent a field of sequence number and select the eligible members through a conditional query, where subqueries are unavoidable.
Task 2: Find the largest number days when a stock rises consecutively.
select max(consecutive_day) from(select count(*)(consecutive_day from(select sum(rise_mark)over(order by trade_date) days_no_gain from(select trade_date, case when closing_price>lag(closing_price)over(order by trade_date) then 0else1END rise_mark from stock_price)) group by days_no_gain)
Unordered sets also lead to tortuous ways of solving problems.
Here is the general way of doing the task. Set a temporary variable to record the number of consecutive rising days with the initial value as 0, compare the current closing price with the previous one, reset the variable’s the current value as 0 if the price does not rise and add 1 to it if the price rises, and get the largest number when the loop is over.
SQL cannot express the algorithm and it gives an alternative, which first counts the non-rising frequency for each date from the initial one to the current one. The dates that have the same frequency contain prices rising consecutively. Then it groups these dates to get continuously rising intervals, counts members in each, and finds the largest number. It is extremely difficult to understand and even more hard to express.
Insufficient set-orientation
There is no doubt that sets are the basis of batch data processing. SQL is a set-oriented language, but it can only express simple result sets and does not make it a basic data type to extend its application.
Task 3: Find employees whose birthdays are on the same date.
select * from employee where to_char(birthday, ‘MMDD’)in ( select to_char(birthday,'MMDD') from employee group by to_char(birthday,'MMDD') having count(*)>1)
The original purpose of grouping a set is to divide it into multiple subsets, so a grouping operation should have returned a set of subsets. However, SQL cannot express such a “set of sets” and thus cannot help forcing an aggregate operation on the subsets to return a regular result set.
At times, what we need isn’t aggregate values but the subsets themselves. To do this, SQL will query the original set again according to the grouping condition, which unavoidably results in a nested query.
Task 4: Find students whose scores of all subjects rank in top 10.
select name from(select name from(select name, rank()over(partition by subject order by score DESC) ranking from score_table) where ranking<=10) group by name having count(*)=(select count(distinct subject) from score_table)
The set-oriented solution is to group data by subject, sort each subset by score, select top 10 from each subset, and calculate intersection between the subsets. As SQL’s inability to phrase “a set of sets” and support intersection operations on an indefinite number of sets, the language takes an unusual route to achieve the task. It finds top 10 scores in terms of subjects using a window function, group the result set by student, and find the group where the number of students is equal to the number of subjects. The process is hard to understand.
Lack of object reference method
A SQL reference relationship between data tables is maintained through matching foreign key values. Records pointed by these values cannot be used directly as an attribute of the corresponding records in the other table. Data query needs a multi-table join or a subquery, which is complicated to code and inefficient to run.
Task 5: Find male employees whose managers are female.
Through multi-table join:
select A.* from employee A, department B, employee C where A.department=B.department and B.manager=C.name and A.gender='male' and C.gender='female'
Through subquery:
select * from employee where gender='male' and department in (select department from department where manager in (select name from employee where gender='female'))
If the department field of the employee table is the foreign key pointing to records of the department table and the manager field of the department table is the foreign key that points to records of the employee table, the query condition can be written in the following simple, intuitive and efficient way:
where gender='male' and department.manager.gender='female'
SQL can only use a multi-table join or a subquery to generate difficult to understand statements.
Task 6: Find the companies where employees obtained their first jobs.
Through multi-table join:
select name, company, first_company from(select employee.name name, resume.company company, row_number()over(partition by resume. name order by resume.start_date) work_seq from employee, resume where employee.name = resume.name) where work_seq=1
Through subquery:
select name, (select company from resume where name=A.name and start date=(select min(start_date) from resume where name=A.name)) first_company from employee A
SQL is also unable to treat the sub table as an attribute (field) of the primary table because it lacks object reference method and has inadequate set-orientation. A query on the sub table uses either a multi-table join, which makes the statement particularly complex and needs to align the result set to records of the primary table in a one-to-one relationship through a filtering or grouping operation (since records of the joining result set has such a relationship with the sub table), or a subquery that calculates ad hoc the subset of records of the sub table related to each record in the primary table one by one – which increases amount of computations (the subquery cannot use the WITH subclause) and coding difficulty.
SPL as the solution
SQL problems need to have a solution.
Actually, the above analysis implies a way out. That is, designing a new language that gets rid of those SQL weaknesses.
And this is the original intention of creating SPL.
SPL is the abbreviation for Structured Process Language while SQL’s full name is Structured Query Language. It is an open-source programming language intended to facilitate structured data computations. SPL emphasizes orderliness and supports object reference method to achieve complete set-orientation, sharply reducing the difficulty of “algorithm translation”.
Here we just present SPL code of the 6 tasks in the previous section, giving you a glance of the language’s elegance and conciseness.
Task 1

Task 2

It is easy for SPL to code an intuitive and direct algorithm.
Task 3

SPL keeps result set of the grouping operation to further process it as it handles a regular set.
Task 4

SPL writes the code smoothly as the intuitive algorithm unfolds.
Task 5

With the support of object reference, it is convenient for SPL to access a field of the record pointed by the foreign key as it gets one of its original fields.
Task 6

SPL allows treating a set of records of the sub table as a field of the primary table and accesses it in the same way of getting its other fields, avoiding repeated computations on the sub table.
SPL has an intuitive IDE that offers convenient debug functionalities to track each step for processing a query, making coding even easier.
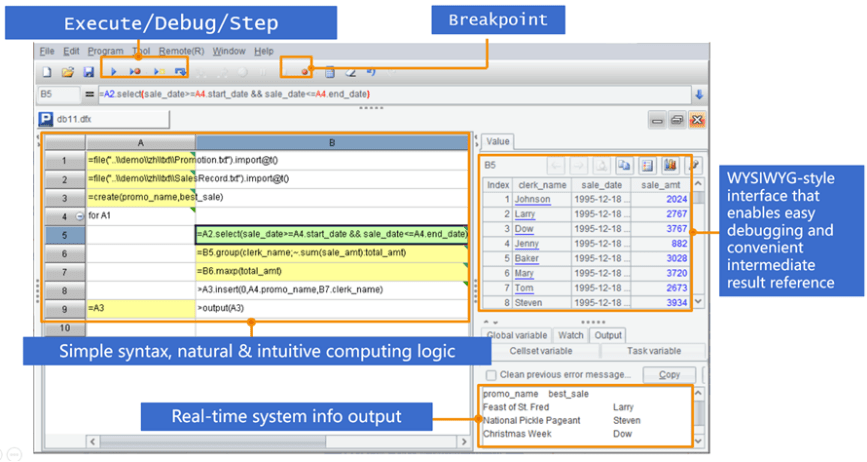
For a computation within an application, SPL offers the standard JDBC driver to be integrated with the application, such as JAVA, as SQL does:
… Class.forName("com.esproc.jdbc.InternalDriver"); Connection conn =DriverManager.getConnection("jdbc:esproc:local://"); Statement st = connection.(); CallableStatement st = conn.prepareCall("{call xxxx(?,?)}"); st.setObject(1,3000); st.setObject(2,5000); ResultSet result=st.execute(); ...
Posted on March 11, 2023
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related



