Apache Spark with java

J S SUNIL
Posted on October 29, 2022

What is Apache spark:
Apache Spark is a data processing framework that can quickly perform processing tasks on very large data sets, and can also distribute data processing tasks across single node or cluster of nodes.
Why Apache Spark:
Fast processing – Spark contains Resilient Distributed Dataset (RDD) which saves time in reading and writing operations, allowing it to run almost ten to one hundred times faster than Hadoop.
Flexibility – Apache Spark supports multiple languages and allows the developers to write applications in Java, Scala, R, or Python.
In-memory computing – Spark stores the data in the RAM of servers which allows quick access and in turn accelerates the speed of analytics.
Real-time processing – Spark is able to process real-time streaming data. Unlike MapReduce which processes only stored data, Spark is able to process real-time data and is, therefore, able to produce instant outcomes.
Better analytics – In contrast to MapReduce that includes Map and Reduce functions, Spark includes much more than that. Apache Spark consists of a rich set of SQL queries, machine learning algorithms, complex analytics, etc. With all these functionalities, analytics can be performed in a better fashion with the help of Spark.
Terminologies of Spark:
Spark Application: The Spark application is a self-contained computation that runs user-supplied code to compute a result. A Spark application can have processes running on its behalf even when it’s not running a job.
Task: A task is a unit of work that sends to the executor. Each stage has some task, one task per partition. The Same task is done over different partitions of RDD.
Job: The job is parallel computation consisting of multiple tasks that get spawned in response to actions in Apache Spark.
Stage: Each job divides into smaller sets of tasks called stages that depend on each other. Stages are classified as computational boundaries. All computation cannot be done in a single stage. It achieves over many stages.
Components of Spark Run-time Architecture:
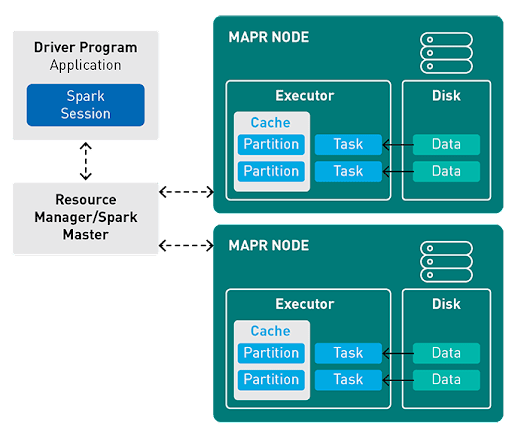
Diver: The main() method of the program runs in the driver. The driver is the process that runs the user code that creates RDDs, and performs transformation and action, and also creates SparkContext.
Cluster Manager: Spark relies on cluster manager to launch executors. It is a pluggable component in Spark. On the cluster manager, jobs and action within a spark application scheduled by Spark Scheduler in a FIFO fashion. The resources used by a Spark application can dynamically adjust based on the workload. This is available on all coarse-grained cluster managers, i.e. standalone mode, YARN mode, and Mesos coarse-grained mode.
-
Executors: The individual task in the given Spark job runs in the Spark executors. Executors launch once in the beginning of Spark Application and then they run for the entire lifetime of an application. Even if the Spark executor fails, the Spark application can continue with ease. There are two main roles of the executors:
- Runs the task that makes up the application and returns the result to the driver.
- Provide in-memory storage for RDDs that are cached by the user.
Apache Spark provides 3 different API's for working with big data
* RDD
* DataFrame
* DataSet

- Spark RDD: RDD stands for “Resilient Distributed Dataset”.
It is the fundamental data structure of Apache Spark. RDD in Apache Spark is an immutable collection of objects which computes on the different node of the cluster.
Resilient, i.e. fault-tolerant with the help of RDD lineage graph(DAG) and so able to recompute missing or damaged partitions due to node failures.
Distributed, since Data resides on multiple nodes.
Dataset represents records of the data you work with. The user can load the data set externally which can be either JSON file, CSV file, text file or database via JDBC with no specific data structure.
- Spark DataFrame:
Spark Dataframes are the distributed collection of the data points, but here, the data is organized into the named columns. They allow developers to debug the code during the runtime which was not allowed with the RDDs.
Dataframes can read and write the data into various formats like CSV, JSON, AVRO, HDFS, and HIVE tables. It is already optimized to process large datasets for most of the pre-processing tasks so that we do not need to write complex functions on our own.
- Spark DataSet:
A Dataset is also a SparkSQL structure and represents an extension of the DataFrame API. The Dataset API combines the performance optimization of DataFrames and the convenience of RDDs. Additionally, the API fits better with strongly typed languages.
Later in the year 2016, In Spark 2.0 Dataset and DataFrame merge into one unit to reduce the complexity while learning Spark.
Working with Apache Spark in java
- Installing Apache Spark with maven
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.13</artifactId>
<version>3.3.1</version>
</dependency>
- Installing Apache spark with gradle
dependencies {
compile 'org.apache.spark:spark-sql_2.13'
}
SparkSession vs SparkContext – Since earlier versions of Spark or Pyspark, SparkContext is an entry point to Spark programming with RDD and to connect to Spark Cluster, Since Spark 2.0 SparkSession has been introduced and became an entry point to start programming with DataFrame and Dataset. Since we are working with Spark 2.0 we will be accessing API's using SparkSession only.
- Creating SparkSession
From the above code –
SparkSession.builder() – Return SparkSession.Builder class. This is a builder for SparkSession. master(), appName() and getOrCreate() are methods of SparkSession.Builder.
master() – If you are running it on the cluster you need to use your master name as an argument to master(). usually, it would be either yarn or mesos or Kubernetes depending on your cluster setup.
Use local[x] when running in Standalone mode. Where x represents the no.of CPU cores to use from the host machine.
appName() – Sets a name to the Spark application that shows in the Spark web UI. If no application name is set, it sets a random name.
getOrCreate() – This returns a SparkSession object if already exists. Creates a new one if not exist.
- Mounting data into Apache Spark
There are 2 ways to mount data into Apache Spark
Mount data from in-memory
Read data from files (json, csv, text, binary)
Spark supports three modes while reading a file
PERMISSIVE : sets other fields to null when it meets a corrupted record, and puts the malformed string into the corrupt_records column
DROPMALFORMED : ignores the whole corrupted records.
FAILFAST : throws an exception when it meets corrupted records.
show() is used to display the contents of the DataFrame in a Table Row & Column Format. By default, it shows only 20 Rows and the column values are truncated at 20 characters.
It takes boolean as an argument, show(false) displays full contents of the columns where are show(true) doesn't
- Here is the json we would be working with
Let's say we want to find out people who have first name as Alice and have age more than 24
We can use the filter API on the dataset provided by apache spark
Apache Spark intelligently handles corrupted records and takes action based on the mode set during creation of spark session
Two ways to handle corrupted records:
- Capture corrupted records into a folder
- Filter corrupted records from the dataset
You can find the repo on github. Any suggestions please post them in comments
Will be sharing more on Memory tuning in Apache Spark to handle bigger data in the upcoming blog. So stay tuned
Posted on October 29, 2022
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related