Edgar Codd and The Modern Data Stack

Stefanie Davis
Posted on March 31, 2021

The modern data stack has the obvious definition of “it depends”. Some of the things that determine the data stack include:
- Price
- Size (Terabytes, Petabytes, etc.)
- Company Relationships
- Scale
This is not an exhaustive list. But, it’s what I’ve seen determine the technologies used at different companies from startups to large corporations. It’s almost a given to say these technologies are based in the cloud. This adds to the scalability and programmatic nature of the code used for data. And as there are now three major cloud providers (AWS,GCP, and Azure) engineers adapt to the services provided by these companies. This shift allowed business to scale faster and do more with data. The common phrase is “Storage is cheap and Compute is expensive”. These cloud providers allowed for cheaper compute giving many companies the focus on solving problems with data, at any size. So, who’s going to maintain this influx of data? Some analysts or traditional DBAs skilled up and the programmatic nature called for other engineers to become data engineers.
Google Trends for Big Data
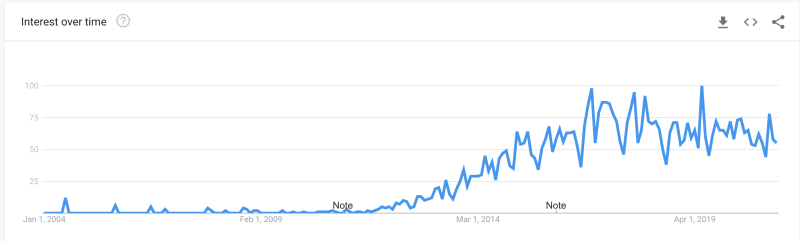
Google Trends for Data Engineer

These are search terms. However, you can see the trend (no pun intended). As big data emerged, the need for someone to maintain the data grew.
What about Codd??
Edgar Codd is known for creating the relational database model and the process of normalization. His name is usually brought up in relation to normal forms (1NF,2NF,3NF,etc). These foundational elements aren’t commonly discussed when evaluating data. But, relational databases are everywhere and you can have your pick. They range from lightweight like sqlite to Oracle or Teradata. These principles exist in Redshift and any other relational database. Codd even coined the term OLAP (Online Analytical Processing). On Top of this foundation exists Business Intelligence, Data Visualization, Data Science, Artificial Intelligence, Machine Learning and more.
The Point: Data Engineers should know SQL and Python, as tools to do the job. However, there’s domain specific foundational knowledge that exists in data. And good data modeling can accomplish more (save money, scale data science, democratize data, ensure data governance, etc.) than writing more code can sometimes. I’ve seen it happen. I’ve made it happen.
Posted on March 31, 2021
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related




