How We Perform Frontend Testing on Our Customer Portal

Thomas Ladd
Posted on November 8, 2019
An effective automated testing strategy is crucial for ensuring teams can deliver quality updates to web applications quickly. We are lucky to have a lot of great options in the space right now for testing. However, with a lot of options comes the difficulty of sorting through which one(s) to pick. Then, once the tools are chosen, you need to decide when to use each one.
At StackPath we're very happy with the level of confidence we've achieved in our customer portal. So, in this post, we will share the set of tools we use to test our customer portal and inspire confidence in its performance.
Testing Principles
Before diving into specific tools, it’s worth thinking about what good tests look like. Prior to starting work on the customer portal, we wrote down the principles we wanted to follow when writing tests. Going through that process first helped us decide which tools to select.
The four principles we wrote down (with a little bit of hindsight thrown in) are listed below.
1. Tests should be thought of as an optimization problem
An effective testing strategy is about maximizing value (confidence in the application working) and minimizing cost (time spent maintaining tests and running tests). Questions we often ask when writing tests related to this principle are:
What’s the possibility that this test actually catches a bug?
Is this test adding value and does that value justify its cost?
Could I derive the same level of confidence as I do from this test with another test that is easier to write/maintain/run?
2. Avoid excessive mocking
One of my favorite explanations of mocking is Justin Searls’s talk at Assert.js 2018. He goes into a lot more detail and subtlety than I will here, but in the talk, he refers to mocking as punching holes in reality, and I think that’s a very instructive way of looking at mocks. While mocking does have a place in our tests, we have to weigh the reduction of cost the mock provides by making the test easier to write and run against the reduction in value caused by punching that hole in reality.
Previously, engineers on our team relied heavily on unit tests where all child dependencies were mocked using enzyme’s shallow rendering API. The shallow rendered output would then be verified using Jest snapshots. All of these sorts of tests followed a similar template:
it('renders ', () => {
const wrapper = shallow();
// Optionally interact with wrapper to get the component in a certain state
expect(wrapper).toMatchSnapshot();
});
These sorts of tests punch a ton of holes in reality. You can pretty easily get to 100% test coverage with this strategy. The tests take very little thought to write, but without something testing all of the numerous integration points they provide very little value. The tests may all pass, but I’m not too sure if my app works or not. Even worse, all of the mocking has a hidden cost that pops up later.
3. Tests should facilitate refactoring—not make it more painful
Tests like the one shown above make refactoring more difficult. If I notice I have the same repeated code over and over again and extract it to another component later, every test I had for components that use that new component will fail. The shallow rendered output is different; where before I had the repeated markup, now I have the new component.
A more complicated refactoring that involves adding some components and removing others results in even more churn as I have to add new test files and remove others. Regenerating the snapshots is easy, but what value are these tests really providing me? Even if they could catch a bug, I’m more likely to miss it amongst the number of snapshot changes and just accept the newly generated ones without thinking too hard about it.
So these sorts of tests don’t help much with refactoring. Ideally, no test should fail when I refactor and no user-facing behavior is changed. Conversely, if I do change user-facing behavior, at least one test should fail. If our tests follow these two rules, they are the perfect tool for ensuring I didn’t change any user-facing behavior while refactoring.
4. Tests should mimic how a user actually uses the application
If I want my tests to only fail when user-facing behavior changes, it follows that my tests ought to interact with my application in the same sort of way an actual user would. For example, my tests should actually interact with form elements and type in input fields the same way a user would. They should never reach into a component and manually call lifecycle methods, set state, or anything else that is implementation-specific. Since the user-facing behavior is what I’m ultimately wanting to assert, it’s logical that the tests should be operating in a way that closely matches a real user.
Testing Tools
Now that we’ve defined what our goals are for our tests, let’s look at what tools we ultimately chose.
Typescript
We use TypeScript throughout our codebase. Our backend services are written in Go and communicate using gRPC, which allows us to generate typed gRPC clients for use in our GraphQL server. The GraphQL server’s resolvers are typed using generated types from graphql-code-generator. Finally, our queries, mutations, and subscriptions components/hooks are also generated with full type coverage. End-to-end type coverage eliminates an entire class of bugs resulting from the shape of data not being what you expect. Generating types from schema and protobuf files ensures our entire system remains consistent across the stack.
Jest (Unit Tests)
We use Jest as our unit testing framework along with @testing-library/react. In these tests, we test functions or components in isolation from the rest of the larger system. We typically test functions/components that are used frequently throughout the app and/or have a lot of different code paths that are difficult to target all of in an integration or end-to-end (E2E) test.
For us, unit tests are about testing the fine-grained details. Integration and E2E tests do a good job of handling the broad strokes of the application generally working, but sometimes you need to make sure little details are correct and it would be too costly to write an integration test for each possible case.
For instance, we want to ensure that keyboard navigation works for our dropdown select component, but we don’t need to verify every instance of it in our app. We test the behavior in depth in isolation so that we can just focus on higher-level concerns when testing the pages that use that component.
Cypress (Integration Tests)
Cypress integration tests are at the core of our testing suite. When we started building out the StackPath portal they were the first tests we wrote because they deliver a lot of value for fairly small cost. Cypress renders our whole app in a browser and runs through test scenarios. Our entire frontend is running exactly as it would for a user. The network layer, however, is mocked. Every network request that would go to our GraphQL server is instead mocked with fixture data.
Mocking the network layer provides a number of benefits:
- Tests are faster. Even if your backend is super fast, the number of calls made for an entire test suite run add up. With the responses being mocked, they can return instantly.
- Tests are more reliable. One of the difficulties with full E2E tests is accounting for variability in the network and stateful backend data. When every request is mocked that variability is gone.
- Hard-to-replicate scenarios can be simulated with ease. For instance, it would be difficult to reliably force calls to fail. If we want to test that our app responds correctly when a call fails, being able to force that failure is helpful.
While mocking our entire backend may seem like a problem, all of our fixture data is typed using the same generated TypeScript types our app uses, so it is guaranteed to be at least structurally equivalent to what an unmocked backend would return. For most of our tests, we are happy with the tradeoff that mocking the network provides.
The developer experience with Cypress is also really good. The tests run in the Cypress Test Runner which shows your tests on the left and your app running in a main iframe performing those tests. After a test run, you can highlight individual steps in your tests to see what your app was doing at that point. Since the test runner is itself running in a browser, you also have access to developer tools to help debug tests.
Oftentimes when writing frontend tests it can take a lot of time to assess what a test is actually doing and what state the DOM is in at a particular point in the test. Cypress makes this part really easy because you can just see it happening right in front of you.
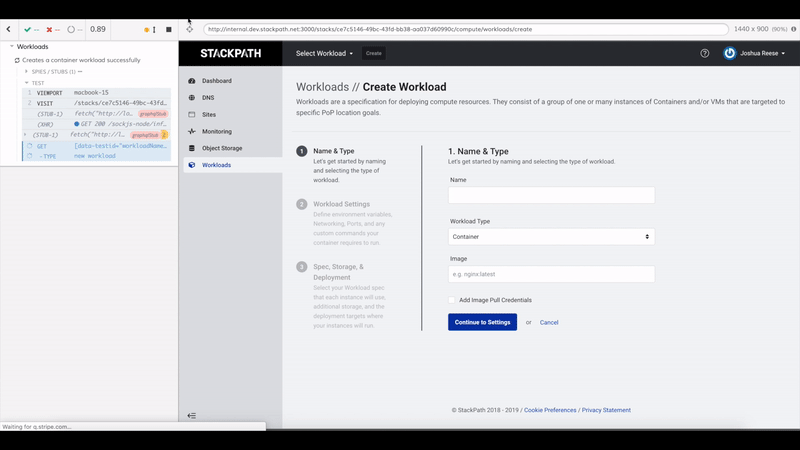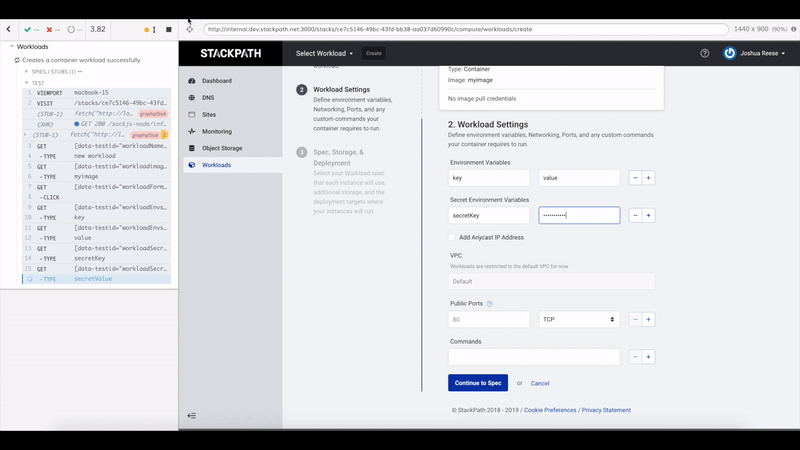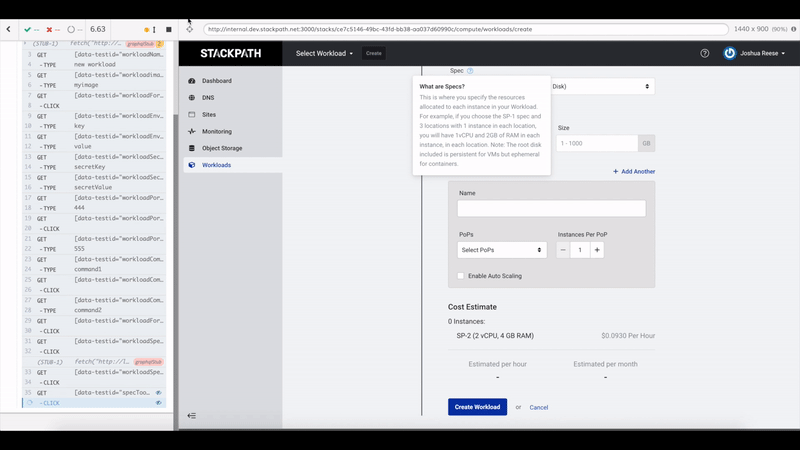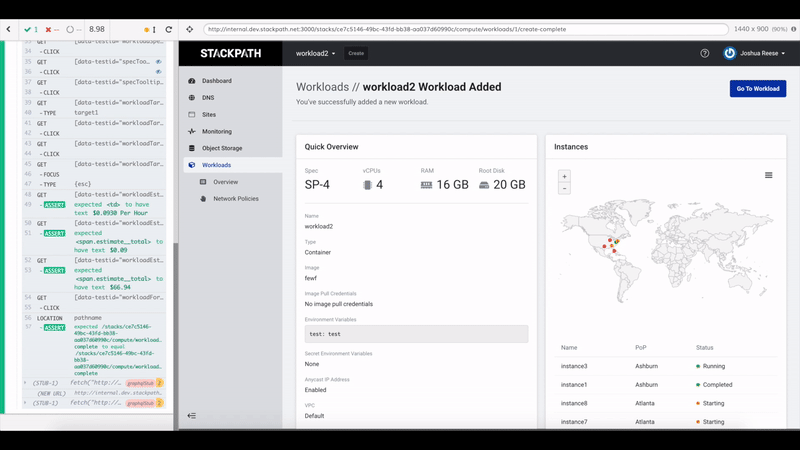
These tests exemplify a lot of our state testing principles. Cost to value ratio is favorable, the tests very closely mimic how an actual user interacts with the app, and the only thing being mocked is the network layer.
Cypress (E2E Tests)
Our E2E tests are also written in Cypress, but for these we do not mock the network (or anything else). Our tests run against our actual GraphQL server which communicates with actual instances of our backend services.
E2E tests are immensely valuable because they can definitively tell you if something works or not. Nothing is being mocked, so it’s using the app exactly as a user would. E2E tests are higher cost as well though. They are slower, take more thought to prevent intermittent failures, and take more work to ensure your tests are always in a known state before running.
Tests typically need to start from a known state, do some operations, and then arrive at some other known expected state. With the integration tests, this is easy to accomplish because the API calls are mocked and thus are the same every test run. For E2E tests, it’s more complicated because the backend storage now holds state which could be mutated as the result of a test. Somehow, you have to ensure that when you start a test, you’re in a known state.
At the beginning of our E2E test run, we run a script that seeds a new account with new stacks, sites, workloads, monitors, etc by making API calls directly. Each test run operates on different instances of the data, but the test setup is identical. The seed script emits a file with the data our tests use when running (instance ids and domains mostly). This seed script is what allows us to get into a known state before running our tests.
Since these E2E tests are higher cost, we write less of them than integration tests. We cover the critical functionality of our app: user registration/login, creating and configuring a site/workload, etc. From our extensive integration tests, we know that our frontend generally works, so these just need to ensure that there isn’t something slipping through the cracks when hooked up to the rest of the system.
Downsides to this multipronged testing strategy
While we’ve been really happy with our tests and the general stability of our app, there are definitely downsides to going with this sort of multipronged testing strategy.
First, it means everyone on the team needs to be familiar with multiple testing tools instead of just one. Everyone needs to know Jest, @testing-library/react, and Cypress. Not only do we have to know how to write tests in these different tools; we also have to make decisions all the time about which tool to use. Should I write an E2E test covering this functionality or is just writing an integration test fine? Do I need unit tests covering some of these finer-grain details as well?
There is undoubtedly a mental load here that isn’t present if you only have one choice. In general, we start with integration tests as the default and then add on an E2E test if we feel the functionality is particularly critical and backend-dependent. Or we start with unit tests if we feel integration tests cannot reasonably cover the number of different details involved.
We definitely still have some gray areas, but patterns start to emerge after going through this thought process enough times. For instance, testing form validation tends to be done in unit tests due to the number of different scenarios and everyone on the team is aware of that at this point.
Another downside to this approach is that collecting test coverage, while not impossible, is more difficult. While chasing test coverage can result in bad tests just for the sake of making a number go up, it can still be a useful automated way of finding holes in your tests. The trouble with having multiple testing tools is that you have to combine test coverage to find out which parts of your app are truly not covered. It’s possible, but it’s definitely more complicated.
Conclusion
While some challenges exist when using many different testing tools, each tool serves its purpose and we think is worth including in our overall testing strategy. When starting a new application, or adding tests to an existing one, integration tests are a great place to start. Adding some base-level E2E tests around absolutely critical functionality early on is a good idea as well.
With those two pieces in place, you should be able to make changes to your application with pretty reasonable confidence. If you start to notice bugs creeping in, stop and assess what sort of tests could have caught those bugs and if it indicates a deficiency in the overall strategy.
We definitely did not arrive at our current test setup overnight and it is something we expect to keep evolving as we continue growing. For the time being though, we feel good about our current approach to testing.
Posted on November 8, 2019
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related
