KubeCon 2022 - Jour 3

Λ\: Laurent Noireterre
Posted on May 20, 2022

Clap de fin pour la KubeCon 2022. Cette troisième et dernière journée a elle aussi été riche en thématiques et découvertes. En voici un condensé.
Par @vixsty, @eisenkremer, @aimbot31, @psclgllt, @launoirt
Kubernetes Everywhere: Lessons Learned From Going Multi-Cloud - Niko Smeds, Grafana Labs
Niko Smeds de chez Grafana nous fait un retour d'expérience de leur infrastructure multi-cloud, les raisons d’utiliser plusieurs provider cloud et les leçons apprises.
Niko nous énumère tout d’abord les raisons pour lesquelles une organisation devrait considérer le multi-cloud selon lui:
- augmenter les régions disponibles
- réduire le vendor lock-in
- des raisons plus orientés préférences utilisateurs (par exemple la souveraineté des données)
Voici le découpage des briques communes à chaque cloud provider chez Grafana:
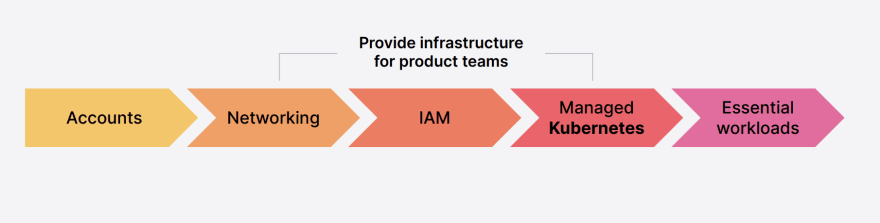
Cette structure permet d’avoir une gouvernance commune entre chaque cloud provider, mais les équipes de Grafana sont confrontés à plusieurs problématiques d’implémentation dûes aux spécificités de chaque provider:
- Réseau:
- sur GCP les VPC sont globaux, sur AWS ils sont régionaux
- les CIDR ranges supportés sont différents entre GCP et AWS (GCP supporte le range /28 -> /8, AWS supporte /28 -> /16)
- Différences dans les services managés (Load Balancers, Volumes, Object Storage)
- Gestion des credentials applicatifs (GCP Service Account vs AWS IAM Roles)
- Performances des disques : mauvaise performance de la classe de stockage par défaut sur Azure AKS
- Docker Hub rate limit: problème de performance lors du démarrage des pods sur AWS à cause du pull des images Docker depuis une même adresse IP de la NAT Gateway, alors que GCP propose par défaut un cache des images
- Différences de quotas des services pour chaque cloud provider
Voici en conclusion de ce talk les leçons apprises par les équipes de Grafana lors de leur mise en place et utilisation multi-cloud:

Logs Told Us It Was DNS, It Felt Like DNS, It Had To Be DNS, It Wasn’t DNS - Laurent Bernaille & Elijah Andrews, Datadog
Nous retrouvons Laurent Bernaille et Elijah Andrews, respectivement Staff Engineer et Senior Software Engineer chez Datadog, qui nous présente l'investigation qu'ils ont mené autour d'un problème survenant à chaque redéploiement du service "Metrics service".
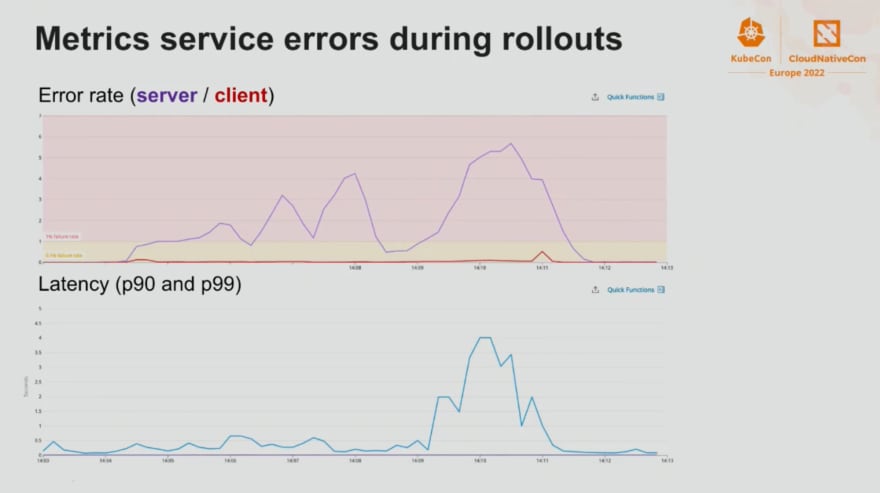
Nous avons trouvé cette présentation tellement intéressante que nous préférons ne pas en dire trop. À la place nous préférons vous encourager à visionner cette présentation lorsqu'elle sera accessible.
Ils y détaillent chaques étapes de leurs réflexions et chaques pistes explorées pour comprendre la cause du problème, en passant par les raisons de son apparition et sa résolution.
Better Bandwidth Management with eBPF - Daniel Borkmann & Christopher M. Luciano, Isovalent
Dans cette présentation, Isovalent, société à l'origine de Cilium, soulève les problèmes et les limites dans la gestion réseau d'aujourd'hui et comment Cilium choisi et implémente des techniques pour y remédier.
Deux techniques nous sont particulièrement présentées :
Le changement vers un modèle EDT dont vous pouvez retrouver la publication google.
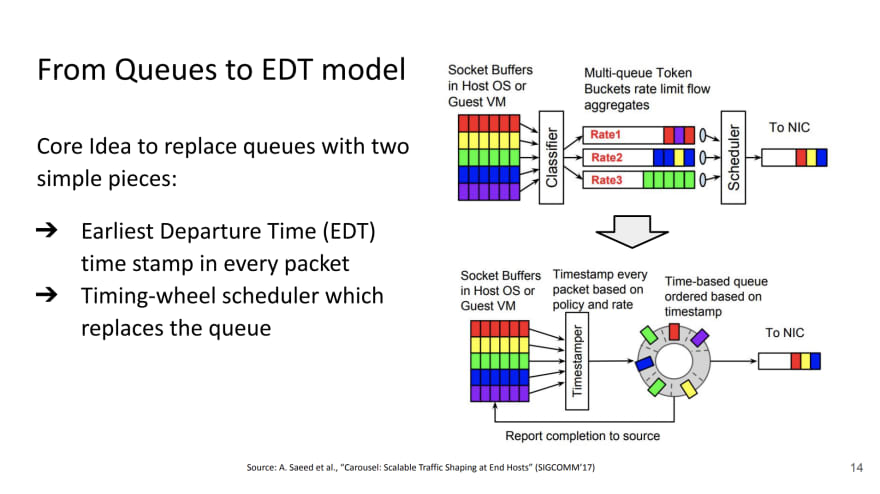
Ce modèle consiste à améliorer la vitesse à laquelle une trame va se retrouver dans la queue de la carte réseau.
Le 2nd point est l'évolution du TCP vers TCP BBR qui permet pour vulgariser d'adapter le TCP à la performance des réseaux de nos jours

Ici, on met en évidence que le TCP est un protocole créé pour des réseaux des années 1980 et que depuis nos réseaux ont bien changé.
C'est au travers d'une démonstration de streaming vidéo que l'on a pu voir de façon flagrante la différence entre sans et avec ces techniques.
L'ensemble permettant d'améliorer les capacités du réseau de façon très impressionnante.
A Treasure Map of Hacking (and Defending) Kubernetes
Andrew Martin qui a écrit le livre “Hacking Kubernetes” (et qui est disponible en téléchargement ici) nous a présenté les grandes étapes qui mènent à la compromission d’un cluster Kubernetes.
Voici une cartographie de toutes les potentielles vulnérabilités qui peuvent affecter un workload :
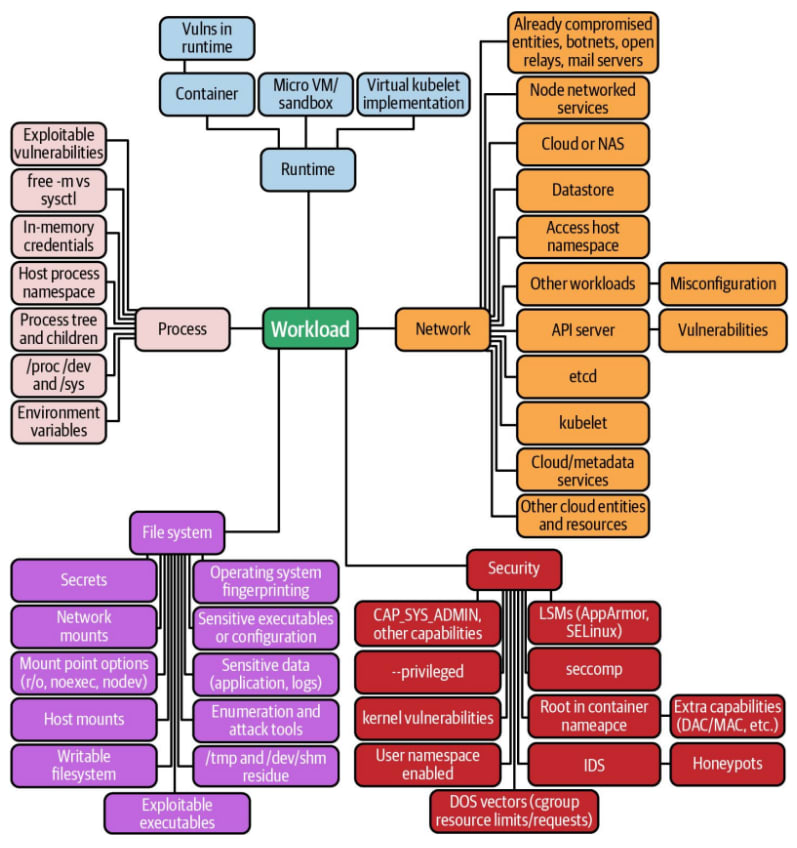
Le point d'entrée pris pour exemple ici est une attaque de plus en plus courante de nos jours : la supply chain attack. L’exemple le plus connu de supply chain attaque est la compromission du logiciel Solar Wind.
Via cette supply chain attaque, il obtient un reverse shell dans le contexte du pod. Nous voici en position d’exécuter des commandes et du code sur le container.
Ensuite plusieurs possibilités : lancer un autre pod malveillant ou s’évader du container.
La liste suivante des CVE résume bien l’état de sécurité de l’isolation des containers dans cette liste compilée par @Krisnova :

En exploitant la vulnérabilité Dirty Pipe (CVE-2022-0847), il s’évade du container et est maintenant root sur le node kubernetes.
Il a ensuite énuméré les secrets kubernetes qui sont accessibles depuis l’hôte et pris l’exemple d’une access key AWS, avec un petit twist car il s’agissait en réalité d’un honeypot.
C’est en effet une bonne idée de laisser des access key liées à un compte sans droit et de monitorer toute action réalisée par ce compte. Si la clé est utilisée on sait que l’on a été compromis et on peut prendre les actions nécessaires pour identifier et bloquer l’attaque rapidement.
Observing Fastly's network at scale thanks to k8s and the Strimzi operator
Daniel Caballero Rodriguez (Principal Engineer) & Fernando Crespo Gravalos (Staff Engineer) @ Fastly nous parlent de l’arrivé de kubernetes à Fastly ainsi que de leur système “Autopilot” sur kube qui permet d’optimiser la gestion du traffic sortant. Dans cet article, nous allons nous intéresser à la première partie afin de rester concis.
Au commencement de kubernetes à Fastly, les équipes lançaient des clusters kubernetes dans tous les sens. Fastly a observé que beaucoup de clusters étaient utilisés pour seulement une application, les besoins étaient souvent les mêmes et les bonnes pratiques pas toujours respectées.
De ce constat, Fastly a décidé de lancer le plan “Elevation”. La première itération “d’elevation” consistait à mutualiser les clusters avec une gestion par un équipe de SRE. 1 cluster de dev/staging/prod ainsi qu’une seule région. Un autre point important était l’agnosticité afin de ne pas dépendre d’un cloud provider dans le futur. Pour ce faire, Fastly a adopté les modalités suivantes :
- Auth avec IdP, afin de ne pas dépendre du Cloud IAM
- Harbor comme Container/Helm Charts registry
- Vault pour la gestion des secrets
- Nginx Ingress
- Cert-Manager pour la génération des certificats https avec Lets Encrypt
- Observability: Prometheus/Grafana, FluentD/Splunk
- Service Mesh with Linkerd
De cette V1.0 les feedbacks suivant sont ressortis :
- Plus de régions, plus de cloud providers, possibilité d’avoir des clusters baremetal
- Réduire le ticket d’entrée pour utiliser kube
- Prise en charge de Kafka en cluster
- Courbe d'apprentissage abrupte
- Améliorer l'observabilité du maillage des services
Afin de prendre en compte les améliorations de la version 1.0, Fastly à lancé la V2.0 en prenant en compte les retours :
- Utilisation des ClusterPolicy avec kyverno pour la gestion des secrets
- Utilisation d’opérateur pour certains besoin d’automatisation
- Ajouts de plusieurs régions/cloud providers
- De l’abstraction avec la possiblité de décrire l’application en 10 lignes de YAML afin qu’elle soit déployée avec un chart Helm standard maintenu par l’équipe SRE
- Ajout de dashboards standardisés maintenu par l’équipe SRE afin d’avoir les informations sur chaque application pour chaque équipe déployant sur le cluster
A Guided Tour of Cilium Service Mesh - Liz Rice, Isovalent
Une autre présentation autour de Cilium mais cette foi dans une utilisation en tant que Service Mesh. Liz Rice revient sur les différentes formes qu'a pu prendre le service mesh jusqu'à une nouvelle hypothèse, et si le service mesh était inclus au niveau du Kernel ?
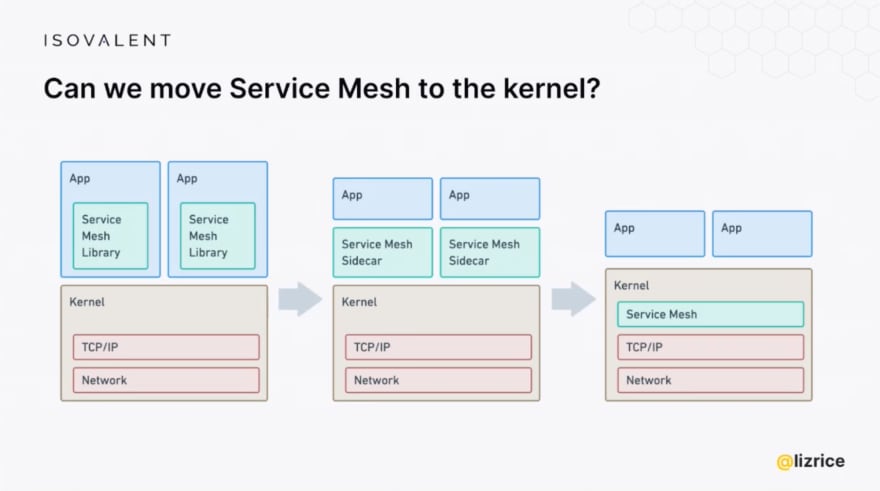
Mais le problème, et pas des moindre, est qu'au niveau du kernel, la couche TCP 7, pour laquelle le service mesh intervient, n'est pas visible. Donc eBPF et Cilium ne peuvent pas intervenir directement.
Dans son architecture du service mesh, Cilium propose donc la mise en place d'un reverse proxy Envoy sur la machine afin de pouvoir gérer cette couche TCP 7.

Cette approche permet d'éviter le "sidecar" à chaque pods mais impose un "sidecar" par node. Cela nous pose immédiatement des questions tant qu'à la scalabilité qu'à la gestion des exclusions. Envoy étant sur les nodes et les nodes exécutant des pods de divers namespaces.
S'enchaine des démonstrations, des commentaires de bêta testeurs et des benchmarks face à Istio. Globalement les chiffres sont intéressants et les commentaires confirment que la communauté espère plus.
On fini avec la gestion des contrôles planes. On peut choisir, mais l'intégration n'est pas native et il vous faudra gérer et maintenir cette intégration.
Posted on May 20, 2022
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related
