
Cadoret Théo
Posted on July 10, 2020

On entend souvent que le Test Driven Development est une bonne pratique, qu'elle permet d'avoir une base de code clean, plus maintenable, plus robuste etc.
À tel point que cette implication semble acceptée par ses adeptes comme un lien direct.
Quelqu'un m'a posé la question justement, pourquoi ? En quoi le TDD aide-t-il a obtenir tout ça ?
J'ai bafouillé et n'ai su poser des arguments. J'avais fini par accepter le TDD sans plus pouvoir l'expliquer.
Dans cet article allons considérer l'écriture des tests dans un contexte de TDD.
Le but ici n'est pas de décrire et d'expliquer comment pratiquer le TDD ni comment écrire de bons tests, les méthodes pour y parvenir sont nombreuses et déjà très bien renseignées dans d'autres articles.
Non, ici j'aimerais m'intéresser au pourquoi des tests, est-ce bien utile après tout ?
Je vais donc revenir sur certains points qui me semblent pertinents vis à vis de l'écriture de tests dans un contexte de TDD.
Ça n'est pas un top. Ça n'est pas exhaustif.
Parce que notre code répond à un besoin métier
Le code que nous écrivons, que ce soit dans un contexte personnel ou professionnel, doit répondre à un besoin métier.
Ce besoin peut ainsi se décomposer en une série de spécifications qui ensuite pourront être traduites en tests.
Une fois ceux-ci implémentés, nous savons que nous avons répondu au(x) besoin(s) dans la plupart de ses aspects métiers et de manière durable.
Écrire des tests n'est rien d'autre qu'ancrer les spécifications métier dans le code source du système de manière à en assurer la validité sur le long terme.
Je vais prendre un exemple simple sur le Game of Life de John Conway, l'une des spécifications / règles du jeu qui sera toujours vraie :
Any dead cell with exactly three live neighbours becomes a live cell, as if by reproduction.
public class CellTest{
@Test
void dead_cell_with_3_neighbors_should_come_alive() {
Cell cell = new Cell(CellState.DEAD);
CellState nextRoundCellState = cell.withLiveNeighbors(3).computeNextState();
assertThat(nextRoundCellState).isEqualTo(CellState.ALIVE);
}
}
Ainsi, on s'assure que cette spécification sera toujours vérifiée quelles que soient les modifications qui peuvent survenir par la suite. Une cellule morte possédant 3 voisins vivants va naître.
Il est même envisageable d'annoter ce test avec un tag Jira / Gitlab / Whatever, renvoyant directement vers la story concernée.
Parce que nous ne sommes pas seuls
Le code évolue continuellement, mais il n'est pas le seul. L'équipe de développement aussi !
Il est possible que nous ayons une vue d'ensemble claire du système dont nous avons la garde, mais il arrivera un moment où nous devrons partager le bébé, voire même le transmettre à quelqu'un d'autre.
Cette personne ne sera pas aussi au fait que nous du pourquoi du comment de certaines fonctionnalités, la documentation - même mise à jour régulièrement - n'a pas vocation à couvrir l'intégralité du code.
Peut-être que nous avons introduit de la complexité pour, par exemple, éviter que certains données d'entrée ne causent des problèmes.
Ajouter un test pour ça est comme documenter ce choix :
Je sais que cet évènement peut se produire, nous l'avons vu en prod et ça a causé des problèmes.
Voici les inputs en question, ils ne devraient plus poser de soucis car l'oracle (comportement spécifié par le métier) est celui-ci.
Le nouveau venu sera alors alerté si par mégarde il-elle modifie inconsciemment le comportement par un test rouge pointant directement sur la spécification en question.
De plus, nous sommes parfois amenés à designer des systèmes qui se doivent d'être génériques, ce qui passe très souvent par une large utilisation d'interfaces et autres niveaux d'abstraction.
Plus il y a de niveaux d'abstraction, plus il est difficile et long d'appréhender le code dans son ensemble et de s'approprier son comportement.
Avoir des tests qui implémentent de manière concrète certaines entités abstraites va grandement faciliter la construction d'un modèle mental global du système au nouveau venu.
C'est exactement comme illustrer un cours très théorique à l'aide d'exemples concrets, ça aide à fixer les idées.
Parce qu'on veut refactorer l'esprit tranquille
Plus le système évolue pour intégrer de nouvelles fonctionnalités, corriger des comportement anormaux etc. plus il se complexifie.
Ce phénomène se manifeste par l'apparition d'une complexité essentielle, inhérente aux besoins métiers que l'on essaie de traduire algorithmiquement, et d'une complexité accidentelle souvent due à l'ajout de pièces les unes au dessus des autres.
Dans un certain ordre. En un temps donné.
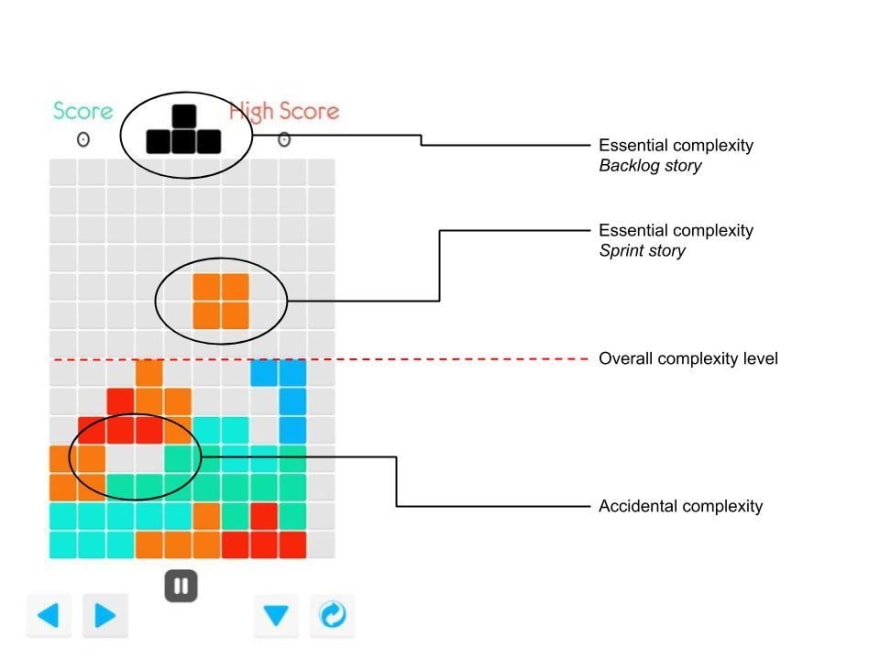
C'est donc l'empilement de nouvelles fonctionnalités qui transforme du code bien pensé et lisible en legacy lourd difficile à lire et à maintennir.
C'est la règle et il faut faire avec. Mais il est possible d'atténuer cette transformation en réécrivant ce vieux code au fur et à mesure, et pour ça, nos vieux tests de non régression sont nos meilleurs atouts.
Nous, on code, on redesign, on repense l'architecture. Eux ils nous protègent si l'on fait une erreur et nous évitent de tout se prendre dessus si ça tombe. Ils sont les garants du respect des spécifications.
Il arrive souvent qu'un petit refactoring prenne de plus en plus d'ampleur à mesure que l'on tire sur le fil.
Avoir confiance en sa couverture de tests (en terme de spécifications, pas de lignes de code) nous permet de nous arrêter quand on veut, tant qu'ils sont verts.
On peut donc garder les MR de refactoring courtes, faciles à merger, et fréquentes.
Parce qu'on veut une review
Les code reviews peuvent parfois être un exercice prenant, elles demandent une charge mentale très importante à la personne qui s'y colle. Il s'agit de lire, comprendre, et critiquer (constructivement, toujours) du code qui a pu prendre plusieurs jours à son/ses développeur(s).
Bon très bien, il est 9h30, j'ai du café, j'y vais. Mais par quoi je commence ?
La lecture / compréhension
En tant que reviewer on n'a pas nécessairement tout le contexte de la fonctionnalité, quels peuvent être les points sensibles. Les tickets / issues / post-its / whatever de stories sont bien souvent incomplets, et de toute façon ne relatent pas les difficultés techniques rencontrées qui ont pu pousser à certains choix.
Souvent les problèmes se posent à l'implémentation et le programmeur prend des décisions de design en fonction de ceux-ci, ce qui rend la mise en contexte plus difficile.
Sans aucun guide de lecture nous devons donc lire le code et comprendre par rétro-ingénierie ce qui a été implémenté et pourquoi les choix ont-été faits. (Même si certaines formes de documentation peuvent aider, voir cet article sur les ADR 😉 )
Exemple :
La merge request présente les plans d'un attelage avec 3m de rênes, 2 mors, 2 avaloirs etc. Celle-ci fait également état de points de ravitaillement espacés de 50km avec de l'eau et d'autres espacés de 100km possédant eau et nourriture.
Hmm ok, on veut parcourir une raisonablement longue distance en peu de temps avec deux chevaux sans les laisser se déssecher ni mourrir de faim.
La critique / Le biais
Une fois compris, nous devons avoir un regard critique (constructif, toujours) par rapport à ce qui a été développé.
Il faut donc réussir à être critique vis à vis d'une solution à un problème que l'on a compris à la sueur de nos cellules grises en se basant sur cette même solution. Vous voyez le biais ?
Difficile de prendre du recul, notre esprit est déjà polarisé par la solution avant même de pouvoir y réfléchir. C'est l'oeuvre d'un biais cognitif bien connu : le biais d'ancrage.
Pour des chevaux, des ravitaillements espacés de 40km et 80km seraient plus avisés sinon on risque de les épuiser rapidement. J'aurais plutôt pris 4m de rênes, il faut compter l'espacement entre les chevaux et la calèche, et se garder du mou pour être plus confortable (Valeurs prises un peu au hasard, j'avoue 😅)
Les tests comme guide
Pour une code review de qualité, à mon sens, le reviewer doit avoir une vision claire du problème avant d'attaquer la lecture de la solution.
C'est là que les tests entrent en jeu. Ils définissent à plus ou moins haut niveau les spécifications de la fonctionnalité.
Exemple :
On devrait couvrir la distance de 300km en deux jours maximum.
On devrait pouvoir tracter un chargement de X kilos.
Simplement à la lecture des tests le reviewer peut avoir une vision d'ensemble des possibilités et contraintes de la fonctionnalité implémentée.
Ensuite seulement il-elle peut se plonger dans l'étude de notre solution avec un esprit clair et proposer des critiques pertinentes et constructives.
Hmmm si tu remplaces l'attelage par un moteur devant la calèche tu peux te passer des points de ravitaillement
Enfin, il va sans dire qu'un reviewer à qui on évite la charge mentale de devoir faire une rétro-ingénierie sera plus enclin à prendre en charge la merge request et notre fonctionnalité ira en prod plus vite !
Parce que ça marche !
Mesurer l'efficacité d'un développeur ou d'une équipe sur le long terme est une tache fastidieuse car elle dépend de nombreux facteurs.
Il est donc impossible d'être sûr de l'efficacité du TDD dans un environnement donné et je ne peux pas vous assurer que ça rendra votre système parfait, ni même meilleur.
Mais j'aimerais néanmoins mettre en valeur certains chiffres obtenus par des études sur le TDD dans des conditions de test qui méritent qu'on s'y attarde un peu.
Temps de développement / Qualité du code
Cette étude, conduite avec des équipe d'IBM et de Microsoft, montre que le temps de développement d'un produit avec TDD est supérieur à celui sans TDD d'environ 15 à 35%.
Ce qui peut s'expliquer par beaucoup de choses. Évidemment le nombre de tests est supérieur, ce qui risque d'allonger le développement, mais il faut également voir que la méthodologie est loin d'être instinctive et facile à mettre en place !
Écrire les tests d'abord c'est commencer par se poser des questions sur ce que l'on veut obtenir, mettre en place ses interfaces etc. On renverse la logique et au début c'est pas facile.
Cette même étude met ces résultats en balance avec le nombre de défauts trouvés dans les pre-releases des produits issus ou non du TDD : Avec TDD ils sont de l'ordre de 40 à 90% moins fréquents.
On observe donc une réelle différence avec ou sans TDD en terme de qualité et de robustesse du code produit.
Il est alors intéressant de mettre ces résultats en perspective avec le coût d'un défaut à différentes étapes du cycle de développement.
Coût d'un bug
Pour illustrer cette grandeur, et comme on trouve beaucoup d'études et de résultats différents à ce propos, j'ai choisi de prendre la plus prudente des estimations que j'ai trouvée, présentée dans cette étude conduite par IBM Science Institute :

D'après IBM System Sciences Institute, corriger un bug en prod coûte 6x plus cher qu'à l'implémentation.
Cela s'explique notamment par le coût du changement de contexte.
Corriger un défaut en prod c'est changer de contexte de travail, se réapproprier le code en question (parfois vieux si l'agilité n'est pas la qualité première de l'équipe, mais c'est une autre histoire), diagnostiquer la cause, fixer ledit défaut et enfin rechanger de contexte pour poursuivre son travail.
Le défaut en question peut aussi être un mauvais choix d'implémentation qui, au fur et à mesure, a pu se propager : plus tard on s'en rend compte, plus il a pu servir de socle à d'autres développements. Les impacts de la réécriture sont donc décuplés.
Ça va sans dire que trouver l'origine d'un bug dans son environnement de développement est plus rapide qu'en se basant sur des extraits de logs de prod en level 'INFO'.
Enfin on peut noter qu'un défaut trouvé en prod risque fortement d'impacter le service, voire le tomber pour les plus graves, ce qui peut avoir un coût financier monstrueux dans le cas d'un service d'e-commerce, ou pire dans le médical...
La diversité des résultats issus des études sur les coûts des défauts s'explique très bien au vu de la difficulté de les quantifier.
Il reste néanmoins que tous les arguments, bien que qualitatifs plus que quantitatifs, sont tous orientés dans la même direction.
Conclusion
Écrire des tests c'est bien plus que garder sa couverture au dessus des 80% pour rassurer des gens qui n'y toucheront jamais.
Écrire des tests c'est expliciter son code, valider son travail, avoir confiance en son système, s'assurer de sa qualité, communiquer ses intentions etc.
Bref si on écrit des tests c'est avant tout pour nous aujourd'hui, et pour nous demain !
Posted on July 10, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related



