
shunku
Posted on June 30, 2022

https://docs.aws.amazon.com/AmazonS3/latest/userguide/storage-class-intro.html
Preparation
In:
import time
from pprint import pp
import boto3
import pandas as pd
s3 = boto3.client("s3")
Standard
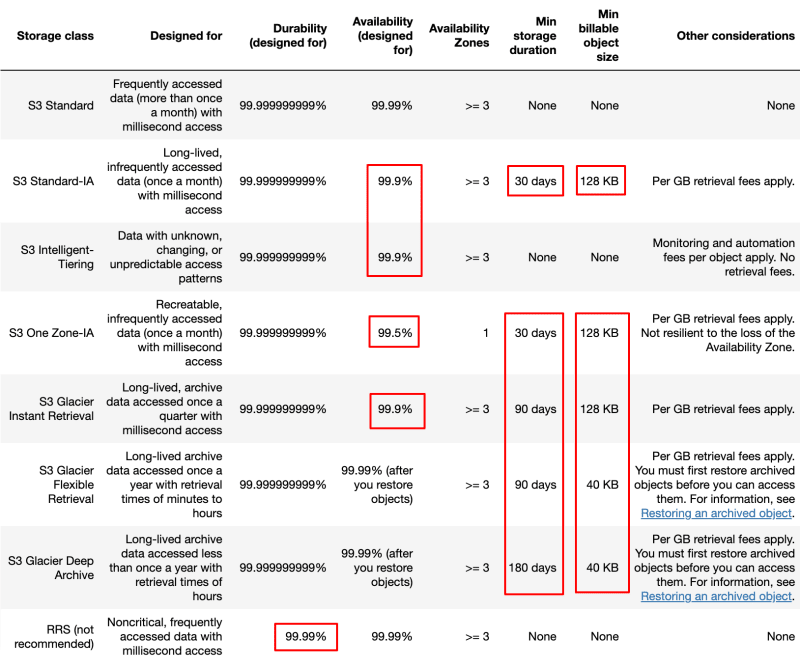
The default storage class. If you don't specify the storage class when you upload an object, Amazon S3 assigns the S3 Standard storage class.
Upload
In:
response = s3.put_object(
Body=open("/tmp/test.txt", mode="rb").read(),
Bucket="<bucket_name>",
ContentType="text/plain",
Key="standard.txt",
# No need to specify explicitly as it is the default
StorageClass="STANDARD",
)
pp(response)
Out:
{'ResponseMetadata': {'RequestId': 'J13M8VJPS3Y9PN9Z',
'HostId': '37QJ/X5IR87V3u8hH22QvlBIb8yLvfvBOeJVAQTzmuWlPTdq6t3lRjfIGGspD8QMuXrjJAKnISk=',
'HTTPStatusCode': 200,
'HTTPHeaders': {'x-amz-id-2': '37QJ/X5IR87V3u8hH22QvlBIb8yLvfvBOeJVAQTzmuWlPTdq6t3lRjfIGGspD8QMuXrjJAKnISk=',
'x-amz-request-id': 'J13M8VJPS3Y9PN9Z',
'date': 'Wed, 29 Jun 2022 16:44:58 GMT',
'etag': '"02bcabffffd16fe0fc250f08cad95e0c"',
'server': 'AmazonS3',
'content-length': '0'},
'RetryAttempts': 0},
'ETag': '"02bcabffffd16fe0fc250f08cad95e0c"'}
Download
In:
response = s3.get_object(
Bucket="<bucket_name>",
Key="standard.txt",
)
pp(response)
Out:
{'ResponseMetadata': {'RequestId': '658A5BCR57K59K44',
'HostId': 'VdfkXa52iCeI1NPmffjMZqpWx+kO6S8AhQGkgiFx7HarDPSyKkuQbqI7gBuxsExG3Tgj5wdoHfM=',
'HTTPStatusCode': 200,
'HTTPHeaders': {'x-amz-id-2': 'VdfkXa52iCeI1NPmffjMZqpWx+kO6S8AhQGkgiFx7HarDPSyKkuQbqI7gBuxsExG3Tgj5wdoHfM=',
'x-amz-request-id': '658A5BCR57K59K44',
'date': 'Wed, 29 Jun 2022 16:45:21 GMT',
'last-modified': 'Wed, 29 Jun 2022 '
'16:44:58 GMT',
'etag': '"02bcabffffd16fe0fc250f08cad95e0c"',
'accept-ranges': 'bytes',
'content-type': 'text/plain',
'server': 'AmazonS3',
'content-length': '16'},
'RetryAttempts': 0},
'AcceptRanges': 'bytes',
'LastModified': datetime.datetime(2022, 6, 29, 16, 44, 58, tzinfo=tzutc()),
'ContentLength': 16,
'ETag': '"02bcabffffd16fe0fc250f08cad95e0c"',
'ContentType': 'text/plain',
'Metadata': {},
'Body': <botocore.response.StreamingBody object at 0x7fcccab97c70>}
Standard-IA
S3 Standard-IA — Amazon S3 stores the object data redundantly across multiple geographically separated Availability Zones (similar to the S3 Standard storage class). S3 Standard-IA objects are resilient to the loss of an Availability Zone. This storage class offers greater availability and resiliency than the S3 One Zone-IA class.
The S3 Standard-IA and S3 One Zone-IA storage classes are designed for long-lived and infrequently accessed data. (IA stands for infrequent access.) S3 Standard-IA and S3 One Zone-IA objects are available for millisecond access (similar to the S3 Standard storage class). Amazon S3 charges a retrieval fee for these objects, so they are most suitable for infrequently accessed data.
The S3 Standard-IA and S3 One Zone-IA storage classes are suitable for objects larger than 128 KB that you plan to store for at least 30 days. If an object is less than 128 KB, Amazon S3 charges you for 128 KB. If you delete an object before the end of the 30-day minimum storage duration period, you are charged for 30 days.
Upload
In:
response = s3.put_object(
Body=open("/tmp/test.txt", mode="rb").read(),
Bucket="<bucket_name>",
ContentType="text/plain",
Key="standard_ia.txt",
StorageClass="STANDARD_IA",
)
pp(response)
Out:
{'ResponseMetadata': {'RequestId': 'GVSAQ9S2FHN7TQA8',
'HostId': 'FuzDS5MQ8Zr6I5ko/Ohe0cV1fvecsp4Dqc8cT1nWcOVVBDA57fGP1dpfJGnMfNWUPwjqFAdBatI=',
'HTTPStatusCode': 200,
'HTTPHeaders': {'x-amz-id-2': 'FuzDS5MQ8Zr6I5ko/Ohe0cV1fvecsp4Dqc8cT1nWcOVVBDA57fGP1dpfJGnMfNWUPwjqFAdBatI=',
'x-amz-request-id': 'GVSAQ9S2FHN7TQA8',
'date': 'Wed, 29 Jun 2022 16:46:48 GMT',
'etag': '"02bcabffffd16fe0fc250f08cad95e0c"',
'x-amz-storage-class': 'STANDARD_IA',
'server': 'AmazonS3',
'content-length': '0'},
'RetryAttempts': 0},
'ETag': '"02bcabffffd16fe0fc250f08cad95e0c"'}
Download
In:
response = s3.get_object(
Bucket="<bucket_name>",
Key="standard_ia.txt",
)
pp(response)
Out:
{'ResponseMetadata': {'RequestId': 'DSD9YCBCXS1ZSRZW',
'HostId': 'hXzkL/oNFPyJVcJptr4d1dDJGB/4kDfwhSHKii6uOjevLcS6RertaAmC/VtdQSL4vBm/FwQuxy8=',
'HTTPStatusCode': 200,
'HTTPHeaders': {'x-amz-id-2': 'hXzkL/oNFPyJVcJptr4d1dDJGB/4kDfwhSHKii6uOjevLcS6RertaAmC/VtdQSL4vBm/FwQuxy8=',
'x-amz-request-id': 'DSD9YCBCXS1ZSRZW',
'date': 'Wed, 29 Jun 2022 16:47:07 GMT',
'last-modified': 'Wed, 29 Jun 2022 '
'16:46:48 GMT',
'etag': '"02bcabffffd16fe0fc250f08cad95e0c"',
'x-amz-storage-class': 'STANDARD_IA',
'accept-ranges': 'bytes',
'content-type': 'text/plain',
'server': 'AmazonS3',
'content-length': '16'},
'RetryAttempts': 0},
'AcceptRanges': 'bytes',
'LastModified': datetime.datetime(2022, 6, 29, 16, 46, 48, tzinfo=tzutc()),
'ContentLength': 16,
'ETag': '"02bcabffffd16fe0fc250f08cad95e0c"',
'ContentType': 'text/plain',
'Metadata': {},
'StorageClass': 'STANDARD_IA',
'Body': <botocore.response.StreamingBody object at 0x7fcccab97610>}
Intelligent-Tiering
S3 Intelligent-Tiering is an Amazon S3 storage class designed to optimize storage costs by automatically moving data to the most cost-effective access tier, without performance impact or operational overhead.
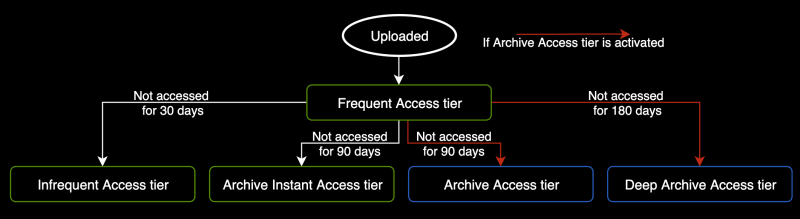
S3 Intelligent-Tiering automatically stores objects in three access tiers: a Frequent Access tier, an Infrequent Access tier, and a Archive Instant Access tier. Objects that are uploaded or transitioned to S3 Intelligent-Tiering are automatically stored in the Frequent Access tier. S3 Intelligent-Tiering works by monitoring access patterns and then moving the objects that have not been accessed in 30 consecutive days to the Infrequent Access tier. With S3 Intelligent-Tiering, any existing objects that have not been accessed for 90 consecutive days will automatically move to the Archive Instant Access tier.
After you activate one or both of the archive access tiers, S3 Intelligent-Tiering automatically moves objects that haven’t been accessed for 90 consecutive days to the Archive Access tier, and after 180 consecutive days of no access, to the Deep Archive Access tier.
Upload
In:
response = s3.put_object(
Body=open("/tmp/test.txt", mode="rb").read(),
Bucket="<bucket_name>",
ContentType="text/plain",
Key="intelligent_tiering.txt",
StorageClass="INTELLIGENT_TIERING",
)
pp(response)
Out:
{'ResponseMetadata': {'RequestId': '5NC8JCZT7KG36ASK',
'HostId': 'oxzjT7+8fQ2DfbjnTxXTVMfDQ+hy+9/KnkqGFB0+7Vfl6iAmCz0B2argnI1u0xRw0Jj2lctm5uk=',
'HTTPStatusCode': 200,
'HTTPHeaders': {'x-amz-id-2': 'oxzjT7+8fQ2DfbjnTxXTVMfDQ+hy+9/KnkqGFB0+7Vfl6iAmCz0B2argnI1u0xRw0Jj2lctm5uk=',
'x-amz-request-id': '5NC8JCZT7KG36ASK',
'date': 'Wed, 29 Jun 2022 16:48:21 GMT',
'etag': '"02bcabffffd16fe0fc250f08cad95e0c"',
'x-amz-storage-class': 'INTELLIGENT_TIERING',
'server': 'AmazonS3',
'content-length': '0'},
'RetryAttempts': 0},
'ETag': '"02bcabffffd16fe0fc250f08cad95e0c"'}
Download
In:
response = s3.get_object(
Bucket="<bucket_name>",
Key="intelligent_tiering.txt",
)
pp(response)
Out:
{'ResponseMetadata': {'RequestId': 'GEZ6XBD3C97JX909',
'HostId': 'zxLVlqrL+/hVFZlHeA9qW2iUL63u2pdQoLozL++XArtiwbYEWQ2hxlkd4nnQqUn4GeGdoxxFW2k=',
'HTTPStatusCode': 200,
'HTTPHeaders': {'x-amz-id-2': 'zxLVlqrL+/hVFZlHeA9qW2iUL63u2pdQoLozL++XArtiwbYEWQ2hxlkd4nnQqUn4GeGdoxxFW2k=',
'x-amz-request-id': 'GEZ6XBD3C97JX909',
'date': 'Wed, 29 Jun 2022 16:50:34 GMT',
'last-modified': 'Wed, 29 Jun 2022 '
'16:48:21 GMT',
'etag': '"02bcabffffd16fe0fc250f08cad95e0c"',
'x-amz-storage-class': 'INTELLIGENT_TIERING',
'accept-ranges': 'bytes',
'content-type': 'text/plain',
'server': 'AmazonS3',
'content-length': '16'},
'RetryAttempts': 0},
'AcceptRanges': 'bytes',
'LastModified': datetime.datetime(2022, 6, 29, 16, 48, 21, tzinfo=tzutc()),
'ContentLength': 16,
'ETag': '"02bcabffffd16fe0fc250f08cad95e0c"',
'ContentType': 'text/plain',
'Metadata': {},
'StorageClass': 'INTELLIGENT_TIERING',
'Body': <botocore.response.StreamingBody object at 0x7fcccac90a00>}
View Archive Status
https://docs.aws.amazon.com/AmazonS3/latest/userguide/intelligent-tiering-managing.html
You can also use a HEAD object request to view an object's archive status. If an object is stored using the S3 Intelligent-Tiering storage class and is in one of the archive tiers, the HEAD object response shows the current archive tier. It does this using the x-amz-archive-status header.
In:
response = s3.head_object(
Bucket="<bucket_name>",
Key="intelligent_tiering.txt",
)
pp(response)
Out:
{'ResponseMetadata': {'RequestId': 'D733NADSQ2YJR58R',
'HostId': 'ruglFtSr4XacdaSe94y4tqy7oN5ypkiyNLtcTIeYBclsGLb52irxIwyYIBy1dGsveM/CgZ02DL0=',
'HTTPStatusCode': 200,
'HTTPHeaders': {'x-amz-id-2': 'ruglFtSr4XacdaSe94y4tqy7oN5ypkiyNLtcTIeYBclsGLb52irxIwyYIBy1dGsveM/CgZ02DL0=',
'x-amz-request-id': 'D733NADSQ2YJR58R',
'date': 'Thu, 30 Jun 2022 14:31:33 GMT',
'last-modified': 'Wed, 29 Jun 2022 '
'16:48:21 GMT',
'etag': '"02bcabffffd16fe0fc250f08cad95e0c"',
'x-amz-storage-class': 'INTELLIGENT_TIERING',
'accept-ranges': 'bytes',
'content-type': 'text/plain',
'server': 'AmazonS3',
'content-length': '16'},
'RetryAttempts': 0},
'AcceptRanges': 'bytes',
'LastModified': datetime.datetime(2022, 6, 29, 16, 48, 21, tzinfo=tzutc()),
'ContentLength': 16,
'ETag': '"02bcabffffd16fe0fc250f08cad95e0c"',
'ContentType': 'text/plain',
'Metadata': {},
'StorageClass': 'INTELLIGENT_TIERING'}
This object is not in archive tiers, so x-amz-archive-status header is not present.
One Zone-IA
The S3 Standard-IA and S3 One Zone-IA storage classes are designed for long-lived and infrequently accessed data. (IA stands for infrequent access.) S3 Standard-IA and S3 One Zone-IA objects are available for millisecond access (similar to the S3 Standard storage class). Amazon S3 charges a retrieval fee for these objects, so they are most suitable for infrequently accessed data.
The S3 Standard-IA and S3 One Zone-IA storage classes are suitable for objects larger than 128 KB that you plan to store for at least 30 days. If an object is less than 128 KB, Amazon S3 charges you for 128 KB. If you delete an object before the end of the 30-day minimum storage duration period, you are charged for 30 days.
S3 One Zone-IA — Amazon S3 stores the object data in only one Availability Zone, which makes it less expensive than S3 Standard-IA. However, the data is not resilient to the physical loss of the Availability Zone resulting from disasters, such as earthquakes and floods. The S3 One Zone-IA storage class is as durable as Standard-IA, but it is less available and less resilient.
S3 One Zone-IA — Use if you can re-create the data if the Availability Zone fails, and for object replicas when setting S3 Cross-Region Replication (CRR).
All of the storage classes except for S3 One Zone-IA are designed to be resilient to the physical loss of an Availability Zone resulting from disasters.
You can also change the storage class of an object that is already stored in Amazon S3 to any other storage class by making a copy of the object using the PUT Object - Copy API. However, you can't use PUT Object - Copy to copy objects that are stored in the S3 Glacier Flexible Retrieval or S3 Glacier Deep Archive storage classes. You also can't transition from S3 One Zone-IA to S3 Glacier Instant Retrieval.
Upload
In:
response = s3.put_object(
Body=open("/tmp/test.txt", mode="rb").read(),
Bucket="<bucket_name>",
ContentType="text/plain",
Key="one_zone_ia.txt",
StorageClass="ONEZONE_IA",
)
pp(response)
Out:
{'ResponseMetadata': {'RequestId': 'G4EYJFGHZCZDYKV8',
'HostId': 'tHSWH64lUTevuHjufn8jKZeQOP/avAhP7ErOoAXprCS7WMNt7uRQnM/6HC9QkLu3ntt8Iw74GPQ=',
'HTTPStatusCode': 200,
'HTTPHeaders': {'x-amz-id-2': 'tHSWH64lUTevuHjufn8jKZeQOP/avAhP7ErOoAXprCS7WMNt7uRQnM/6HC9QkLu3ntt8Iw74GPQ=',
'x-amz-request-id': 'G4EYJFGHZCZDYKV8',
'date': 'Thu, 30 Jun 2022 14:41:51 GMT',
'etag': '"02bcabffffd16fe0fc250f08cad95e0c"',
'x-amz-storage-class': 'ONEZONE_IA',
'server': 'AmazonS3',
'content-length': '0'},
'RetryAttempts': 0},
'ETag': '"02bcabffffd16fe0fc250f08cad95e0c"'}
Download
In:
response = s3.get_object(
Bucket="<bucket_name>",
Key="one_zone_ia.txt",
)
pp(response)
Out:
{'ResponseMetadata': {'RequestId': 'TTEDEDV69REP6NW2',
'HostId': 'LFm0aD18YX9xs+1JRgAhEBqlcDuzNkQq7zod60gOqP/oNWoF2RmIk8B+asnsCcShItsu1JsDjpc=',
'HTTPStatusCode': 200,
'HTTPHeaders': {'x-amz-id-2': 'LFm0aD18YX9xs+1JRgAhEBqlcDuzNkQq7zod60gOqP/oNWoF2RmIk8B+asnsCcShItsu1JsDjpc=',
'x-amz-request-id': 'TTEDEDV69REP6NW2',
'date': 'Thu, 30 Jun 2022 14:42:16 GMT',
'last-modified': 'Thu, 30 Jun 2022 '
'14:41:51 GMT',
'etag': '"02bcabffffd16fe0fc250f08cad95e0c"',
'x-amz-storage-class': 'ONEZONE_IA',
'accept-ranges': 'bytes',
'content-type': 'text/plain',
'server': 'AmazonS3',
'content-length': '16'},
'RetryAttempts': 0},
'AcceptRanges': 'bytes',
'LastModified': datetime.datetime(2022, 6, 30, 14, 41, 51, tzinfo=tzutc()),
'ContentLength': 16,
'ETag': '"02bcabffffd16fe0fc250f08cad95e0c"',
'ContentType': 'text/plain',
'Metadata': {},
'StorageClass': 'ONEZONE_IA',
'Body': <botocore.response.StreamingBody object at 0x7fcccb1b4d60>}
Glacier Instant Retrieval
The S3 Glacier Instant Retrieval, S3 Glacier Flexible Retrieval, and S3 Glacier Deep Archive storage classes are designed for low-cost data archiving. These storage classes offer the same durability and resiliency as the S3 Standard and S3 Standard-IA storage classes.
S3 Glacier Instant Retrieval — Use for archiving data that is rarely accessed and requires milliseconds retrieval. Data stored in the S3 Glacier Instant Retrieval storage class offers a cost savings compared to the S3 Standard-IA storage class, with the same latency and throughput performance as the S3 Standard-IA storage class. S3 Glacier Instant Retrieval has higher data access costs than S3 Standard-IA.
You must first restore the S3 Glacier Flexible Retrieval and S3 Glacier Deep Archive objects before you can access them. (S3 Standard, RRS, S3 Standard-IA, S3 One Zone-IA, S3 Glacier Instant Retrieval, and S3 Intelligent-Tiering objects are available for anytime access.)
You can also change the storage class of an object that is already stored in Amazon S3 to any other storage class by making a copy of the object using the PUT Object - Copy API. However, you can't use PUT Object - Copy to copy objects that are stored in the S3 Glacier Flexible Retrieval or S3 Glacier Deep Archive storage classes. You also can't transition from S3 One Zone-IA to S3 Glacier Instant Retrieval.
Upload
In:
response = s3.put_object(
Body=open("/tmp/test.txt", mode="rb").read(),
Bucket="<bucket_name>",
ContentType="text/plain",
Key="glacier_instant_retrieval.txt",
StorageClass="GLACIER_IR",
)
pp(response)
Out:
{'ResponseMetadata': {'RequestId': 'C54NWKFS5AKTFFPQ',
'HostId': 'ePd7XvtCE3uLoX22+linjtjvj+jJnUEcDv7UkynmXwXPKfF80AP6br4M9iW3V7jmZSfM8BnVqj8=',
'HTTPStatusCode': 200,
'HTTPHeaders': {'x-amz-id-2': 'ePd7XvtCE3uLoX22+linjtjvj+jJnUEcDv7UkynmXwXPKfF80AP6br4M9iW3V7jmZSfM8BnVqj8=',
'x-amz-request-id': 'C54NWKFS5AKTFFPQ',
'date': 'Thu, 30 Jun 2022 15:06:59 GMT',
'etag': '"02bcabffffd16fe0fc250f08cad95e0c"',
'x-amz-storage-class': 'GLACIER_IR',
'server': 'AmazonS3',
'content-length': '0'},
'RetryAttempts': 0},
'ETag': '"02bcabffffd16fe0fc250f08cad95e0c"'}
Download
In:
response = s3.get_object(
Bucket="<bucket_name>",
Key="glacier_instant_retrieval.txt",
)
pp(response)
Out:
{'ResponseMetadata': {'RequestId': 'MYP5YPXE20HCJTVW',
'HostId': '6vqSDBk6AISEB2329uX1d++KRK29ht3+XRarXyLZE9VnSzvIyAH7F9NAAnHgWciNDsqnMnlOLHg=',
'HTTPStatusCode': 200,
'HTTPHeaders': {'x-amz-id-2': '6vqSDBk6AISEB2329uX1d++KRK29ht3+XRarXyLZE9VnSzvIyAH7F9NAAnHgWciNDsqnMnlOLHg=',
'x-amz-request-id': 'MYP5YPXE20HCJTVW',
'date': 'Thu, 30 Jun 2022 15:07:01 GMT',
'last-modified': 'Thu, 30 Jun 2022 '
'15:06:59 GMT',
'etag': '"02bcabffffd16fe0fc250f08cad95e0c"',
'x-amz-storage-class': 'GLACIER_IR',
'accept-ranges': 'bytes',
'content-type': 'text/plain',
'server': 'AmazonS3',
'content-length': '16'},
'RetryAttempts': 0},
'AcceptRanges': 'bytes',
'LastModified': datetime.datetime(2022, 6, 30, 15, 6, 59, tzinfo=tzutc()),
'ContentLength': 16,
'ETag': '"02bcabffffd16fe0fc250f08cad95e0c"',
'ContentType': 'text/plain',
'Metadata': {},
'StorageClass': 'GLACIER_IR',
'Body': <botocore.response.StreamingBody object at 0x7fcccb2977f0>}
Glacier Flexible Retrieval
The S3 Glacier Instant Retrieval, S3 Glacier Flexible Retrieval, and S3 Glacier Deep Archive storage classes are designed for low-cost data archiving. These storage classes offer the same durability and resiliency as the S3 Standard and S3 Standard-IA storage classes.
S3 Glacier Flexible Retrieval — Use for archives where portions of the data might need to be retrieved in minutes. Data stored in the S3 Glacier Flexible Retrieval storage class has a minimum storage duration period of 90 days and can be accessed in as little as 1-5 minutes using expedited retrieval. The retrieval time is flexible, and you can request free bulk retrievals in up to 5-12 hours. If you have deleted, overwritten, or transitioned to a different storage class an object before the 90-day minimum, you are charged for 90 days.
You can set the storage class of an object to S3 Glacier Flexible Retrieval or S3 Glacier Deep Archive in the same ways that you do for the other storage classes as described in the section Setting the storage class of an object. However, the S3 Glacier Flexible Retrieval and S3 Glacier Deep Archive objects are not available for real-time access. You must first restore the S3 Glacier Flexible Retrieval and S3 Glacier Deep Archive objects before you can access them. (S3 Standard, RRS, S3 Standard-IA, S3 One Zone-IA, S3 Glacier Instant Retrieval, and S3 Intelligent-Tiering objects are available for anytime access.)
When you choose the S3 Glacier Flexible Retrieval or S3 Glacier Deep Archive storage class, your objects remain in Amazon S3. You can't access them directly through the separate Amazon S3 Glacier service.
You can also change the storage class of an object that is already stored in Amazon S3 to any other storage class by making a copy of the object using the PUT Object - Copy API. However, you can't use PUT Object - Copy to copy objects that are stored in the S3 Glacier Flexible Retrieval or S3 Glacier Deep Archive storage classes.
When setting up a replication configuration, you can set the storage class for replicated objects to any other storage class. However, you can't replicate objects that are stored in the S3 Glacier Flexible Retrieval or S3 Glacier Deep Archive storage classes.
Upload
In:
response = s3.put_object(
Body=open("/tmp/test.txt", mode="rb").read(),
Bucket="<bucket_name>",
ContentType="text/plain",
Key="glacier_flexible_retrieval.txt",
StorageClass="GLACIER",
)
pp(response)
Out:
{'ResponseMetadata': {'RequestId': 'YZAEKQWGQG1XENG6',
'HostId': '33LiHFlKWt243wusVugnvHSHwHxp9EmNXOoVDp2SN+we/Q5N9HAk4Opog/1hvJXQM4mzZhn6KoY=',
'HTTPStatusCode': 200,
'HTTPHeaders': {'x-amz-id-2': '33LiHFlKWt243wusVugnvHSHwHxp9EmNXOoVDp2SN+we/Q5N9HAk4Opog/1hvJXQM4mzZhn6KoY=',
'x-amz-request-id': 'YZAEKQWGQG1XENG6',
'date': 'Thu, 30 Jun 2022 15:24:06 GMT',
'etag': '"02bcabffffd16fe0fc250f08cad95e0c"',
'x-amz-storage-class': 'GLACIER',
'server': 'AmazonS3',
'content-length': '0'},
'RetryAttempts': 0},
'ETag': '"02bcabffffd16fe0fc250f08cad95e0c"'}
Download
In:
try:
response = s3.get_object(
Bucket="<bucket_name>",
Key="glacier_flexible_retrieval.txt",
)
except Exception as e:
response = e.response
pp(response)
Out:
{'Error': {'Code': 'InvalidObjectState',
'Message': "The operation is not valid for the object's storage "
'class',
'StorageClass': 'GLACIER'},
'ResponseMetadata': {'RequestId': '5F42BZ1SZC6TQW4M',
'HostId': '0mDQbSuaCGaNlW4csgWcVViwDSH+Pqc8h3taAq6jgmlNnkY9GfziEV6VyudUVdiMNY+lia48FC8=',
'HTTPStatusCode': 403,
'HTTPHeaders': {'x-amz-request-id': '5F42BZ1SZC6TQW4M',
'x-amz-id-2': '0mDQbSuaCGaNlW4csgWcVViwDSH+Pqc8h3taAq6jgmlNnkY9GfziEV6VyudUVdiMNY+lia48FC8=',
'content-type': 'application/xml',
'transfer-encoding': 'chunked',
'date': 'Thu, 30 Jun 2022 15:24:10 GMT',
'server': 'AmazonS3'},
'RetryAttempts': 0},
'StorageClass': 'GLACIER'}
As stated in the document, I cannot download the object directly.
Restore
In:
response = s3.restore_object(
Bucket="<bucket_name>",
Key="glacier_flexible_retrieval.txt",
RestoreRequest={
"Days": 1,
"GlacierJobParameters": {"Tier": "Expedited"},
},
)
pp(response)
Out:
{'ResponseMetadata': {'RequestId': 'B0MQGSJX7BEQARH7',
'HostId': 'G7OXNdXgVGHKmzR++fKyEkb6uWd1wRWf5TrqM8+X7eq0am4MH3XUhIBu2SJvTYASy490dgUVYIw=',
'HTTPStatusCode': 202,
'HTTPHeaders': {'x-amz-id-2': 'G7OXNdXgVGHKmzR++fKyEkb6uWd1wRWf5TrqM8+X7eq0am4MH3XUhIBu2SJvTYASy490dgUVYIw=',
'x-amz-request-id': 'B0MQGSJX7BEQARH7',
'date': 'Thu, 30 Jun 2022 15:24:19 GMT',
'server': 'AmazonS3',
'content-length': '0'},
'RetryAttempts': 0}}
Try to download
In:
responses = []
for i in range(360):
try:
response = s3.get_object(
Bucket="<bucket_name>",
Key="glacier_flexible_retrieval.txt",
)
except Exception as e:
response = e.response
responses.append(
{
"status": response["ResponseMetadata"]["HTTPStatusCode"],
"date": response["ResponseMetadata"]["HTTPHeaders"]["date"],
}
)
time.sleep(1)
df = pd.DataFrame.from_dict(responses)
print(df[df.status == 403].tail(1).T)
print(df[df.status == 200].head(1).T)
Out:
60
status 403
date Thu, 30 Jun 2022 15:25:41 GMT
61
status 200
date Thu, 30 Jun 2022 15:25:43 GMT
Request to restore: Thu, 30 Jun 2022 15:24:19 GMT
Restored: Thu, 30 Jun 2022 15:25:43 GMT
I used Expedited tier for restoring, so it took about 1.5 min.
Glacier Deep Archive
The S3 Glacier Instant Retrieval, S3 Glacier Flexible Retrieval, and S3 Glacier Deep Archive storage classes are designed for low-cost data archiving. These storage classes offer the same durability and resiliency as the S3 Standard and S3 Standard-IA storage classes.
S3 Glacier Deep Archive — Use for archiving data that rarely needs to be accessed. Data stored in the S3 Glacier Deep Archive storage class has a minimum storage duration period of 180 days and a default retrieval time of 12 hours. If you have deleted, overwritten, or transitioned to a different storage class an object before the 180-day minimum, you are charged for 180 days.
S3 Glacier Deep Archive is the lowest cost storage option in AWS. Storage costs for S3 Glacier Deep Archive are less expensive than using the S3 Glacier Flexible Retrieval storage class. You can reduce S3 Glacier Deep Archive retrieval costs by using bulk retrieval, which returns data within 48 hours.
You can set the storage class of an object to S3 Glacier Flexible Retrieval or S3 Glacier Deep Archive in the same ways that you do for the other storage classes as described in the section Setting the storage class of an object. However, the S3 Glacier Flexible Retrieval and S3 Glacier Deep Archive objects are not available for real-time access. You must first restore the S3 Glacier Flexible Retrieval and S3 Glacier Deep Archive objects before you can access them. (S3 Standard, RRS, S3 Standard-IA, S3 One Zone-IA, S3 Glacier Instant Retrieval, and S3 Intelligent-Tiering objects are available for anytime access.)
When you choose the S3 Glacier Flexible Retrieval or S3 Glacier Deep Archive storage class, your objects remain in Amazon S3. You can't access them directly through the separate Amazon S3 Glacier service.
You can also change the storage class of an object that is already stored in Amazon S3 to any other storage class by making a copy of the object using the PUT Object - Copy API. However, you can't use PUT Object - Copy to copy objects that are stored in the S3 Glacier Flexible Retrieval or S3 Glacier Deep Archive storage classes.
When setting up a replication configuration, you can set the storage class for replicated objects to any other storage class. However, you can't replicate objects that are stored in the S3 Glacier Flexible Retrieval or S3 Glacier Deep Archive storage classes.
Upload
In:
response = s3.put_object(
Body=open("/tmp/test.txt", mode="rb").read(),
Bucket="<bucket_name>",
ContentType="text/plain",
Key="glacier_deep_archive.txt",
StorageClass="DEEP_ARCHIVE",
)
pp(response)
Out:
{'ResponseMetadata': {'RequestId': 'R4R72F9Q2G9SM6VG',
'HostId': 'MiLEX5uVPZVA6MMsUSvC6Cpr8gmwm32+4COjBsoyna3YTd8qzu0hK0P8d5/AoiIH4yNSHHYPznE=',
'HTTPStatusCode': 200,
'HTTPHeaders': {'x-amz-id-2': 'MiLEX5uVPZVA6MMsUSvC6Cpr8gmwm32+4COjBsoyna3YTd8qzu0hK0P8d5/AoiIH4yNSHHYPznE=',
'x-amz-request-id': 'R4R72F9Q2G9SM6VG',
'date': 'Thu, 30 Jun 2022 16:02:59 GMT',
'etag': '"02bcabffffd16fe0fc250f08cad95e0c"',
'x-amz-storage-class': 'DEEP_ARCHIVE',
'server': 'AmazonS3',
'content-length': '0'},
'RetryAttempts': 0},
'ETag': '"02bcabffffd16fe0fc250f08cad95e0c"'}
Download
In:
try:
response = s3.get_object(
Bucket="<bucket_name>",
Key="glacier_deep_archive.txt",
)
except Exception as e:
response = e.response
pp(response)
Out:
{'Error': {'Code': 'InvalidObjectState',
'Message': "The operation is not valid for the object's storage "
'class',
'StorageClass': 'DEEP_ARCHIVE'},
'ResponseMetadata': {'RequestId': 'FKEEHHMPNSJM40S6',
'HostId': 'BSHJyfecWLWAXV6IdeoPVeGHc1MiRSMOt2F8N3xP7lGg98oB5g66FqN/aM3d6sPSSVIhRRp2+Is=',
'HTTPStatusCode': 403,
'HTTPHeaders': {'x-amz-request-id': 'FKEEHHMPNSJM40S6',
'x-amz-id-2': 'BSHJyfecWLWAXV6IdeoPVeGHc1MiRSMOt2F8N3xP7lGg98oB5g66FqN/aM3d6sPSSVIhRRp2+Is=',
'content-type': 'application/xml',
'transfer-encoding': 'chunked',
'date': 'Thu, 30 Jun 2022 16:03:49 GMT',
'server': 'AmazonS3'},
'RetryAttempts': 0},
'StorageClass': 'DEEP_ARCHIVE'}
Restore
In:
response = s3.restore_object(
Bucket="<bucket_name>",
Key="glacier_deep_archive.txt",
RestoreRequest={
"Days": 1,
"GlacierJobParameters": {"Tier": "Standard"},
},
)
pp(response)
Out:
{'ResponseMetadata': {'RequestId': 'RMK3RSDYX8K67YF6',
'HostId': 'BHulkmJEPFzZ3CxNZKHZimaM/b3T3RNh/0lfGr3GY8MFbbSVEVVh8KASLIPvDlvTo3hJn3qlRd4=',
'HTTPStatusCode': 202,
'HTTPHeaders': {'x-amz-id-2': 'BHulkmJEPFzZ3CxNZKHZimaM/b3T3RNh/0lfGr3GY8MFbbSVEVVh8KASLIPvDlvTo3hJn3qlRd4=',
'x-amz-request-id': 'RMK3RSDYX8K67YF6',
'date': 'Thu, 30 Jun 2022 16:04:36 GMT',
'content-length': '0',
'server': 'AmazonS3'},
'RetryAttempts': 0}}
To download this object, I must wait about 12 hours because I used Standard tier for restoring.
Reduced Redundancy
Reduced Redundancy — The Reduced Redundancy Storage (RRS) storage class is designed for noncritical, reproducible data that can be stored with less redundancy than the S3 Standard storage class.
We recommend that you not use this storage class. The S3 Standard storage class is more cost effective.
For durability, RRS objects have an average annual expected loss of 0.01 percent of objects. If an RRS object is lost, when requests are made to that object, Amazon S3 returns a 405 error.
S3 Standard, RRS, S3 Standard-IA, S3 One Zone-IA, S3 Glacier Instant Retrieval, and S3 Intelligent-Tiering objects are available for anytime access.
Upload
In:
response = s3.put_object(
Body=open("/tmp/test.txt", mode="rb").read(),
Bucket="<bucket_name>",
ContentType="text/plain",
Key="reduced_redundancy.txt",
StorageClass="REDUCED_REDUNDANCY",
)
pp(response)
Out:
{'ResponseMetadata': {'RequestId': 'VWATQ8R24WMM18EH',
'HostId': 'Ji1YRB32KJJRNO4vpEWJzGiEm3Mw5rbt6JYLEFlG2/NAdydglDRCt7BzKaz3+OpJvIbID95VjKM=',
'HTTPStatusCode': 200,
'HTTPHeaders': {'x-amz-id-2': 'Ji1YRB32KJJRNO4vpEWJzGiEm3Mw5rbt6JYLEFlG2/NAdydglDRCt7BzKaz3+OpJvIbID95VjKM=',
'x-amz-request-id': 'VWATQ8R24WMM18EH',
'date': 'Thu, 30 Jun 2022 16:14:29 GMT',
'etag': '"02bcabffffd16fe0fc250f08cad95e0c"',
'x-amz-storage-class': 'REDUCED_REDUNDANCY',
'server': 'AmazonS3',
'content-length': '0'},
'RetryAttempts': 0},
'ETag': '"02bcabffffd16fe0fc250f08cad95e0c"'}
Download
In:
response = s3.get_object(
Bucket="<bucket_name>",
Key="reduced_redundancy.txt",
)
pp(response)
Out:
{'ResponseMetadata': {'RequestId': 'WX660QWG24QQRJAE',
'HostId': 'G8avj3zKBw2DO4pdsrScc3W1KVeO4C6yIQjcvfbOWevAbkVxlKmo4YM9UxZfacwqd4w3Yg4NxUY=',
'HTTPStatusCode': 200,
'HTTPHeaders': {'x-amz-id-2': 'G8avj3zKBw2DO4pdsrScc3W1KVeO4C6yIQjcvfbOWevAbkVxlKmo4YM9UxZfacwqd4w3Yg4NxUY=',
'x-amz-request-id': 'WX660QWG24QQRJAE',
'date': 'Thu, 30 Jun 2022 16:14:59 GMT',
'last-modified': 'Thu, 30 Jun 2022 '
'16:14:29 GMT',
'etag': '"02bcabffffd16fe0fc250f08cad95e0c"',
'x-amz-storage-class': 'REDUCED_REDUNDANCY',
'accept-ranges': 'bytes',
'content-type': 'text/plain',
'server': 'AmazonS3',
'content-length': '16'},
'RetryAttempts': 0},
'AcceptRanges': 'bytes',
'LastModified': datetime.datetime(2022, 6, 30, 16, 14, 29, tzinfo=tzutc()),
'ContentLength': 16,
'ETag': '"02bcabffffd16fe0fc250f08cad95e0c"',
'ContentType': 'text/plain',
'Metadata': {},
'StorageClass': 'REDUCED_REDUNDANCY',
'Body': <botocore.response.StreamingBody object at 0x7fcccb1328b0>}
Posted on June 30, 2022
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related