Breaking the 300 barrier

Shivam Chauhan
Posted on February 21, 2024

Everything has it’s limit and we Humans are known to break them!!
Sound’s speed being 343.2m/s seemed unbreakable to our species until 1947 when Bell X-1 piloted by U.S. Air Force Captain Chuck Yeager Breaks the Sound Barrier.
Why is it relevant to us? Well, in my current org, we were been limited by our servers to a speed of 300 requests served per minute per server hosted on a single Rails application served by the Puma webserver. This limit seemed unbreakable to us and we lived our days by that.
Today, I will take you through the process of how we broke this limit to 2200 RPM and an inspirational journey for us budding engineers to learn how to understand our servers and listen to these choke points.
Let’s discuss what happened and how we achieved it.
Backstory
Recently, we have been experiencing some Latency issues. The reason being the increase in our userbase as more companies are adopting our platform to do their procurement efficiently. Our core product is a monolith rails application served on AWS servers. We use AWS ELB's Application load balancer to swiftly balance the load on multiple servers and increase them when needed.
So, these sudden latency issues caused Load Balancer to aggressively scale up horizontally by adding more servers. This worked and made our latency back to an acceptable 200ms limit. But the catch is that this approach is not reliable enough to keep up with the cost.
After viewing the data from New Relics, we found out that our one server can go upto at max of 300 RPM limit and we thought this is what max a server can achieve.
Then what happened next?
I have always thought that yes increasing the number of servers works (up to a limit) but instead of just adding more instances, should we check if we have already used the last bit of compute which our current system can offer?
We use t2.2xlarge machines provided by AWS. These are powerful machines which made me wonder "how come these dam machines with 8 vCPU machine and 32GB of RAM can't handle more than 5 requests a second?". There's something wrong we are doing.
This curiosity made me dewl into the server’s instance, SSHed it and install the htop command.
sudo yum install htop
After that, started the htop command interface by
htop
and closely monitored the CPU and Memory usage of the instance. Then I copied some CURLs from our dashboard into Postman, made a collection of it and ran these collections in parallel with Newman CLI.
Here’s the screenshot of the htop commands while the server was in high load.
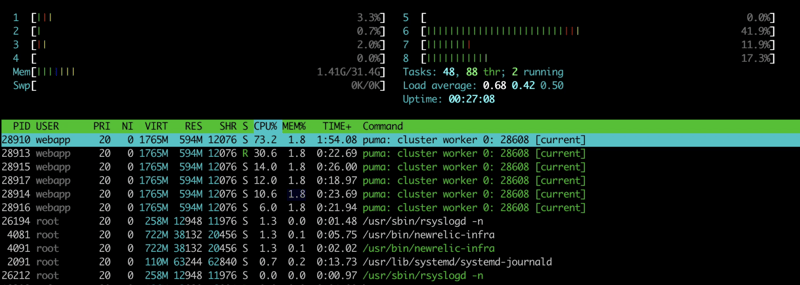
Do you see anything wrong in these images..??
With having so much load on the system, still only 1 particular vCPU number #6 is getting to 40% utilisation while the rest are just lying idle with 1-2% usage. Also, our huge 32GB RAM seems like taking the day off and getting only 1.42 GB utilised.
This instantly made me realise that we are severely underutilising our resources. But how to fully utilise them?
As we use Puma as our webserver for our rails application, I quickly went to Puma's config file which typically resides in config/puma.rb. The config was set as
threads_count = ENV.fetch("RAILS_MAX_THREADS") { 5 }.to_i
threads threads_count, threads_count
# workers ENV.fetch("WEB_CONCURRENCY") { 2 }
PS: I have removed the unimportant stuff
This is mostly the default config template of Puma and was kept untouched since intial tweaks at beginning of the project a long time ago.
Here we can see terms such as threads_count and workers. These terms caught my eye and after some google search found out that Puma can utilise multiple cores of a machine by running multiple processes of the rails application. Puma terms these as workers. We can also define the number of threads to spawn up which can be beneficial in case of I/O block on the database.
According to our current config, we initialise 5 threads on a single Puma worker. Each thread can handle 1 request at a time. So we can deduce, that a single server can at most handle 5 requests at a time. Doing some mathematics, assuming 200ms average request response time, we can say that
(1/0.200) * 60 = 300
So, in theory, we can handle 300 requests per minute on a single server which was the assumption we started with.
After this, I decided to play with this configuration and see what we could achieve.
But, to go ahead I need a system to measure the metrics of our load testing. So I quickly set up Locust on my system. Locust is an open-source easy to setup load-testing framework.
Let's tweak the config
RAILS_MIN_THREADS = 1
RAILS_MAX_THREADS = 16
WEB_CONCURRENCY = 5
After running the test, these are the htop results.
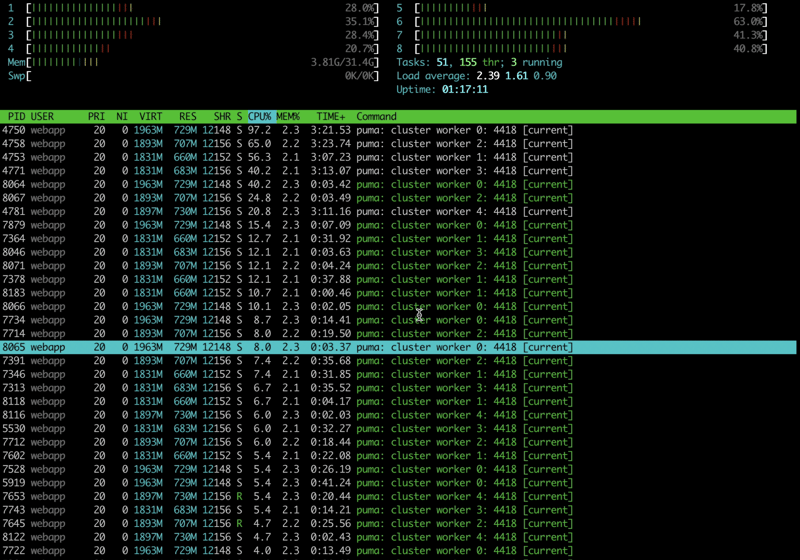
Kudos, now all our CPU cores are being utilised, but still they are not fully utilised. They are mostly at 35% on average.
A new question arises, What is the limit after which we can say we should stop burning more CPU?
Locust says that we had achieved a steady 29 RPS, which translates to approx 1700 RPM.

So, doing this little tweak we went from 300 to 1700 RPM. But what if we increase more workers..??
Now, let’s try increasing workers count to 7.
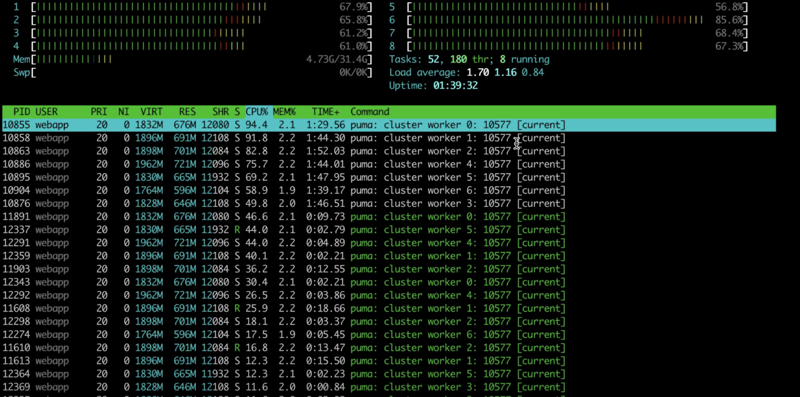
Here in htop, we can see that now our vCPUs are getting almost used to maximum limits.

Doing this we were able to achieve constant RPS of around 37 which translates to a whopping 2200 RPM.
I did many other tests with different worker counts and found 5 being a suitable number for our usecase but it can vary for your application drastically.
Here's a puma config which works best for Gitlab -> https://gitlab.com/gitlab-org/gitlab/-/blob/master/config/puma.rb.example?ref_type=heads
Wrapping it up
This was a great learning experience for me, where diving deep into the system helped me understand how code is actually running and serving our users.
Happy coding and learning!
Visit my website at shivam.fyi
Posted on February 21, 2024
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related