Finding Meow 😺 — the cutest cat from each town using Elasticsearch

Shashank Sharma
Posted on May 26, 2020
#cutest-cat-per-town
Cat fact: Meow is one of the most common names for a cat (for obvious reasons 😸).
While researching for this article, I realized there are plenty of people who love cats. There are numerous websites to suggest names for cats, see www.findcatnames.com for example. iknowwhereyourcatlives.com is an interesting data visualization experiment that locates a sample of one million public images of cats in the world. To be honest, this is a core reason I finalized on cats as an example for this article. 😉
Let’s get into understanding the problem statement itself:
Find the most cutest cat named Meow from each town.
In a town, there would be many cute cats. We have to pick only one cutest cat from each town, whose name is Meow.
This problem statement is an example of a typical greatest-n-per-group query (hence cutest-cat-per-town). Interestingly, this question comes up several times per week on StackOverflow. To be accurate, at the time of writing this article, there are 10,206 questions with the tag *greatest-n-per-group *and counting.
Let’s take a small dataset of cats with the columns id, cat name, town, and cuteness level ranging from 1 to 10, 10 being most cutest.
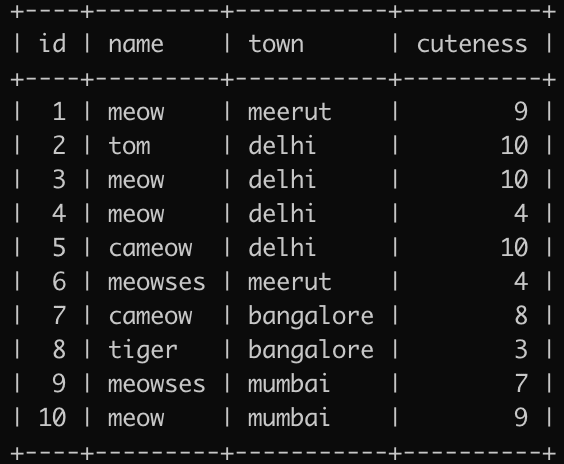
The expected output per this dataset would be :

Before jumping to Elasticsearch, let’s see how we can achieve this using SQL. There are quite a few ways to go about this, and depending on the database; there can be better performance-oriented solutions too. One which works across databases is:
SELECT * FROM cat c4 where id in (SELECT MIN(c1.id)
FROM cat c1
JOIN(SELECT c2.town,
MAX(c2.cuteness) AS max_cuteness
FROM cat c2
WHERE c2.name LIKE "%meow%"
GROUP BY c2.town) c3 ON c3.town = c1.town
AND c3.max_cuteness = c1.cuteness AND c1.name LIKE "%meow%"
GROUP BY c1.town;
We are not going in detail with the SQL solution, as the objective is to solve using Elasticsearch. However, feel free to drop in a comment in case you want me to explain anything in particular.
Let’s jump to Elasticsearch to solve this problem.
Brief about Elasticsearch as per Wikipedia.
Elasticsearch is a search engine based on the Lucene library. It provides a distributed, multitenant-capable full-text search engine with an HTTP web interface and schema-free JSON documents. Elasticsearch is developed in Java and is released as open source under the terms of the Apache License.
A local setup of Elasticsearch and Kibana (optional) would be great to follow along. If you already have one, it’s perfect. Else I suggest to install it to try out the scripts yourself. Follow instructions from the official Elasticsearch website to install it locally. Or if it appears to be too cumbersome (it’s actually not), you can use cloud services like Elasticsearch Cloud (14 days free trial, no credit card required) or bonsai.io (free plan available with no credit card required). Personally, I tried bonsai.ai and within 5 minutes I was running queries on Kibana provision by bonsai.io. Superb. 🤓
Even if that’s too much effort 🙄, use this playground for search queries.
Oh, and I forgot to introduce Kibana. Kibana as per Wikipedia.
Kibana is an open source data visualization dashboard for Elasticsearch. It provides visualization capabilities on top of the content indexed on an Elasticsearch cluster. Users can create bar, line and scatter plots, or pie charts and maps on top of large volumes of data.
With whichever option you selected, let’s start with creating a new index cat and bulk import our dataset.
If you are using Kibana, just copy & paste the query below to create a new index cat with properties id , name , town & cuteness .
PUT cat
{
"mappings": {
"properties": {
"id": {
"type": "long"
},
"name": {
"type": "keyword"
},
"town": {
"type": "keyword"
},
"cuteness": {
"type": "short"
}
}
}
}
To bulk import, the sample data, copy & paste below query.
PUT _bulk
{ "index" : { "_index" : "cat", "_id" : "1" } }
{ "id" : 1, "name":"meow", "town":"meerut", "cuteness":9 }
{ "index" : { "_index" : "cat", "_id" : "2" } }
{ "id" : 2, "name":"tom", "town":"delhi", "cuteness":10 }
{ "index" : { "_index" : "cat", "_id" : "3" } }
{ "id" : 3, "name":"meow", "town":"delhi", "cuteness":10 }
{ "index" : { "_index" : "cat", "_id" : "4" } }
{ "id" : 4, "name":"meow", "town":"delhi", "cuteness":4 }
{ "index" : { "_index" : "cat", "_id" : "5" } }
{ "id" : 5, "name":"cameow", "town":"delhi", "cuteness":10 }
{ "index" : { "_index" : "cat", "_id" : "6" } }
{ "id" : 6, "name":"meowses", "town":"meerut", "cuteness":4 }
{ "index" : { "_index" : "cat", "_id" : "7" } }
{ "id" : 7, "name":"cameow", "town":"bangalore", "cuteness":8 }
{ "index" : { "_index" : "cat", "_id" : "8" } }
{ "id" : 8, "name":"tiger", "town":"bangalore", "cuteness":3 }
{ "index" : { "_index" : "cat", "_id" : "9" } }
{ "id" : 9, "name":"meowses", "town":"mumbai", "cuteness":7 }
{ "index" : { "_index" : "cat", "_id" : "10" } }
{ "id" : 10, "name":"meow", "town":"mumbai", "cuteness":9 }
*All the Elasticsearch scripts are tested on Elasticsearch 7.2 version.
To improve accuracy, we will change the solution to give more preference to exact match than the partial match and have the result ordered by cuteness.
First, let’s start with the search query to get the cats with the name meow. We can have a simple wildcard query, but we also need to boost the score for the exact match. For that, we will use the function_score query with two functions (Line no.13 & 20 below), giving more weight to an exact match. The function_score allows you to modify the score of documents that are retrieved by a query. This is how our search query will look like:
1. GET cat/_search/
2. {
3. "size": 10,
4. "query": {
5. "function_score": {
6. "query": {
7. "wildcard": {
8. "name": "*meow*"
9. }
10. },
11. "boost": "5",
12. "functions": [{
13. "filter": {
14. "match": {
15. "name": "meow"
16. }
17. },
18. "weight": 2
19. }, {
20. "filter": {
21. "wildcard": {
22. "name": "*meow*"
23. }
24. },
25. "weight": 1
26. }]
27. }
28. }
29. }
Now let’s look at the aggregation part. In Elasticsearch, we can do aggregation on the search query. There are multiple aggregation techniques. In our case, will use term based aggregation which belongs to the bucketing family. For better understanding, let’s look at the final query first. Use this link to execute and try it yourself.
1. GET cat/_search/
2. {
3. "size": 0,
4. "query": {
5. "function_score": {
6. "query": {
7. "wildcard": {
8. "name": "*meow*"
9. }
10. },
11. "boost": "5",
12. "functions": [{
13. "filter": {
14. "match": {
15. "name": "meow"
16. }
17. },
18. "weight": 2
19. }, {
20. "filter": {
21. "wildcard": {
22. "name": "*meow*"
23. }
24. },
25. "weight": 1
26. }]
27. }
28. },
29. "aggs": {
30. "group": {
31. "terms": {
32. "field": "town",
33. "order": {
34. "max_cuteness": "desc"
35. }
36. },
37. "aggs": {
38. "group_docs": {
39. "top_hits": {
40. "size": 1,
41. "sort": [{
42. "cuteness": {
43. "order": "desc"
44. }
45. }, {
46. "_score": {
47. "order": "desc"
48. }
49. }]
50. }
51. },
52. "max_cuteness": {
53. "max": {
54. "script": "doc['cuteness'].value"
55. }
56. }
57. }
58. }
59. }
60. }
As we need to create one bucket per town, I have added "field": "town" in terms aggregation. This will give us multiple cats per town, but we need only the cutest hence we will use sub aggregation. Look at the block from line 37 above. I have added two sub aggregation *group_docs *and *max_cuteness. *group_docs is a * top_hits aggregation where I have configured to return only one record sort based on the cuteness and the search query score. This aggregation will help to produce only one record per bucket.
Now we also need to order the buckets based on the max cuteness per bucket. For this, I have defined *max_cuteness *sub aggregator of max aggregation. It returns max cuteness per town which I am using in the primary group aggregator at line 34 to order each bucket. At line 2, "size": 0 is only to return the aggregated result.
To summarize, for this query, I have used function_score query, terms, top_hits and max aggregations to solve the cutest*-cat-per-town *problem. Thanks for reading! Do comment if you have any doubts or you feel you know a better way to “Find Meow!”

P.S: Ready for the cutest-cat-per-town *challenge? Tweet your best solution for SQL or Elasticsearch with the hashtag #*cutest-cat-per-town, #findingmeow👨💻 or comment below. If we find your solution better than ours, we will include your submission along with your name. Use this playground to test and share your solution.
If you liked the article, please like the article and help others see it. Meow would appreciate that *😻. Follow me for other such articles.*
Posted on May 26, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.