Design principles for architectural reliability in AWS

Yogesh Sharma
Posted on September 18, 2022

The aim of reliability is to preserve the effect of any failure to the smallest location viable. By getting ready your device for the worst, you may put in force quite a few mitigation strategies
for the extraordinary additives of your infrastructure and applications. Before a failure occurs, you need to check your restoration procedures. It is vital to strive to automate restoration as lots as viable to lessen the opportunity of human error. The following are the usual layout concepts that assist you to reinforce your device reliability.
Self-healing Systems
System failure desires to be anticipated in advance, and withinside the case of failure incidence, you should have an automatic reaction for system recovery/self-heal. Self-recovery is the ability to mechanically get over failure. A self-sealing machine detects failure proactively and responds to it gracefully with minimal customer impact. Failure can manifest in any layer of your whole machine, which includes hardware failure, community failure, or software program failure. Usually, statistics middle failure isn't always an everyday event, and greater granular tracking is needed for common disasters such as database connection and community connection disasters. You should apply automation around monitoring so that the system can self-heal in the event of any incidents. For example, add more servers when CPU or Memory utilization reaches near 50%—proactive monitoring helps to prevent failures.

Embrace and Apply Automation
Automation is the important thing to enhancing your utility's reliability. Try to automate the entirety from utility deployment and configuration to the general infrastructure. Automation affords you with agility in which your group can pass speedy and experiment extra often. You can mirror the whole machine infrastructure and the surroundings with a unmarried click on to attempt a brand new feature. Detecting unhealthy/bad sources and launching substitute sources can be automated, and you could notify the IT operation crew whilst sources are changed. Automation is a key layout precept that desires to use anywhere to your system.
Build a Distributed System
Monolithic programs have low reliability in relation to device uptime, as one small problem in a specific module can convey down the whole device. Dividing your software into more than one small offerings reduces the effect area, in order that problem is one a part of the software should not effect the complete device, and the software can preserve to serve vital functionality. For example, in a retail website, an problem with the Garment section should no longer have an effect on customer's payment gateway. At the service level, scale your application horizontally to increase system availability. Design a system so that it can use multiple smaller components working together rather than a single monolithic system to reduce the impact area.
ALM-Alerting, Logging, & Monitoring
Always generate logs from your custom application and integrate every component with centralise logging platform- cloudwatch, splunk, logit etc
You need an environment where you don't need to guess capacity, and your application can scale on-demand. A public cloud provider such as AWS provides Infrastructure-as-a-Service (IaaS), which facilitates the on-demand availability of resources. In the cloud, you can monitor system supply and demand. You can automate the addition or removal of resources as needed. It allows you to maintain the level of resources that will satisfy demand without over-provisioning or under-provisioning.
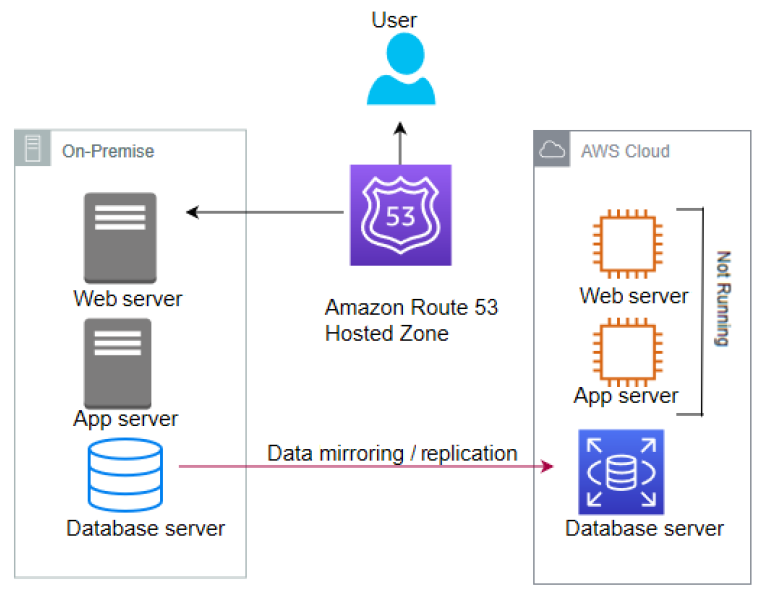
Recovery Validation
Recoverability is sometimes overlooked as a component of availability. To improve the system's Recovery Point Objective (RPO) and Recovery Time Objective (RTO), you should back up data and applications along with their configuration as a machine image. In the event that a natural disaster makes one or more of your components unavailable or destroys your primary data
source, you should be able to restore the service quickly and without lost data.
Always, invest energy and time in designing the solution for future.
Posted on September 18, 2022
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related