Chat Bot SFEIR Brain: découverte du Natural Language Processing

Thibault Henry
Posted on April 4, 2022

Bonjour à tous les lecteurs,
[...]
J'ai écrit cet article sur Medium fin 2021 alors l'introduction est un peu datée. Voici le lien original
[...]
L'année 2021 touche à sa fin, et pour moi, voilà déjà deux ans que j'ai signé mon premier CDI chez SFEIR Luxembourg.
Deux ans, ça paraît loin : on ne parlait pas encore du Covid et de tous ses variants à ce moment-là !
Pour l'occasion, je vous propose un retour d'expérience sur le sujet principal de mon stage de fin d'études que j'ai réalisé chez SFEIR avant de devenir un véritable collaborateur en novembre 2019.
Comme vous avez pu le comprendre avec le titre de cet article, ce stage portait sur la réalisation d'un assistant conversationnel dénommé SFEIR Brain.
Avant de plonger dans le vif du sujet, je souhaite créditer les 3 autres personnes avec qui j'ai travaillé sur ce projet : Julien Derigny, Sullivan Vanet & Sylvain Bruyère.
SFEIR Brain, qu'est-ce que c'est, à quoi ça sert ?
Vous le savez sûrement, SFEIR utilise pour sa gestion interne la « G Suite », qui est une suite d'outils de productivité destinée aux professionnels. En particulier, elle utilise Google Agenda, Gmail, Google Drive, pour manager son organisation et gagner en agilité : création de groupes de partage de documents, planification des échéances sur l'agenda de ses collaborateurs.
Cependant, la gestion de ces nombreux fichiers partagés peut parfois être laborieuse pour les collaborateurs et l'équipe administrative.
De là est née l'idée que pour certaines tâches rébarbatives, nous pouvions mettre en place un chat bot qui serait en mesure d'interpréter des informations et effectuer de la collecte des données.
Par exemple, on peut penser à la demande de congés des sfeiriens, ou à la réservation des places de parking de l'ancienne location de SFEIR à Leudelange (Luxembourg).
L'objectif était donc le suivant : réaliser un outil d'aide pour les sfeiriens permettant de leur libérer du temps, afin réaliser des tâches spécifiques à leur cœur de métier, à plus haute valeur ajoutée.
Définition du besoin
Pour faire gagner du temps aux sfeiriens, il fallait d'abord savoir ce dont ils avaient réellement besoin.
J'ai transmis aux personnes présentes à l'agence différents questionnaires où elles devaient renseigner leur rôle dans l'entreprise et ce qui pourrait les aider dans la vie de tous les jours.
Une fois la liste des besoins complétée, il était nécessaire de sélectionner une application capable de comprendre les demandes des utilisateurs en langage naturel, de déterminer des intentions à travers des discussions simples ou complexes, mais aussi de collecter des données et paramètres à prendre en compte afin de formuler une réponse adéquate.
Comme la durée de stage était limitée, nous avons choisi une solution toute faite proposée par Google, à savoir : DialogFlow.
En plus de développer les fonctionnalités demandées, Guillaume Homberg (notre maître de stage), nous a demandé de rendre l'application malléable, pour que n'importe quel développeur puisse facilement fournir davantage de fonctionnalités réalisables par l'assistant.
Autant dire que pour les stagiaires à peine sortis d'école que nous étions, la barre était haute pour fournir une application évolutive, disponible sur le Cloud et interfaçable avec une messagerie instantanée.
Contexte et origine du projet
L'idée de réaliser un tel chat bot n'est pas récente, car en 2018 une précédente équipe de stagiaires avait déjà tenté l'expérience.
Ils avaient utilisé des services sur le cloud Google (GCP pour Google Cloud Platform), le tout organisé autour une architecture en microservices communiquant à travers l'agent de message broker Pub/Sub.
Chaque microservice était déployé grâce à l'outil App Engine. Ce service permet d'administrer des applications sans avoir à s'occuper de la gestion des infrastructures serveur sous-jacentes.
Le renouvellement de ce projet a donc débuté à partir de la fin juin 2019 sur la GCP.
Nous avons premièrement cherché à comprendre l'interaction entre les différents services utilisés par nos prédécesseurs et l'architecture du code implémenté.
Ensuite, nous avons migré sur une base de données Firestore (un autre service de la plateforme), les données du précédent projet hébergées sur le service Datastore (ancêtre de Firestore).
En parallèle au travail effectué sur la GCP, une partie de l'équipe a démarré la reprise du service DialogFlow pour le traitement du langage naturel.
L'atout majeur de DialogFlow, c'est son large panel d'intégrations à des services de messagerie, dont Workplace, la messagerie utilisée en interne chez SFEIR.
Nos prédécesseurs utilisaient également Dialogflow, mais il s'agissait de la première version. Malheureusement, cette version 1 était une bêta et est rapidement devenue obsolète.
Quand nous avons repris le flambeau, une année plus tard, plus rien ne fonctionnait. Notre sujet reposait donc sur la reprise de ce projet innovant.
Reprise du projet et contraintes
Au début du projet, il a été décidé que nous reprendrions la même base technologique que celle définie par la précédente équipe.
Pour vous donner une idée plus précise, voici un graphique sur la structure du projet à ce moment-là :

Voici une description ce graphique :
- le système dispose de plusieurs canaux de communication, ou « Topic », par lesquels circulent des instructions sous forme de messages JSON.
- via le canal « GatewayTopic », des instructions circulent entre le système central et le service DialogFlow qui traite les intentions des utilisateurs.
- les messages envoyés vers DialogFlow traversent d'abord le service « format » qui construit un JSON décrivant comment la réponse sera affichée sur la messagerie de l'utilisateur (Workplace chat).
- chaque fonctionnalité (tâche, scénario) du chat bot dispose de son propre microservice déployé via un App engine (sur la droite du graphique).
- le service « orchestrator » va interpréter les messages en provenance de Dialogflow pour déterminer le type de tâche à exécuter, et transmettra cette information au service concerné via le canal « MainTopic ».
- le système dispose d'un traitement des journaux global pour pouvoir déboguer en cas de soucis.
Comme vous pouvez le voir, l'architecture déjà en place faisait sens et était déjà bien pensée à l'époque.
Seulement voilà, après quelques semaines d'études et de tentatives pour redémarrer le tout, nous ne parvenions pas à refaire fonctionner le chat bot comme à l'origine.
Nous avions notamment des gros problèmes de temps de réponse dus au fait que l'échange des messages entre les multiples microservices était lent.
En fonction de la requête de l'utilisateur, plusieurs microservices pouvaient être impliqués et les délais de réponse étaient encore plus grand lorsque les App engines étaient en mode « sommeil ».
Tout cela nous a mené à une contrainte technique majeure sur Dialogflow : si le délai de réponse après un message dépasse les 5 secondes, alors aucune réponse n'est envoyée.
L'origine du problème vient du fait les instances du service App Engine, qui représentent chacune un microservice, sont mises en veille lorsqu'elles ne sont pas utilisées pendant une certaine période.
Or, l'émission d'une requête sur DialogFlow provoque l'éveil des instances impliquées, qui dure parfois jusqu'à une seconde. Dès qu'une requête parcourt une petite chaîne de microservices endormis, elle doit les réveiller un par un.
Ce faisant, la réponse ne parvient pas jusqu'à l'utilisateur, car son traitement dépasse la limite instaurée par DialogFlow.
Nous avons d'abord pensé à contourner ce problème en envoyant un message via un autre flux pour simuler une réponse plus tardive, mais tout compte fait, qui voudrait utiliser un chat bot qui met trop de temps à répondre ?
Il fallait trouver une solution plus robuste au problème.
Une architecture hybride : l'approche microlithique
Afin d'améliorer les performances de l'application SFEIR Brain, il a fallu réduire le chaînage des microservices pour réduire le temps d'activation des services après une période d'inactivité prolongée.
Avant de mettre en place une telle solution qui bouleverserait grandement l'architecture du projet, nous avons pris la décision de migrer le code source à l'identique, sans modifier la structure en microservices, sur un nouveau service prometteur de la GCP : les Cloud Functions.
Le service des Cloud Functions correspond à un outil avec lequel il est possible de définir des environnements d'exécution destinés à lancer des programmes simples et légers. Avec ces fonctions, il est possible d'implémenter des programmes courts directement via l'interface web sur la GCP, et qui se déclenchent grâce à des événements émis par d'autres services cloud de la plate-forme ou plus simplement par un événement externe. Il est possible d'utiliser différents langages de programmation parmi lesquels le Go (version 1.11 à l'époque), qui est celui que nous avons décidé d'utiliser.
Les Cloud Functions semblent être une solution adéquate pour déployer un environnement d'exécution unique pour chacun des microservices développés en 2018, à l'image des instances du service App Engine.
L'idée de cette première investigation n'était pas de migrer l'intégralité des microservices existants pour possiblement revenir en arrière en cas d'échec. Au contraire, j'ai choisi de cibler une fonctionnalité de l'assistant précise et relativement peu complexe, impliquant un petit nombre
de microservices.
J'ai donc choisi de tester le cheminement de la requête de demande d'ancienneté d'un collaborateur, impliquant les microservices suivants :
- Point d'entrée DialogFlow : il récupère la requête émise par DialogFlow à l'application interne.
- Gateway : il récupère la requête transformée et utilisable dans le système interne afin de la diriger vers l'entrée ou la sortie de l'application.
- Orchestrator : il définit l'ensemble des microservices que va parcourir la requête jusqu'à l'émission d'une réponse.
- Identification : il identifie le collaborateur dont on veut connaître l'ancienneté.
- Collaborator : il récupère l'ancienneté du collaborateur identifié.
- Format : il met en forme la réponse pour qu'elle soit lisible par l'utilisateur final.
L'objectif est clair : que la requête traverse l'ensemble de ces microservices, déployés grâce à des Cloud Functions, en moins de cinq secondes.
Cependant, pour communiquer entre elles, les Cloud Functions utilisent le service cloud Pub/Sub de la plate-forme Google. Elles doivent pour cela utiliser une bibliothèque en langage Go permettant de se connecter au service et envoyer des données.
Or, l'initialisation de la connexion est non-négligeable en termes de temps d'exécution, et puisque les fonctions sont éphémères, aucune variable n'est sauvegardée en mémoire, ce qui entraîne que la connexion doit être réalisée à chaque nouvelle requête.
Dans le parcours classique d'une requête, comme celui présenté précédemment, la connexion au service Pub/Sub est donc établie plusieurs fois et cela a pour effet d'allonger le temps de réponse de l'application.
Ce laps de temps est variable, mais il s'est avéré à de multiples reprises, durant
une batterie de tests, que la réponse ne parvenait pas jusqu'à l'utilisateur, car l'incontournable limite des cinq secondes était dépassée.
Une telle architecture n'est donc pas envisageable.
Après longue réflexion, il a été décidé d'instaurer une architecture originale et hybride : l'architecture microlithique.
Le principal objectif de cette approche est d'utiliser la puissance et la rapidité d'exécution des Cloud Functions en réduisant au maximum leur nombre, pour réduire les délais de communication.
En résumé, une architecture microlithique reprend les concepts d'une architecture monolithique, mais se sépare des tâches lourdes en les assignant à des cloud functions travaillant de manière asynchrone.
Dans le cas précis de SFEIR Brain, il est possible d'agglomérer la majorité des anciens microservices en une seule cloud function de plus grande envergure. L'établissement de communications via Pub/Sub se marginalise ainsi à la réalisation asynchrone de travaux chronophages,
comme la génération de fichiers sur Google Drive par exemple.
Grâce à cette nouvelle manière de concevoir l'application, les performances de l'assistant conversationnel ont été considérablement accrues avec des temps de réponse inférieurs à 200 millisecondes.
Voici un schéma de l'architecture réalisée :

Voici un exemple de cheminement d'une requête au sein de SFEIR Brain : la génération d'une fiche de congés pour un collaborateur.
- La requête est transmise par DialogFlow à la fonction représentant le point d'entrée de l'application.
- La fonction correspondante à cette tâche sera déclenchée par l'envoi d'un message spécifique sur le service Pub/Sub de la GCP.
- En parallèle, l'élaboration de la réponse pour l'utilisateur se déroule sans perturbation : ainsi, il recevra un lien temporaire redirigeant vers le fichier demandé lorsque sa génération sera terminée.
D'autres tâches, indépendantes de DialogFlow, ont été déployées dans des fonctions cloud qui s'exécutent périodiquement grâce au service Google Scheduler.
Ces fonctions sont destinées à mettre à jour la base de données Firestore ou à supprimer les fichiers trop datés sur le dépôt Google Drive de l'entreprise.
Pour les requêtes plus basiques, le traitement suit une démarche scénarisée prédéfinie par notre équipe au sein de la base de données Firestore, qui liste l'ensemble des possibilités du chat bot et les étapes à suivre pour répondre correctement à l'utilisateur.
Scénarisation des requêtes
Pour obtenir une réponse en cohérence avec la requête effectuée par l'utilisateur, il nous a fallu définir des scénarios d'exécution pour chacune des fonctionnalités implémentées.
Chaque fonctionnalité est identifiée par l'action reconnue par DialogFlow, et qui correspond à une simple chaîne de caractère :

Une fois l'action connue et identifiée dans la fonction principale, le cheminement correspondant est récupéré sur la base de données Firestore.
Un scénario est une série d'instructions à exécuter pour obtenir la réponse finale.
Par exemple, pour la connaître l'ancienneté d'un collaborateur, le scénario sera le suivant :
- « IdentifyCollaborator »
- « GetCollaboratorSeniority »
Intégrée dans la boucle scénaristique, cette liste d'instructions déclenchera un par un des modules du code source de la Cloud Function principale.
Le résultat de chaque module lié à une instruction sera stocké dans la requête lors de son parcours et pourra être utilisé par les modules suivants pour construire progressivement une réponse complète.
Ce mécanisme de scénarisation a pour but de rendre l'ajout de fonctionnalités dans le code source évolutif et le plus simple possible, comme on nous l'avait demandé au début du projet.
Formatage des réponses
La dernière étape avant d'envoyer la réponse à l'utilisateur est d'embellir son apparence dans un processus de formatage.
En général, une réponse énoncée sous la forme d'un simple texte est suffisante pour pouvoir être comprise facilement par l'utilisateur.
En revanche, quand la quantité d'informations à transmettre est conséquente, la compréhension d'une réponse uniquement textuelle est complexe.
L'idée était donc d'étendre le champ des possibles dans l'affichage des informations obtenues après la requête d'un collaborateur.
Sullivan et Sylvain ont beaucoup travaillé sur ce sujet pour paramétrer le message transmis à l'utilisateur. Outre le texte, il est possible de créer les éléments suivants pour un message :
- les réponses rapides
- les boutons
- les cartes
- les images
- les vidéos

Ils ont défini un format d'affichage pour chaque action répertoriée dans la base de données Firestore, utilisé pour améliorer la compréhension de la réponse.
Plus précisément, ils ont construit un système de formatage très puissant qui permet de passer d'une syntaxe customisée à une réponse JSON compréhensible par DialogFlow :
<Response>
<Cards>
<Card>
<Card.Title>
Feuille de congés
</Card.Title>
<Card.Subtitle>
Votre fichier sera accessible pendant 24 heures
</Card.Subtitle>
<Card.Buttons>
<Button Type="Url" Data="{{obj.GetWaitingWebsiteURL()}}" ModalFormat="Medium">
Accéder à la feuille
</Button>
</Card.Buttons>
</Card>
</Cards>
</Response>
Format de l'action « GenerateLeaveRequest »
Une partie de ce travail a été réutilisé pour le chat bot Neo Jarvis que vous avez peut-être déjà utilisé.
Configuration de DialogFlow
Pour fonctionner, DialogFlow a besoin qu'un utilisateur lui transmette des données à traiter pour détecter l'intention principale et en déduire ensuite les actions à mettre en œuvre.
L'outil se base sur la technologie du « machine learning », avec des algorithmes très techniques et entraînés par Google.
Dans l'absolu, DialogFlow peut être considéré comme une boîte noire dont on ne connaît pas le fonctionnement exact, c'est-à-dire, la description des algorithmes de traitement du langage naturel, mais qui peut être configurée afin de répondre à un besoin précis.
De cette manière, il est possible à partir d'une simple phrase, de déterminer des paramètres comme un nom, prénom, ou une date, d'identifier des entités listées au préalable, de répondre immédiatement à l'utilisateur en suivant des schémas de dialogue prédéfinis, dans le but de réaliser une action.
Bien que l'aspect technique des algorithmes de machine learning ne nous soit pas accessible, le parcours d'une requête est lui bien connu :
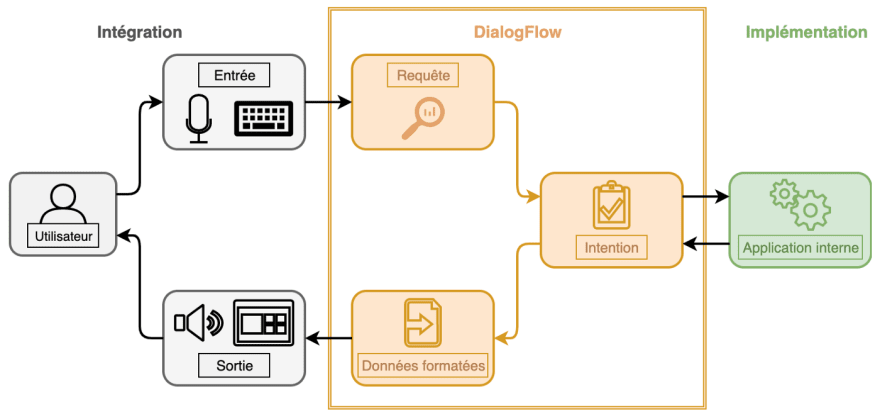
Diaflow va alors essayer de comprendre la requête pour extraire une intention :
- Soit l'intention est très simple : par exemple si l'utilisateur écrit ou dit "Bonjour", le chat bot pourra répondre directement et par lui-même à l'utilisateur grâce à l'option Small Talks de l'outil DialogFlow.
- Soit l'intention est liée à un dialogue : le chat bot va donc répondre directement à l'utilisateur en poursuivant la conversation pour obtenir des informations supplémentaires.
- Soit l'intention est complexe et nécessite un traitement spécifique : dans ce cas, le chat bot dirige la requête vers l'application interne.
Pour le processus d'identification de l'intention, il est nécessaire de définir une liste d'intentions possibles du système.
Chaque intention dispose d'une liste de phrases d'entraînement, de paramètres et d'une action.
Les paramètres peuvent être utilisés dans les phrases d'entraînement, ce qui permet d'affiner la détection de l'intention exacte de l'utilisateur :

Ainsi, pour déterminer quelle est l'intention la plus probable que souhaite transmettre l'utilisateur, DialogFlow compare la phrase en entrée du système avec l'ensemble des phrases d'entraînement existantes dans la liste des intentions.
Une fois la bonne intention ciblée, le processus se poursuit et s'il s'agit d'une requête complexe, une action pourra être exécutée par le backend de SFEIR Brain.
Vidéo de démonstration
Pour finir cet article en beauté, je vous propose de regarder cette courte vidéo présentant le chat bot en action :
(petite précision: la partie formattage n'était pas encore finalisé au moment de la vidéo, et c'est pour cela que les réponses du bot sont brutes)
Conclusion
Aujourd'hui, le chat bot SFEIR Brain n'est plus actif à cause d'une politique de sécurisation de Workplace qui a rendu difficile l'intégration de chat bot customisé. Le code, les données, les Cloud Functions, etc, sont toujours disponibles sur la GCP mais inutilisés.
Malgré tout, cette aventure était vraiment intéressante, je ne pensais pas travaillé sur un projet aussi complexe techniquement que celui-ci pour un stage de fin d'études.
Ce que j'ai le plus apprécié, c'est que nous avons eu un paquet de soucis pour mettre en place ce chat bot, mais nous avons toujours réussi à nous en sortir. En plus de ça, on avait une équipe de choc avec une bonne ambiance, c'était vraiment un projet cool à réaliser !
Je vous remercie d'avoir lu cet article et j'espère que vous avez pu en apprendre un peu plus sur la conception d'un chat bot hébergé sur le Cloud Google, à travers les yeux de novices stagiaires.
À bientôt,
Thibault HENRY
Posted on April 4, 2022
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related