Kubernetes: Service, load balancing, kube-proxy, and iptables

Arseny Zinchenko
Posted on November 1, 2020

One day I wondered — how is load balancing between pods working in Kubernetes?
I.e. — we have an external Load Balancer. Then a Service. And behind it — Pods.
What happens when we are receiving a network packet from the world, and we have a few pods — how the traffic will be distributed between them?
- kube-proxy
- User space proxy mode
- iptables proxy mode
- IPVS proxy mode
- kube-proxy config
- Kubernetes Pod load-balancing
- AWS LoadBalancer traffic modes
- kube-proxy and iptables
- iptables rules
kube-proxy
So. the rouning rules between pods between a Service and its Pods are controlled by the kube-proxy service that can be working in one of the three following modes - user space proxy mode , iptables proxy mode , and IPVS proxy mode.
User space proxy mode
Links:
A deprecated mode, previously was the default.
When using this mode, kube-proxy watch for changes in a cluster and for each new Service will open a TCP port on a WorkerNode.
Then, iptables on this WorkerNode begin routing traffic from this port to the kube-proxy service which is acting as a proxy service using the round-robin approach, i.e. by sending traffic to a next pod in its backend's list. During this, kube-proxy can try to send a package to another pod if the first one didn't respond.
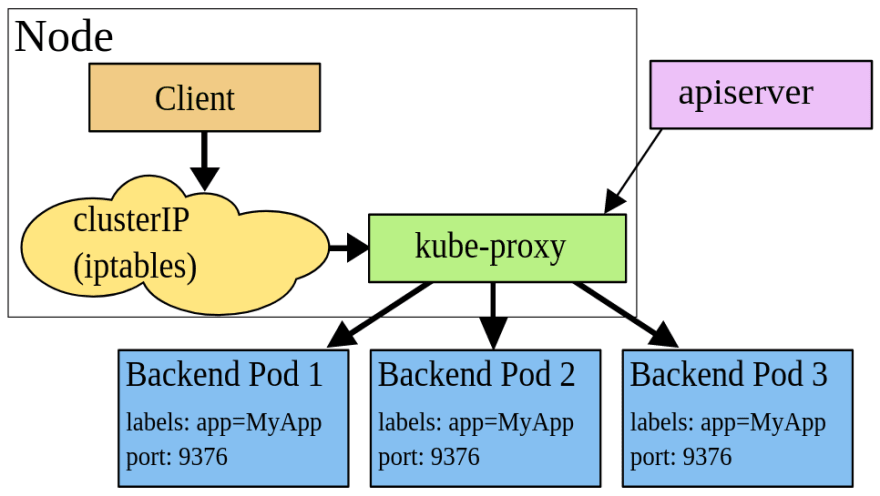
iptables proxy mode
Links:
Our case, which we will investigate in this post. Currently, is the default one.
When using this mode, kube-proxy watch for changes in a cluster and for each new Service will open a TCP port on a WorkerNode.
Then, the iptables on this WorkerNode sends traffic from this port to a Kubernetes Service which is actually a chain in the iptables rules, and via this chain, traffic goes directly to pods which are a backend for this Service. During this, a targeting pod is selected randomly.
This mode is less expensive for system resources as all necessary operations are performed in the kernel by the netfilter module. Also, this mode works faster and is more reliable because there is no a "middle-ware" - the kube-proxy itself.
But if the first pod where a packet was sent did not respond — then a connection fails, while in the user space proxy mode kube-proxy will try to send it to another pod.
This is why is so important to properly configure Readiness Probes, so Kubernetes will not send traffic to pods that are not ready to accept it.
Furthermore, this mode is more complicated for debugging, because in the user space proxy mode the kube-proxy will write its logs to the /var/log/kube-proxy, while with the netfilter you have to go to debug into the kernel itself.

IPVS proxy mode
Links:
And the most recent mode. It uses the netlink kernel module and creates new IPVS rules for new Kubernetes Services.
The main is the diversity of the load-balaning modes:
-
rr: round-robin -
lc: least connection (smallest number of open connections) -
dh: destination hashing -
sh: source hashing -
sed: shortest expected delay -
nq: never queue

kube-proxy config
Let’s go to check which mode is used in our case, in the AWS Lastic Kubernetes Service cluster.
Find kube-proxy pods:
$ kubectl -n kube-system get pod -l k8s-app=kube-proxy -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kube-proxy-4prtt 1/1 Running 1 158d 10.3.42.245 ip-10–3–42–245.us-east-2.compute.internal <none> <none>
kube-proxy-5b7pd 1/1 Running 0 60d 10.3.58.133 ip-10–3–58–133.us-east-2.compute.internal <none> <none>
…
kube-proxy-tgl52 1/1 Running 0 59d 10.3.59.159 ip-10–3–59–159.us-east-2.compute.internal <none> <none>
On every WorkerNode of the cluster, we have a dedicated kube-proxy instance with the kube-proxy-config ConfigMap attached:
$ kubectl -n kube-system get pod kube-proxy-4prtt -o yaml
apiVersion: v1
kind: Pod
…
spec:
…
containers:
…
volumeMounts:
…
- mountPath: /var/lib/kube-proxy-config/
name: config
…
volumes:
…
- configMap:
defaultMode: 420
name: kube-proxy-config
name: config
Check this ConfigMap content:
$ kubectl -n kube-system get cm kube-proxy-config -o yaml
apiVersion: v1
data:
config: |-
…
mode: “iptables”
…
Now, when we are more familiar with the kube-proxy modes - let's go deeper to see how it works and what iptables is doing here.
Kubernetes Pod load-balancing
For our journey, let’s take a real application with an Ingress (AWS Application Load Balancer, ALB) which sends traffic to a Kubernetes Service:
$ kubectl -n eks-dev-1-appname-ns get ingress appname-backend-ingress -o yaml
…
- backend:
serviceName: appname-backend-svc
servicePort: 80
…
Check the Service itself:
$ kubectl -n eks-dev-1-appname-ns get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
appname-backend-svc NodePort 172.20.249.22 <none> 80:31103/TCP 63d
Here we have the NodePorttype - it's listening to a TCP port on a WorkerNode.
The ALB e172ad3e-eksdev1appname-abac ALB routes the traffic from clients to the e172ad3e-4caa286edf23ff7e06d AWS TargetGroup:
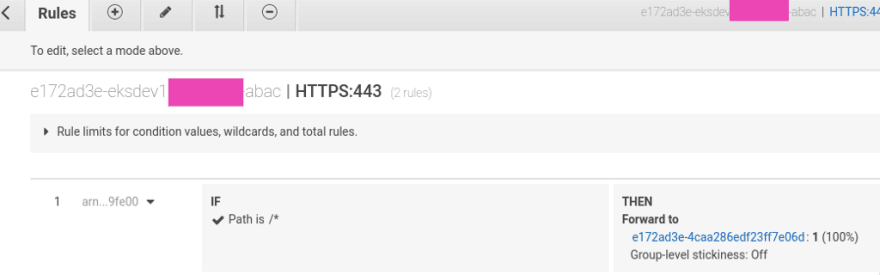
ЕС2 in this TargetGroup are listening to the 31103 port which we saw in the Service details above:

AWS LoadBalancer traffic modes
A side note: AWS ALB supports two modes for traffic — IP, and Instance Mode.
- Instance mode : the default mode, requires a Kubernetes Service to have the NodePort type, and routes traffic to a TCP port of a WorkerNode
- IP mode : with this mode targets for an ALB are Kubernetes Pods directly instead of the Kubernetes Worker Nodes.
Now, we need to have an access to one of these nodes — connect to a Bastion host, and then to one of the WorkerNode:
ubuntu@ip-10–3–29–14:~$ ssh ec2-user@10.3.49.200 -i .ssh/bttrm-eks-nodegroup-us-east-2.pem
Last login: Thu May 28 06:25:27 2020 from ip-10–3–29–32.us-east-2.compute.internal
__|__ |_ )
_| ( / Amazon Linux 2 AMI
___|\___ |___|
39 package(s) needed for security, out of 64 available
Run “sudo yum update” to apply all updates.
[ec2-user@ip-10–3–49–200 ~]$ sudo -s
[root@ip-10–3–49–200 ec2-user]#
kube-proxy and iptables
So, a packet from a client came to the WorkerNode.
On this node, the kube-proxy service is binding on the port allocated so no one another service will use it, and also it creates a set of iptables rules:
[root@ip-10–3–49–200 ec2-user]# netstat -anp | grep 31103
tcp6 0 0 :::31103 :::* LISTEN 4287/kube-proxy
The packet comes to the 31107 port, where it’s started following by the iptables filters.
iptables rules
Links:
- Traversing of tables and chains
- Packet flow in Netfilter and General Networking
- A Deep Dive into Iptables and Netfilter Architecture
{kind=link}
The Linux kernel accepts this packet and sends it to the PREROUTING chain of the nat table:

See the describing kube-proxy iptables rules.
Check rules in the nat table and its PREROUTING chain:
[root@ip-10–3–49–200 ec2-user]# iptables -t nat -L PREROUTING | column -t
Chain PREROUTING (policy ACCEPT)
target prot opt source destination
KUBE-SERVICES all — anywhere anywhere /* kubernetes service portals */
Here we have a target to the following chain - the KUBE-SERVICES, which have the next chain - KUBE-NODEPORTS as the last rule, which captures packets for a Service with the NodePort type:
[root@ip-10–3–49–200 ec2-user]# iptables -t nat -L KUBE-SERVICES -n | column -t
…
KUBE-NODEPORTS all — 0.0.0.0/0 0.0.0.0/0 /* kubernetes service nodeports; NOTE: this must be the last rule in th
is chain */ ADDRTYPE match dst-type LOCAL
…
Check rules in this chain:
[root@ip-10–3–49–200 ec2-user]# iptables -t nat -L KUBE-NODEPORTS -n | column -t | grep 31103
KUBE-MARK-MASQ tcp — 0.0.0.0/0 0.0.0.0/0 /* eks-dev-1-appname-ns/appnamed-backend-svc: */ tcp dpt:31103
KUBE-SVC-TII5GQPKXWC65SRC tcp — 0.0.0.0/0 0.0.0.0/0 /* eks-dev-1-appname-ns/appname-backend-svc: */ tcp dpt:31103
And here it is intercepting packets for the dpt:31103 (destination port 31103) and they are sent to the next chain - KUBE-SVC-TII5GQPKXWC65SRC, check it now:
[root@ip-10–3–49–200 ec2-user]# iptables -t nat -L KUBE-SVC-TII5GQPKXWC65SRC | column -t
Chain KUBE-SVC-TII5GQPKXWC65SRC (2 references)
target prot opt source destination
KUBE-SEP-N36I6W2ULZA2XU52 all — anywhere anywhere statistic mode random probability 0.50000000000
KUBE-SEP-4NFMB5GS6KDP7RHJ all — anywhere anywhere
Here we can see the next two chains where is the “routing magic” happens — the packet randomly will be sent to one of these chains, each has 0.5 from 1.0 “weight” — statistic mode random probability 0.5, as per the official Kubernetes documentation:
By default, kube-proxy in iptables mode chooses a backend at random.
See also Turning IPTables into a TCP load balancer for fun and profit.
Check those chains.
The first one:
[root@ip-10–3–49–200 ec2-user]# iptables -t nat -L KUBE-SEP-N36I6W2ULZA2XU52 -n | column -t
Chain KUBE-SEP-N36I6W2ULZA2XU52 (1 references)
target prot opt source destination
KUBE-MARK-MASQ all — 10.3.34.219 0.0.0.0/0
DNAT tcp — 0.0.0.0/0 0.0.0.0/0 tcp to:10.3.34.219:3001
And the second one:
[root@ip-10–3–49–200 ec2-user]# iptables -t nat -L KUBE-SEP-4NFMB5GS6KDP7RHJ -n | column -t
Chain KUBE-SEP-4NFMB5GS6KDP7RHJ (1 references)
target prot opt source destination
KUBE-MARK-MASQ all — 10.3.57.124 0.0.0.0/0
DNAT tcp — 0.0.0.0/0 0.0.0.0/0 tcp to:10.3.57.124:3001
And here we can see that the DNAT (Destination NAT) chain is sending the packet to an IP and 3001 port, which is actually our ContainerPort - check the Deployment:
$ kubectl -n eks-dev-1-appname-ns get deploy appname-backend -o json | jq ‘.spec.template.spec.containers[].ports[].containerPort’
3001
And go to see our pods IPs.
Find the pods:
$ kubectl -n eks-dev-1-appname-ns get pod
NAME READY STATUS RESTARTS AGE
appname-backend-768ddf9f54–2nrp5 1/1 Running 0 3d
appname-backend-768ddf9f54-pm9bh 1/1 Running 0 3d
And IP of the first pod:
$ kubectl -n eks-dev-1-appname-ns get pod appname-backend-768ddf9f54–2nrp5 — template={{.status.podIP}}
10.3.34.219
And the second one:
$ kubectl -n eks-dev-1-appname-ns get pod appname-backend-768ddf9f54-pm9bh — template={{.status.podIP}}
10.3.57.124
Isn’t it great? :-) So simple — and so great.
Now, let’s try to scale our Deployment to see how the KUBE-SVC-TII5GQPKXWC65SRC will be changed to reflect the scaling.
Find the Deployment:
$ kubectl -n eks-dev-1-appname-ns get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
appname-backend 2/2 2 2 64d
Scale it from two to three pods:
$ kubectl -n eks-dev-1-appname-ns scale deploy appname-backend — replicas=3
deployment.extensions/appname-backend scaled
Check the iptables rules:
[root@ip-10–3–49–200 ec2-user]# iptables -t nat -L KUBE-SVC-TII5GQPKXWC65SRC | column -t
Chain KUBE-SVC-TII5GQPKXWC65SRC (2 references)
target prot opt source destination
KUBE-SEP-N36I6W2ULZA2XU52 all — anywhere anywhere statistic mode random probability 0.33332999982
KUBE-SEP-HDIQCDRXRXBGRR55 all — anywhere anywhere statistic mode random probability 0.50000000000
KUBE-SEP-4NFMB5GS6KDP7RHJ all — anywhere anywhere
Now we can see that our KUBE-SVC-TII5GQPKXWC65SRC got three rules: the first one with the 0.33332999982 random, as there are two more rules after, then the second one with the 0.5 weight, and the last one - without rules at all.
Check the iptables statistics module.
Actually, “That’s all folks!” ©
Useful links
- Kubernetes: ClusterIP vs NodePort vs LoadBalancer, Services и Ingress — обзор, примеры
- Kubernetes Networking Demystified: A Brief Guide
- A Deep Dive into Iptables and Netfilter Architecture
- Traversing of tables and chains
- Turning IPTables into a TCP load balancer for fun and profit
- Cracking kubernetes node proxy (aka kube-proxy)
- A minimal IPVS Load Balancer demo
- How to enable IPVS mode on AWS EKS?
- Load-Balancing in Kubernetes
Originally published at RTFM: Linux, DevOps and system administration.
Posted on November 1, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.