The Ultimate Guide To Scraping LinkedIn Jobs

Serpdog
Posted on March 25, 2023

The Ultimate Guide To Scraping LinkedIn Jobs
LinkedIn has an abundance of valuable data which can fetch a high price when sold in the market. It is also one of the most popular platforms for job seekers, connecting them with various potential employers around the world.
You can use LinkedIn Jobs to get job vacancies from anywhere in the world. However, scrolling through tons of listings can prove to be a time-consuming task. What if you need a large amount of data, but discover that LinkedIn doesn’t offer an API for it?

In this tutorial, we will use the power of web scraping to scrape data from LinkedIn Jobs postings with the help of Node JS.
Scraping LinkedIn Jobs Listings
Requirements
Before installing the required libraries for this tutorial, I assume that you have already set up your Node JS project on your respective device.
Now, let us install these libraries:
Unirest— For fetching the raw HTML data from the host website.
Cheerio— For parsing the HTML to get the required filtered data.
Or you can directly install them by running this code in your project terminal:
npm i unirest
npm i cheerio
Understanding the LinkedIn Jobs Search Page
Before beginning the scraping process, let us understand how the LinkedIn Jobs search page works. Open LinkedIn in your web browser and sign out from the website (if you had an account on LinkedIn). You will be redirected to a page that looks like this:

Click the Jobs button, which has a bag icon, located at the top right corner, and you will be redirected to the LinkedIn Jobs search page.
Search for JavaScript jobs in Salt Lake City, Utah, United States.

Okay 😃, we got a couple of job listings here. And if you go down by scrolling to the bottom, you will find out that LinkedIn uses infinite scrolling for loading job listings.
So, these job listings can be scraped easily using a headless browser that can infinitely scroll the browser controlled by Puppeteer JS or any other JS rendering library. But then, I should have asked you to install Puppeteer JS in the above section. Right🧐?
The answer is yes, we can use Puppeteer JS to scrape the job listings at a large scale, but it comes with lots of disadvantages. It is not only highly time-consuming but also increases your scraping cost to a great extent when you do the large-scale scraping.
So, what can be the solution to this problem🤔? Let us come to the point where we have started. Refresh the page, and scroll to the top. Copy the browser tab URL.
Let us decode this URL:
keywords— Javascriptlocation— Salt Lake City, Utah, United Statestrk— public_jobs_jobs-search-bar_search-submitposition— 1pageNum— 0geoId— 103250458
Now, open the developer tools in your browser to see if any activity is happening in the network tab. Scroll down to the bottom of the page until more job posts load. You will find a search URL in the network tab that LinkedIn uses to fetch more data.
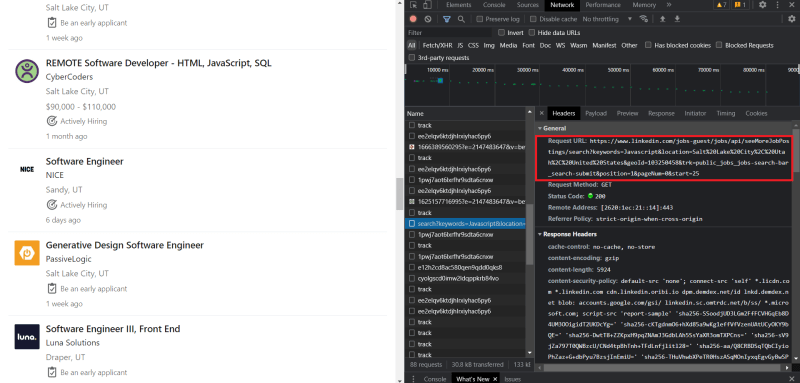
Copy this URL, and open it in your browser.

So, we found a solution!! Every time you scroll to the bottom of the page, LinkedIn sends a request to the search URL to get more data to load the job listings.
Let us compare both the URLs:
The second URL looks the same as the first, but there is a slight difference. We can see a start parameter in the above URL equal to 25. If you scroll to the end of the second page, you will notice that the value of start will increase by 25 and become 50 for the third page. Therefore, the value of start will increase by 25 for every new page.
And one thing you will notice if you increase the value of start by 1, it will hide the previous job listing.
Let us check if passing 0 as the value of start will return us with the first page results.

And yes, it does. The job posts are alike on both pages.
Therefore, we can scrape all the job listings even faster than using a headless browser.
Scraping LinkedIn Jobs
Let us import the libraries we have installed above:
const unirest = require("unirest")
const cheerio = require("cheerio")
So, we have 415 jobs listed for JavaScript in Salt Lake City.

This is how we will scrape all the job listings:
We will divide 415 by 25 to get the number of pages we want to scrape, as each page consists of 25 job listings.
Next, we will run a loop for each page to extract the job posts listed on them.
We will now make a function in which we will design our scraper.
const getData = async() => {
try{
let range = Math.ceil(415/25)
let pageNum = 0;
for (let i = 0; i < range; i++) {
let url = `https://www.linkedin.com/jobs-guest/jobs/api/seeMoreJobPostings/search?keywords=Javascript&location=Salt%2BLake%2BCity%2C%2BUtah%2C%2BUnited%2BStates&geoId=103250458&trk=public_jobs_jobs-search-bar_search-submit&start=${pageNum}`
pageNum+=25;
let response = await unirest.get(url).headers({"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36"})
const $ = cheerio.load(response.body)
Step-by-step explanation:
First, we divided 415 by 25 and used
math.ceil()over it, in case the value is a float number.Then we set the
pageNumvariable to 0.After that, we declared a loop to run for the specified range, to extract all the job listings.
In the next line, we set our target URL from which we have to extract data and increased the value of
pageNumby 25 so that the next time the loop runs for i+1, we can extract the next page’s results.Then, we made an HTTP request on the target URL by passing the User Agent as the header, which will help our bot mimic an organic user.
Finally, we loaded the extracted HTML into a Cheerio instance variable.
Now, let’s search for the tags inside the DOM to parse the HTML.
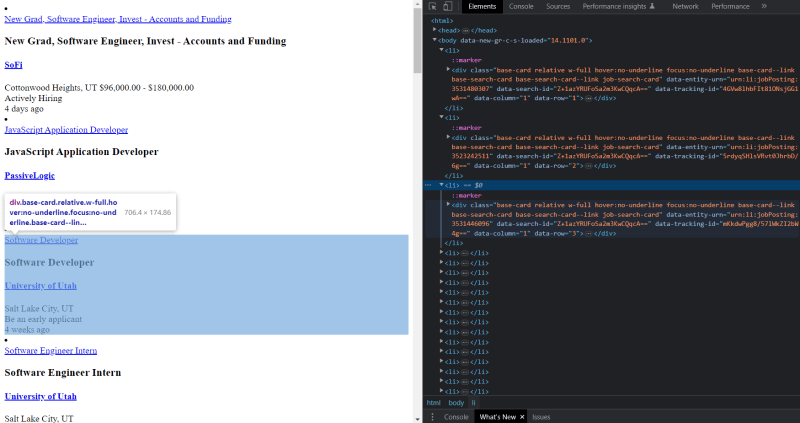
You can see in the above image all the job posts are present inside the container div.job-search-card.
And now, we will search for tags of the elements we want to scrape inside this container.
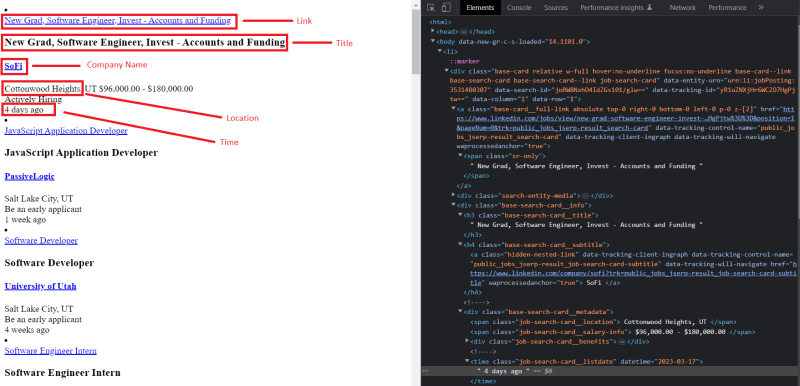
As you can see in the above image, the tag for the title is h3.base-search-card__title, the tag for the link is a.base-card__full-link, the tag for the location is span.job-search-card__location and the tag for the date is time.job-search-card__listdate.
We can also fetch the company name which has the tag h4.base-search-card__subtitle.
If you want to scrape the complete details about a job, you also need to extract the job ID from the HTML.

After searching all the tags, our parser should look like this:
$(".job-search-card").each((i,el) => {
jobs_data.push({
title: $(el).find(".base-search-card__title").text()?.trim(),
company: $(el).find("h4.base-search-card__subtitle").text()?.trim(),
link: $(el).find("a.base-card__full-link").attr("href")?.trim(),
location: $(el).find(".job-search-card__location").text()?.trim(),
id: $(el).attr("data-entity-urn")?.split("urn:li:jobPosting:")[1],
date: $(el).find(".job-search-card__listdate").text()?.trim()
})
})
Save your data in a CSV file
Logging the data in the console can create a mess. Instead, we will use the Object-to-CSV library to store the data in a CSV file.
You can install this library by running this command:
npm i objects-to-csv
Import this into your project file.
const ObjectsToCsv = require('objects-to-csv');
And now, use this library to push the data in the jobs_data array into the CSV file.
const csv = new ObjectsToCsv(jobs_data)
csv.toDisk('./linkedInJobs.csv', { append: true })
The append: true is passed to the toDisk method to ensure that the new data is appended to the file.
Now, run this program in your terminal, and you will get a CSV file named linkedInJobs.csv in your root project folder.

Complete Code
Here is the complete code.
const unirest = require("unirest")
const ObjectsToCsv = require('objects-to-csv');
const cheerio = require("cheerio")
const getData = async() => {
try{
let range = Math.ceil(415/25)
let pageNum = 0;
for (let i = 0; i < range; i++) {
let url = `https://www.linkedin.com/jobs-guest/jobs/api/seeMoreJobPostings/search?keywords=Javascript&location=Salt%2BLake%2BCity%2C%2BUtah%2C%2BUnited%2BStates&geoId=103250458&trk=public_jobs_jobs-search-bar_search-submit&start=${pageNum}`
pageNum+=25;
let response = await unirest.get(url).headers({"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36"})
const $ = cheerio.load(response.body)
let jobs_data = []
$(".job-search-card").each((i,el) => {
jobs_data.push({
title: $(el).find(".base-search-card__title").text()?.trim(),
company: $(el).find("h4.base-search-card__subtitle").text()?.trim(),
link: $(el).find("a.base-card__full-link").attr("href")?.trim(),
location: $(el).find(".job-search-card__location").text()?.trim(),
date: $(el).find(".job-search-card__listdate").text()?.trim(),
})
})
const csv = new ObjectsToCsv(jobs_data)
csv.toDisk('./linkedInJobs2.csv', { append: true })
}
}
catch(e)
{
console.log(e)
}
}
getData()
Scraping Job Details
We can scrape the job details using the same method we used to scrape job postings.

Open the dev tools in your browser. Click on any job postings on the left side of the web page. You will notice a GET request by the LinkedIn in network tab to get more data about the job.

This URL consists of unnecessary parameters. Let’s first remove them:
https://www.linkedin.com/jobs-guest/jobs/api/jobPosting/3523242511
Open this URL in your browser. You will see the complete detail about the job with the id 3523242511.

Let us scrape some information from this page. Then we will embed this in our previous code to get the combined data.
We will extract the job level and the employment type from this page.

The job level can be found inside the tag li.description__job-criteria-item:nth-child(1) span, and the employment type can be found inside the tag li.description__job-criteria-item:nth-child(2) span.
Embed this in the previous code:
const unirest = require("unirest")
const ObjectsToCsv = require('objects-to-csv');
const cheerio = require("cheerio")
const getData = async() => {
try{
let range = Math.ceil(415/25)
let pageNum = 0;
let jobs_data = [];
for (let i = 0; i < range; i++) {
console.log(i)
let url = `https://www.linkedin.com/jobs-guest/jobs/api/seeMoreJobPostings/search?keywords=Javascript&location=Salt%2BLake%2BCity%2C%2BUtah%2C%2BUnited%2BStates&geoId=103250458&trk=public_jobs_jobs-search-bar_search-submit&start=${pageNum}`
let response = await unirest.get(url).headers({"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36"})
const $ = cheerio.load(response.body)
$(".job-search-card").each(async(i,el) => {
jobs_data.push({
title: $(el).find(".base-search-card__title").text()?.trim(),
company: $(el).find("h4.base-search-card__subtitle").text()?.trim(),
link: $(el).find("a.base-card__full-link").attr("href")?.trim(),
id: $(el).attr("data-entity-urn")?.split("urn:li:jobPosting:")[1],
location: $(el).find(".job-search-card__location").text()?.trim(),
date: $(el).find(".job-search-card__listdate").text()?.trim(),
})
})
}
for (let j = 0; j < jobs_data.length; j++) {
let url2 = `https://www.linkedin.com/jobs-guest/jobs/api/jobPosting/${jobs_data[j].id}`
let response2 = await unirest.get(url2).headers({"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36"})
const $2 = cheerio.load(response2.body)
let level = $2("li.description__job-criteria-item:nth-child(1) span").text().trim()
let type = $2("li.description__job-criteria-item:nth-child(2) span").text().trim()
jobs_data[j].level = level;
jobs_data[j].type = type;
}
const csv = new ObjectsToCsv(jobs_data)
csv.toDisk('./linkedInJobs2.csv', { append: true })
pageNum+=25;
}
catch(e)
{
console.log(e)
}
}
getData()
After running this code in your terminal, you will be able to get the combined data. Additionally, if you want to scrape more information from the URLs, you can easily do so using the basics you have learned above.
Why scrape LinkedIn data?
LinkedIn has a massive base of more than 756 million users worldwide. It makes no wonder why developers want to scrape LinkedIn as it consists of a vast amount of information about its users, registered companies, and their employees.
Let us discuss how businesses can benefit from scraping LinkedIn data:

Lead Generation — One of the most significant benefits of LinkedIn scraping is lead generation. It helps developers to gather contact details such as email and phone numbers from the profiles of their potential customers.
Market Research — LinkedIn data can also be used to gain information about current market trends in the industry. It can be used to identify potential gaps in the industry that can be leveraged to develop a product to sell to the target audience.
Make Targeted Campaigns — LinkedIn data can be used to distribute audiences in various categories according to their job titles, industry, location, etc. This information can be utilized to target a specific category of professionals on LinkedIn who can be potential customers for your product.
Recruitment — If you are an employer searching for professionals on LinkedIn who can be perfect and qualified for the position open in your company, then you can scrape LinkedIn data to target such professionals and reach out to them.
Conclusion
In this tutorial, we learned to scrape LinkedIn Jobs without using any scroll and click but with a simple GET request using Node JS. We also learned why developers scrape LinkedIn data for making targeted campaigns, lead generation, and doing market research.
I hope this tutorial provided you with a complete overview of scraping LinkedIn job postings. Please do not hesitate to message me if I missed something. If you think we can complete your custom scraping projects, feel free to contact us. Follow me on Twitter. Thanks for reading!
Additional Resources
Here are some blogs from our portfolio which can help you to kickstart your web scraping journey:
Posted on March 25, 2023
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related
November 6, 2024