Web scraping Google Shopping Product Reviews with Nodejs

Mikhail Zub
Posted on November 23, 2022

What will be scraped
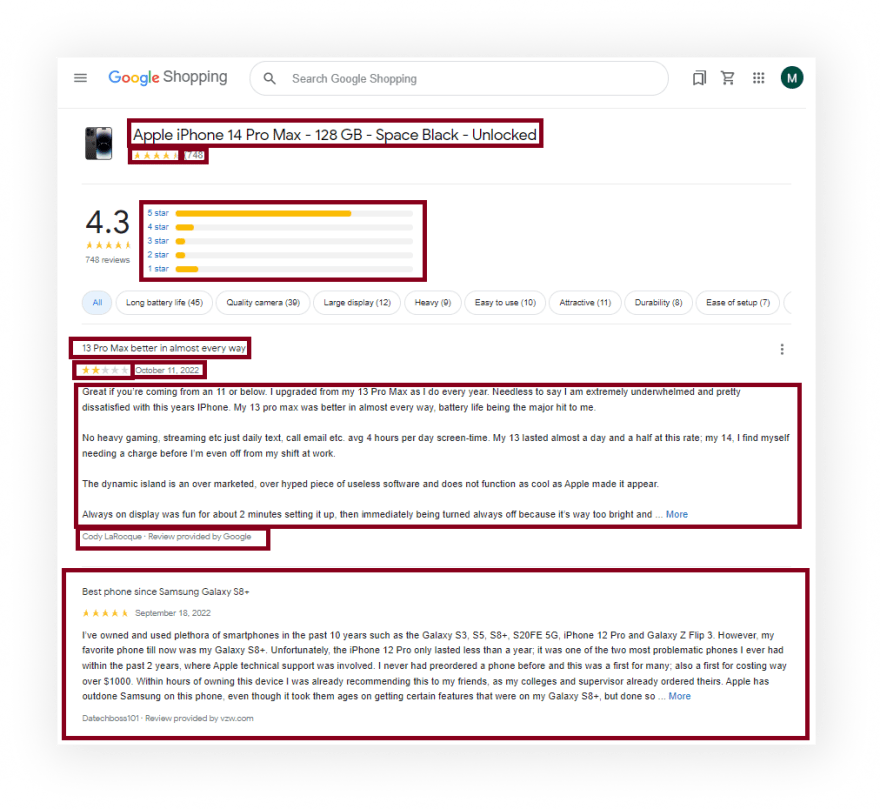
Full code
If you don't need an explanation, have a look at the full code example in the online IDE
const puppeteer = require("puppeteer-extra");
const StealthPlugin = require("puppeteer-extra-plugin-stealth");
puppeteer.use(StealthPlugin());
const reviewsLimit = 100; // hardcoded limit for demonstration purpose
const searchParams = {
id: "8757849604759505625", // Parameter defines the ID of a product you want to get the results for
hl: "en", // Parameter defines the language to use for the Google search
gl: "us", // parameter defines the country to use for the Google search
};
const URL = `https://www.google.com/shopping/product/${searchParams.id}/reviews?hl=${searchParams.hl}&gl=${searchParams.gl}`;
async function getReviews(page) {
while (true) {
await page.waitForSelector("#sh-fp__pagination-button-wrapper");
const isNextPage = await page.$("#sh-fp__pagination-button-wrapper");
const reviews = await page.$$("#sh-rol__reviews-cont > div");
if (!isNextPage || reviews.length > reviewsLimit) break;
await page.click("#sh-fp__pagination-button-wrapper");
await page.waitForTimeout(3000);
}
return await page.evaluate(() => {
return {
productResults: {
title: document.querySelector(".BvQan")?.textContent.trim(),
reviews: parseInt(document.querySelector(".lBRvsb .HiT7Id > span")?.getAttribute("aria-label").replace(",", "")),
rating: parseFloat(document.querySelector(".lBRvsb .UzThIf")?.getAttribute("aria-label")),
},
reviewsResults: {
rating: Array.from(document.querySelectorAll(".aALHge")).map((el) => ({
stars: parseInt(el.querySelector(".rOdmxf")?.textContent),
amount: parseInt(el.querySelector(".vL3wxf")?.textContent),
})),
reviews: Array.from(document.querySelectorAll("#sh-rol__reviews-cont > div")).map((el) => ({
title: el.querySelector(".P3O8Ne")?.textContent.trim() || el.querySelector("._-iO")?.textContent.trim(),
date: el.querySelector(".OP1Nkd .ff3bE.nMkOOb")?.textContent.trim() || el.querySelector("._-iU")?.textContent.trim(),
rating: parseInt(el.querySelector(".UzThIf")?.getAttribute("aria-label") || el.querySelector("._-lq")?.getAttribute("aria-label")),
source: el.querySelector(".sPPcBf")?.textContent.trim() || el.querySelector("._-iP")?.textContent.trim(),
content: el.querySelector(".g1lvWe > div:last-child")?.textContent.trim() || el.querySelector("._-iN > div:last-child")?.textContent.trim(),
})),
},
};
});
}
async function getProductInfo() {
const browser = await puppeteer.launch({
headless: true, // if you want to see what the browser is doing, you need to change this option to "false"
args: ["--no-sandbox", "--disable-setuid-sandbox"],
});
const page = await browser.newPage();
await page.setDefaultNavigationTimeout(60000);
await page.goto(URL);
await page.waitForSelector(".xt8sXe button");
const reviews = { productId: searchParams.id, ...(await getReviews(page)) };
await browser.close();
return reviews;
}
getProductInfo().then((result) => console.dir(result, { depth: null }));
Preparation
First, we need to create a Node.js* project and add npm packages puppeteer, puppeteer-extra and puppeteer-extra-plugin-stealth to control Chromium (or Chrome, or Firefox, but now we work only with Chromium which is used by default) over the DevTools Protocol in headless or non-headless mode.
To do this, in the directory with our project, open the command line and enter:
$ npm init -y
And then:
$ npm i puppeteer puppeteer-extra puppeteer-extra-plugin-stealth
*If you don't have Node.js installed, you can download it from nodejs.org and follow the installation documentation.
📌Note: also, you can use puppeteer without any extensions, but I strongly recommended use it with puppeteer-extra with puppeteer-extra-plugin-stealth to prevent website detection that you are using headless Chromium or that you are using web driver. You can check it on Chrome headless tests website. The screenshot below shows you a difference.

Process
We need to extract data from HTML elements. The process of getting the right CSS selectors is fairly easy via SelectorGadget Chrome extension which able us to grab CSS selectors by clicking on the desired element in the browser. However, it is not always working perfectly, especially when the website is heavily used by JavaScript.
We have a dedicated Web Scraping with CSS Selectors blog post at SerpApi if you want to know a little bit more about them.
The Gif below illustrates the approach of selecting different parts of the results using SelectorGadget.

Code explanation
Declare puppeteer to control Chromium browser from puppeteer-extra library and StealthPlugin to prevent website detection that you are using web driver from puppeteer-extra-plugin-stealth library:
const puppeteer = require("puppeteer-extra");
const StealthPlugin = require("puppeteer-extra-plugin-stealth");
Next, we "say" to puppeteer use StealthPlugin, write the necessary request parameters, search URL and set how many reviews we want to receive (reviewsLimit constant):
puppeteer.use(StealthPlugin());
const reviewsLimit = 100; // hardcoded limit for demonstration purpose
const searchParams = {
id: "8757849604759505625", // Parameter defines the ID of a product you want to get the results for
hl: "en", // Parameter defines the language to use for the Google search
gl: "us", // parameter defines the country to use for the Google search
};
const URL =
`https://www.google.com/shopping/product/${searchParams.id}/reviews?hl=${searchParams.hl}&gl=${searchParams.gl}`;
Next, we write a function to get product info from the page:
async function getReviews(page) {
...
}
Next, we use while loop (while) in which we check if the next page button is available on the page and the number of reviews ($, and $$ methods) is less then reviewsLimit we click (click() method) on the next page button element, wait 3 seconds (using waitForTimeout method), otherwise we stop the loop (using break).
while (true) {
await page.waitForSelector("#sh-fp__pagination-button-wrapper");
const isNextPage = await page.$("#sh-fp__pagination-button-wrapper");
const reviews = await page.$$("#sh-rol__reviews-cont > div");
if (!isNextPage || reviews.length > reviewsLimit) break;
await page.click("#sh-fp__pagination-button-wrapper");
await page.waitForTimeout(3000);
}
Then, we get information from the page context (using evaluate() method) and save it in the returned object:
return await page.evaluate(() => ({
...
}));
Next, we need to get the different parts of the page using next methods:
-
querySelectorAll(); -
querySelector(); -
getAttribute(); -
textContent; -
trim(); -
Array.from(); -
replace(); -
parseInt(); -
parseFloat().
productResults: {
title: document.querySelector(".BvQan")?.textContent.trim(),
reviews: parseInt(document.querySelector(".lBRvsb .HiT7Id > span")
?.getAttribute("aria-label").replace(",", "")),
rating: parseFloat(document.querySelector(".lBRvsb .UzThIf")
?.getAttribute("aria-label")),
},
reviewsResults: {
rating: Array.from(document.querySelectorAll(".aALHge")).map((el) => ({
stars: parseInt(el.querySelector(".rOdmxf")?.textContent),
amount: parseInt(el.querySelector(".vL3wxf")?.textContent),
})),
reviews: Array.from(document.querySelectorAll("#sh-rol__reviews-cont > div")).map((el) => ({
title: el.querySelector(".P3O8Ne")?.textContent.trim() || el.querySelector("._-iO")
?.textContent.trim(),
date:
el.querySelector(".OP1Nkd .ff3bE.nMkOOb")?.textContent.trim() ||
el.querySelector("._-iU")?.textContent.trim(),
rating:
parseInt(el.querySelector(".UzThIf")?.getAttribute("aria-label") ||
el.querySelector("._-lq")?.getAttribute("aria-label")),
source:
el.querySelector(".sPPcBf")?.textContent.trim() ||
el.querySelector("._-iP")?.textContent.trim(),
content:
el.querySelector(".g1lvWe > div:last-child")?.textContent.trim() ||
el.querySelector("._-iN > div:last-child")?.textContent.trim(),
})),
},
Next, write a function to control the browser, and get information:
async function getProductInfo() {
...
}
In this function first we need to define browser using puppeteer.launch({options}) method with current options, such as headless: true and args: ["--no-sandbox", "--disable-setuid-sandbox"].
These options mean that we use headless mode and array with arguments which we use to allow the launch of the browser process in the online IDE. And then we open a new page:
const browser = await puppeteer.launch({
headless: true, // if you want to see what the browser is doing, you need to change this option to "false"
args: ["--no-sandbox", "--disable-setuid-sandbox"],
});
const page = await browser.newPage();
Next, we change default (30 sec) time for waiting for selectors to 60000 ms (1 min) for slow internet connection with .setDefaultNavigationTimeout() method, go to URL with .goto() method and use .waitForSelector() method to wait until the selector is load:
await page.setDefaultNavigationTimeout(60000);
await page.goto(URL);
await page.waitForSelector(".xt8sXe button");
And finally, we save product data from the page in the reviews constant (using spread syntax), close the browser, and return the received data:
const reviews = {
productId: searchParams.id,
...(await getReviews(page))
};
await browser.close();
return reviews;
Now we can launch our parser:
$ node YOUR_FILE_NAME # YOUR_FILE_NAME is the name of your .js file
Output
{
"productId":"8757849604759505625",
"productResults":{
"title":"Apple iPhone 14 Pro Max - 128 GB - Space Black - Unlocked",
"reviews":748,
"rating":4.5
},
"reviewsResults":{
"rating":[
{
"stars":5,
"amount":554
},
{
"stars":4,
"amount":58
},
{
"stars":3,
"amount":31
},
{
"stars":2,
"amount":32
},
{
"stars":1,
"amount":73
}
],
"reviews":[
{
"title":"13 Pro Max better in almost every way",
"date":"October 11, 2022",
"rating":2,
"source":"Cody LaRocque · Review provided by Google",
"content":"Great if you’re coming from an 11 or below. I upgraded from my 13 Pro Max as I do every year. Needless to say I am extremely underwhelmed and pretty dissatisfied with this years IPhone. My 13 pro max was better in almost every way, battery life being the major hit to me. No heavy gaming, streaming etc just daily text, call email etc. avg 4 hours per day screen-time. My 13 lasted almost a day and a half at this rate; my 14, I find myself needing a charge before I’m even off from my shift at work.The dynamic island is an over marketed, over hyped piece of useless software and does not function as cool as Apple made it appear. Always on display was fun for about 2 minutes setting it up, then immediately being turned always off because it’s way too bright and sucks power like you wouldn’t believe.All of apples key selling points are all the keys reasons I dislike this phone. Always on is a nightmare, battery life is a joke, dynamic island is useless, crash detection goes off on roller coasters, the cameras have very very little upside differences, the brightness of the screen only lasts for a couple seconds until it auto dims to conserve energy. I also feel like the overall build quality is lacking, I purchased the phone and the Apple leather case; this being the first time I’ve ever even used a case on my iPhone. My 13 lasted a year being dropped multiple times and didn’t even have a scratch. I dropped my 14 face down on a flat floor with the Apple leather case and it chipped the front corner. If you are coming from the 13. Don’t bother upgrading. If your coming from a 12 or below, consider upgrading to the now discounted 13 Less"
},
... and other reviews
]
}
}
Using Google Product Reviews Results API from SerpApi
This section is to show the comparison between the DIY solution and our solution.
The biggest difference is that you don't need to create the parser from scratch and maintain it.
There's also a chance that the request might be blocked at some point from Google, we handle it on our backend so there's no need to figure out how to do it yourself or figure out which CAPTCHA, proxy provider to use.
First, we need to install google-search-results-nodejs:
npm i google-search-results-nodejs
Here's the full code example, if you don't need an explanation:
require("dotenv").config();
const SerpApi = require("google-search-results-nodejs");
const search = new SerpApi.GoogleSearch(process.env.API_KEY); //your API key from serpapi.com
const reviewsLimit = 100; // hardcoded limit for demonstration purpose
const params = {
product_id: "8757849604759505625", // Parameter defines the ID of a product you want to get the results for.
engine: "google_product", // search engine
device: "desktop", //Parameter defines the device to use to get the results. It can be set to "desktop" (default), "tablet", or "mobile"
hl: "en", // parameter defines the language to use for the Google search
gl: "us", // parameter defines the country to use for the Google search
reviews: true, // parameter for fetching reviews results
};
const getJson = () => {
return new Promise((resolve) => {
search.json(params, resolve);
});
};
const getResults = async () => {
const json = await getJson();
const results = {};
results.productResults = json.product_results;
results.reviewsResult = [];
while (true) {
const json = await getJson();
if (json.reviews_results?.reviews) {
results.reviewsResult.push(...json.reviews_results.reviews);
params.start ? (params.start += 10) : (params.start = 10);
} else break;
if (results.reviewsResult.length > reviewsLimit) break;
}
return results;
};
getResults().then((result) => console.dir(result, { depth: null }));
Code explanation
First, we need to declare SerpApi from google-search-results-nodejs library and define new search instance with your API key from SerpApi:
const SerpApi = require("google-search-results-nodejs");
const search = new SerpApi.GoogleSearch(API_KEY);
Next, we write the necessary parameters for making a request and set how many reviews we want to receive (reviewsLimit constant)::
const reviewsLimit = 100; // hardcoded limit for demonstration purpose
const params = {
product_id: "8757849604759505625", // Parameter defines the ID of a product you want to get the results for.
engine: "google_product", // search engine
device: "desktop", //Parameter defines the device to use to get the results. It can be set to "desktop" (default), "tablet", or "mobile"
hl: "en", // parameter defines the language to use for the Google search
gl: "us", // parameter defines the country to use for the Google search
reviews: true, // parameter for fetching reviews results
};
Next, we wrap the search method from the SerpApi library in a promise to further work with the search results:
const getJson = () => {
return new Promise((resolve) => {
search.json(params, resolve);
});
};
And finally, we declare the function getResult that gets data from the page and return it:
const getResults = async () => {
...
};
In this function we get json with results, add product_results data to the productResults key of the results object and return it:
const json = await getJson();
const results = {};
results.productResults = json.product_results;
...
return results;
Next, we need to add an empty reviewsResult array to the results object and using while loop (while) get json, add reviews results from each page and set next page start index (to params.start value). If there is no more reviews results on the page or if the number of received reviews more than reviewsLimit we stop the loop (using break):
results.reviewsResult = [];
while (true) {
const json = await getJson();
if (json.reviews_results?.reviews) {
results.reviewsResult.push(...json.reviews_results.reviews);
params.start ? (params.start += 10) : (params.start = 10);
} else break;
if (results.reviewsResult.length > reviewsLimit) break;
}
After, we run the getResults function and print all the received information in the console with the console.dir method, which allows you to use an object with the necessary parameters to change default output options:
getResults().then((result) => console.dir(result, { depth: null }));
Output
{
"productResults":{
"product_id":8757849604759506000,
"title":"Apple iPhone 14 Pro Max - 128 GB - Space Black - Unlocked",
"reviews":748,
"rating":4.3
},
"reviewsResult":[
{
"position":1,
"title":"13 Pro Max better in almost every way",
"date":"October 11, 2022",
"rating":2,
"source":"Cody LaRocque · Review provided by Google",
"content":"Great if you’re coming from an 11 or below. I upgraded from my 13 Pro Max as I do every year. Needless to say I am extremely underwhelmed and pretty dissatisfied with this years IPhone. My 13 pro max was better in almost every way, battery life being the major hit to me. \n""+""\n""+""No heavy gaming, streaming etc just daily text, call email etc. avg 4 hours per day screen-time. My 13 lasted almost a day and a half at this rate; my 14, I find myself needing a charge before I’m even off from my shift at work.\n""+""\n""+""The dynamic island is an over marketed, over hyped piece of useless software and does not function as cool as Apple made it appear. \n""+""\n""+""Always on display was fun for about 2 minutes setting it up, then immediately being turned always off because it’s way too bright and sucks power like you wouldn’t believe.\n""+""\n""+""All of apples key selling points are all the keys reasons I dislike this phone. Always on is a nightmare, battery life is a joke, dynamic island is useless, crash detection goes off on roller coasters, the cameras have very very little upside differences, the brightness of the screen only lasts for a couple seconds until it auto dims to conserve energy. \n""+""\n""+""I also feel like the overall build quality is lacking, I purchased the phone and the Apple leather case; this being the first time I’ve ever even used a case on my iPhone. My 13 lasted a year being dropped multiple times and didn’t even have a scratch. I dropped my 14 face down on a flat floor with the Apple leather case and it chipped the front corner. \n""+""\n""+""If you are coming from the 13. Don’t bother upgrading. If your coming from a 12 or below, consider upgrading to the now discounted 13 "
},
... and other reviews
]
}
Links
If you want other functionality added to this blog post or if you want to see some projects made with SerpApi, write me a message.
Add a Feature Request💫 or a Bug🐞
Posted on November 23, 2022
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.