Scrape Google Product Reviews Results with Python

Artur Chukhrai
Posted on December 28, 2022
- What will be scraped
- Full Code
- Preparation
- Code Explanation
- Using Google Reviews Results API from SerpApi
- Links
What will be scraped
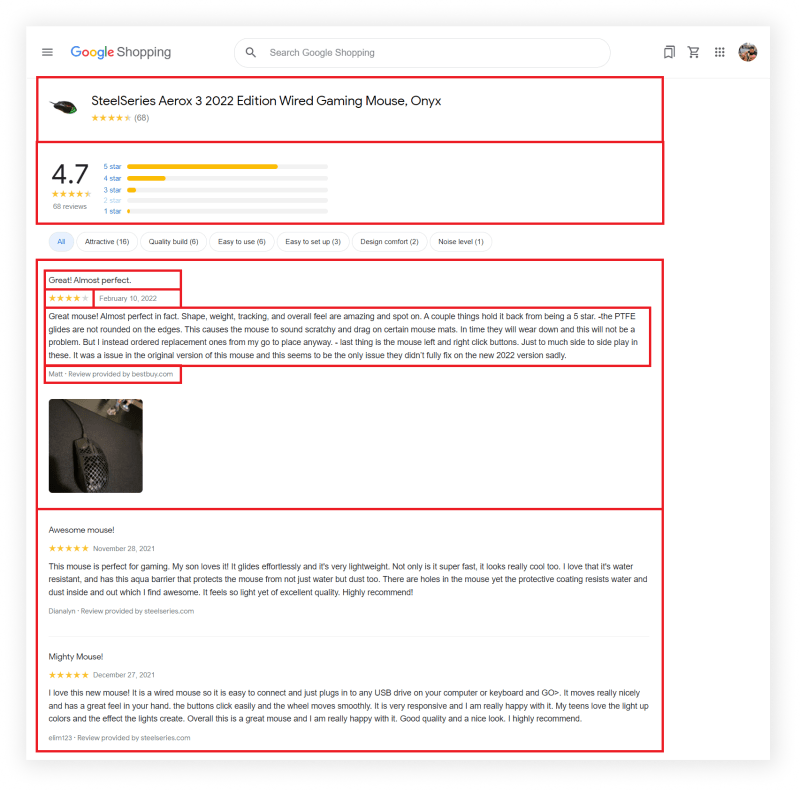
📌Note: In the DIY solution, I only scrape all reviews. If you also want to extract the product title, number of comments, average rating, and others from this page, you can check out the Scrape Google Product Page with Python blog where I described how to extract this data.
Full Code
If you don't need explanation, have a look at full code example in the online IDE.
import requests, json
from parsel import Selector
def get_reviews_results(url, headers):
data = []
while True:
html = requests.get(url, headers=headers)
selector = Selector(html.text)
for review in selector.css('.fade-in-animate'):
title = review.css('.P3O8Ne::text').get()
date = review.css('.ff3bE::text').get()
rating = int(review.css('.UzThIf::attr(aria-label)').get()[0])
content = review.css('.g1lvWe div::text').get()
source = review.css('.sPPcBf').xpath('normalize-space()').get()
data.append({
'title': title,
'date': date,
'rating': rating,
'content': content,
'source': source
})
next_page_selector = selector.css('.sh-fp__pagination-button::attr(data-url)').get()
if next_page_selector:
# re-assigns requests.get url to a new page url
url = 'https://www.google.com' + selector.css('.sh-fp__pagination-button::attr(data-url)').get()
else:
break
return data
def main():
# https://docs.python-requests.org/en/master/user/quickstart/#custom-headers
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
URL = 'https://www.google.com/shopping/product/14019378181107046593/reviews?hl=en&gl=us'
reviews_results = get_reviews_results(URL, headers)
print(json.dumps(reviews_results, indent=2, ensure_ascii=False))
if __name__ == "__main__":
main()
Preparation
Install libraries:
pip install requests parsel
Reduce the chance of being blocked
Make sure you're using request headers user-agent to act as a "real" user visit. Because default requests user-agent is python-requests and websites understand that it's most likely a script that sends a request. Check what's your user-agent.
There's a how to reduce the chance of being blocked while web scraping blog post that can get you familiar with basic and more advanced approaches.
Code Explanation
Import libraries:
import requests, json
from parsel import Selector
| Library | Purpose |
|---|---|
requests |
to make a request to the website. |
json |
to convert extracted data to a JSON object. |
Selector |
XML/HTML parser that have full XPath and CSS selectors support. |
At the beginning of the main() function, the headers and URL are defined. This data is then passed to the get_reviews_results(URL, headers) function to form a request and extract information.
The reviews_results dictionary contains the received data that this function returns. At the end of the function, the data is output in JSON format:
def main():
# https://docs.python-requests.org/en/master/user/quickstart/#custom-headers
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
URL = 'https://www.google.com/shopping/product/14019378181107046593/reviews?hl=en&gl=us'
reviews_results = get_reviews_results(URL, headers)
print(json.dumps(reviews_results, indent=2, ensure_ascii=False))
This code uses the generally accepted rule of using the __name__ == "__main__" construct:
if __name__ == "__main__":
main()
This check will only be performed if the user has run this file. If the user imports this file into another, then the check will not work. You can watch the video Python Tutorial: if name == 'main' for more details.
Let's take a look at the get_reviews_results(url, headers) function mentioned earlier. This function takes url and headers parameters to create a request. Now we need to parse the HTML from the Parsel package, into which we pass the HTML structure that was received after the request.
def get_reviews_results(url, headers):
data = []
while True:
html = requests.get(url, headers=headers)
selector = Selector(html.text)
# data extraction will be here
In order to extract the data, you first need to find the .fade-in-animate selector and iterate over it. Data like title, date and content are pretty easy to retrieve. You need to find the selector and get the value:
for review in selector.css('.fade-in-animate'):
title = review.css('.P3O8Ne::text').get()
date = review.css('.ff3bE::text').get()
content = review.css('.g1lvWe div::text').get()
| Code | Explanation |
|---|---|
css() |
to access elements by the passed selector. |
::text or ::attr(<attribute>) |
to extract textual or attribute data from the node. |
get() |
to actually extract the textual data. |
Extracting source differs from the previous ones in that you need to extract the text not only from this selector, but also from those nested in it:
source = review.css('.sPPcBf').xpath('normalize-space()').get()
Data such as rating must be converted to the numeric data type. I want to draw your attention to the fact that "reviews" are extracted in this format: 4 out of 5 stars. To convert a string to a number, you need to extract only the first character:
rating = int(review.css('.UzThIf::attr(aria-label)').get()[0])
After extracting all the data, the data dictionary is formed:
data.append({
'title': title,
'date': date,
'rating': rating,
'content': content,
'source': source
})
Up to 10 reviews can be displayed on one page. To retrieve all reviews, you need to access the More reviews button selector, extract the link from there, create a request, and extract the data. You need to repeat this action as long as this button is present:
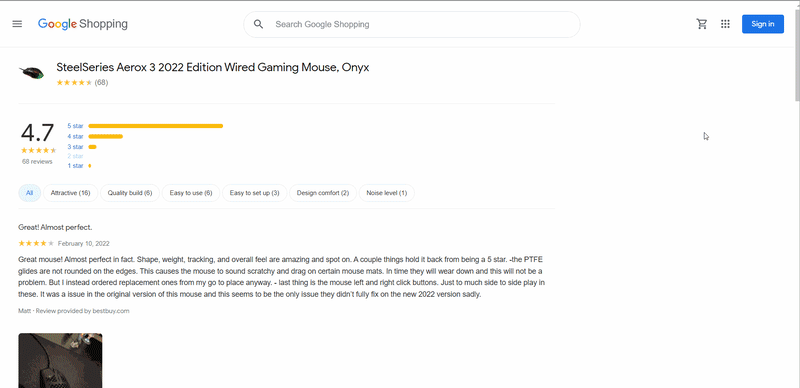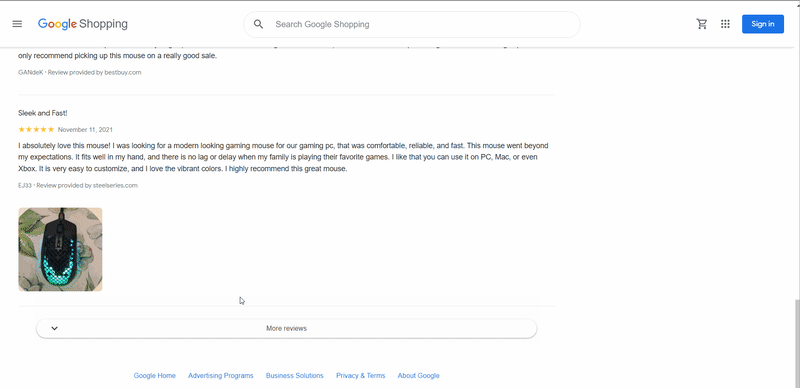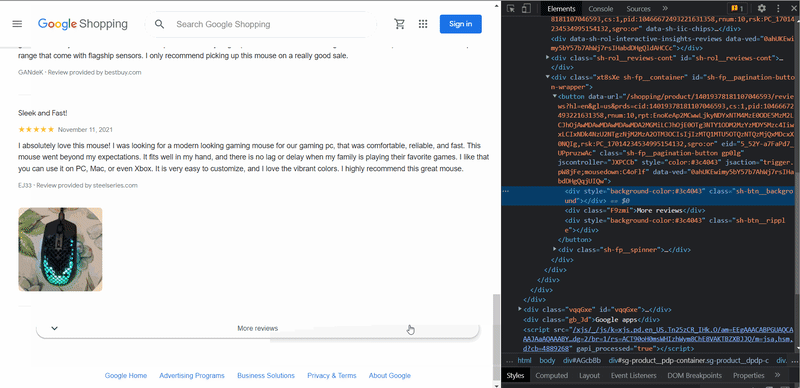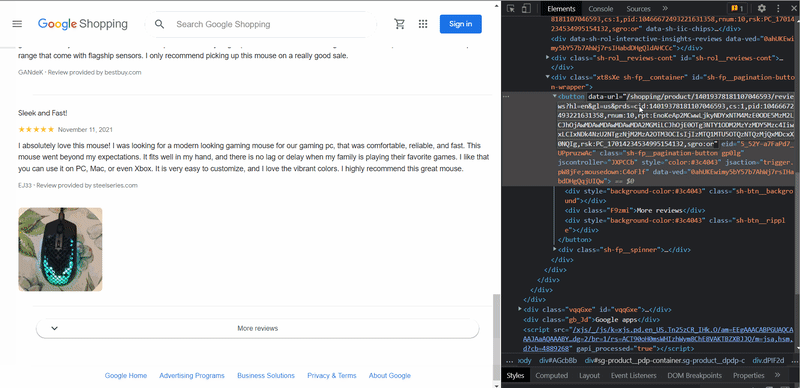
next_page_selector = selector.css('.sh-fp__pagination-button::attr(data-url)').get()
if next_page_selector:
# re-assigns requests.get url to a new page url
url = 'https://www.google.com' + selector.css('.sh-fp__pagination-button::attr(data-url)').get()
else:
break
At the end of the function, the data dictionary is returned.
return data
Output:
[
{
"title": "Great! Almost perfect.",
"date": "February 10, 2022",
"rating": 4,
"content": "Great mouse! Almost perfect in fact. Shape, weight, tracking, and overall feel are amazing and spot on. A couple things hold it back from being a 5 star. -the PTFE glides are not rounded on the edges. This causes the mouse to sound scratchy and drag on certain mouse mats. In time they will wear down and this will not be a problem. But I instead ordered replacement ones from my go to place anyway. - last thing is the mouse left and right click buttons. Just to much side to side play in these. It was a issue in the original version of this mouse and this seems to be the only issue they didn’t fully fix on the new 2022 version sadly. ",
"source": "Matt · Review provided by bestbuy.com"
},
... other reviews
{
"title": "Mouse",
"date": "July 3, 2022",
"rating": 5,
"content": "amazing mouse never seen one better and really help ",
"source": "Sam2682 · Review provided by bestbuy.com"
}
]
Using Google Reviews Results API from SerpApi
This section is to show the comparison between the DIY solution and our solution.
The main difference is that it's a quicker approach. Google Reviews Results API will bypass blocks from search engines and you don't have to create the parser from scratch and maintain it.
First, we need to install google-search-results:
pip install google-search-results
Import the necessary libraries for work:
from serpapi import GoogleSearch
from urllib.parse import urlsplit, parse_qsl
import os, json
Next, we write a search query and the necessary parameters for making a request:
params = {
# https://docs.python.org/3/library/os.html#os.getenv
'api_key': os.getenv('API_KEY'), # your serpapi api
'engine': 'google_product', # SerpApi search engine
'product_id': '14019378181107046593', # product id
'reviews': True, # more reviews, could be also set as '1` which is the same as True
'hl': 'en', # language
'gl': 'us' # country of the search, US -> USA
}
We then create a search object where the data is retrieved from the SerpApi backend. In the results dictionary we get data from JSON:
search = GoogleSearch(params) # where data extraction happens on the SerpApi backend
results = search.get_dict() # JSON -> Python dict
In addition to all reviews, this API also allows you to extract product data and the number of reviews for each rating:
reviews_results = {
'product': results['product_results'],
'ratings': results['reviews_results']['ratings'],
'reviews': results['reviews_results']['reviews']
}
Using pagination, you can get all the reviews and extend the existing list, which is located by the review_results['reviews'] key:
while True:
if "next" in results.get("serpapi_pagination", {}):
search.params_dict.update(dict(parse_qsl(urlsplit(results.get("serpapi_pagination", {}).get("next")).query)))
else:
break
results = search.get_dict() # new page results
reviews_results['reviews'].extend(results['reviews_results']['reviews'])
📌Note: To understand how pagination works, you can watch the How to use SerpApi pagination across all APIs video.
Example code to integrate:
from serpapi import GoogleSearch
from urllib.parse import urlsplit, parse_qsl
import os, json
params = {
# https://docs.python.org/3/library/os.html#os.getenv
'api_key': os.getenv('API_KEY'), # your serpapi api
'engine': 'google_product', # SerpApi search engine
'product_id': '14019378181107046593', # product id
'reviews': True, # more reviews, could be also set as '1` which is the same as True
'hl': 'en', # language
'gl': 'us' # country of the search, US -> USA
}
search = GoogleSearch(params) # where data extraction happens on the backend
results = search.get_dict() # JSON -> Python dict
reviews_results = {
'product': results['product_results'],
'ratings': results['reviews_results']['ratings'],
'reviews': results['reviews_results']['reviews']
}
while True:
if "next" in results.get("serpapi_pagination", {}):
search.params_dict.update(dict(parse_qsl(urlsplit(results.get("serpapi_pagination", {}).get("next")).query)))
else:
break
results = search.get_dict() # new_page_results
reviews_results['reviews'].extend(results['reviews_results']['reviews'])
print(json.dumps(reviews_results, indent=2, ensure_ascii=False))
Output:
{
"product": {
"product_id": 14019378181107046593,
"title": "SteelSeries Aerox 3 2022 Edition Wired Gaming Mouse, Onyx",
"reviews": 68,
"rating": 4.7
},
"ratings": [
{
"stars": 1,
"amount": 1
},
{
"stars": 2,
"amount": 0
},
{
"stars": 3,
"amount": 3
},
{
"stars": 4,
"amount": 13
},
{
"stars": 5,
"amount": 51
}
],
"reviews": [
{
"title": "Great! Almost perfect.",
"date": "February 10, 2022",
"rating": 4,
"source": "Matt · Review provided by bestbuy.com",
"content": "Great mouse! Almost perfect in fact. Shape, weight, tracking, and overall feel are amazing and spot on. A couple things hold it back from being a 5 star. -the PTFE glides are not rounded on the edges. This causes the mouse to sound scratchy and drag on certain mouse mats. In time they will wear down and this will not be a problem. But I instead ordered replacement ones from my go to place anyway. - last thing is the mouse left and right click buttons. Just to much side to side play in these. It was a issue in the original version of this mouse and this seems to be the only issue they didn’t fully fix on the new 2022 version sadly. "
},
... other reviews
{
"title": "Mouse",
"date": "July 3, 2022",
"rating": 5,
"source": "Sam2682 · Review provided by bestbuy.com",
"content": "amazing mouse never seen one better and really help "
}
]
}
Links
Add a Feature Request💫 or a Bug🐞
Posted on December 28, 2022
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.