Performance Best Practices: Running and Monitoring Express.js in Production

Adnan Rahić
Posted on April 28, 2020

What is the most important feature an Express.js application can have? Maybe using sockets for real-time chats or GraphQL instead of REST APIs? Come on, tell me. What’s the most amazing, sexy, and hyped feature you have in your Express.js application?
Want to guess what mine is? Optimal performance with minimal downtime. If your users can't use your application, what's the point of fancy features?
In the past four years, I've learned that performant Express.js applications need to do four things well:
- Ensure minimal downtime
- Have predictable resource usage
- Scale effectively based on load
- Increase developer productivity by minimizing time spent on troubleshooting and debugging
In the past, I've talked a lot about how to improve Node.js performance and related key metrics you have to monitor. There are several bad practices in Node.js you should avoid, such as blocking the thread and creating memory leaks, but also how to boost the performance of your application with the cluster module, PM2, Nginx and Redis.
The first step is to go back to basics and build up knowledge about the tool you are using. In our case the tool is JavaScript. Lastly, I'll cover how to add structured logging and using metrics to pinpoint performance issues in Express.js applications like memory leaks.
In a previous article, I explained how to monitor Node.js applications with five different open-source tools. They may not have full-blown features like the Sematext Express.js monitoring integration, Datadog, or New Relic, but keep in mind they’re open-source products and can hold their own just fine.
In this article, I want to cover my experience from the last four years, mainly the best practices you should stick to, but also the bad things you should throw out right away. After reading this article you'll learn what you need to do to make sure you have a performant Express.js application with minimal downtime.
In short, you'll learn about:
- Creating an intuitive structure for an Express.js application
- Hints for improving Express.js application performance
- Using test-driven development and functional programming paradigms in JavaScript
- Handling exceptions and errors gracefully
- Using Sematext Logs for logging and error handling
- Using dotenv to handle environment variables and configurations
- Using Systemd for running Node.js scripts as a system process
- Using the cluster module or PM2 to enable cluster-mode load balancing
- Using Nginx as a reverse proxy and load balancer
- Using Nginx and Redis to cache API request results
- Using Sematext Monitoring for performance monitoring and troubleshooting
My goal for you is to use this to embrace Express.js best practices and a DevOps mindset. You want to have the best possible performance with minimal downtime and ensure high developer productivity. The goal is to solve issues quickly if they occur and trust me, they always do.
Let's go back to basics, and talk a bit about Express.js.
How to Structure Express.js Applications
Having an intuitive file structure will play a huge role in making your life easier. You will have an easier time adding new features as well as refactoring technical debt.
The approach I stick to looks like this:
src/
config/
- configuration files
controllers/
- routes with provider functions as callback functions
providers/
- business logic for controller routes
services/
- common business logic used in the provider functions
models/
- database models
routes.js
- load all routes
db.js
- load all models
app.js
- load all of the above
test/
unit/
- unit tests
integration/
- integration tests
server.js
- load the app.js file and listen on a port
(cluster.js)
- load the app.js file and create a cluster that listens on a port
test.js
- main test file that will run all test cases under the test/ directory
With this setup you can limit the file size to around 100 lines, making code reviews and troubleshooting much less of a nightmare. Have you ever had to review a pull request where every file has more than 500 lines of code? Guess what, it's not fun.
There's a little thing I like to call separation of concerns. You don't want to create clusterfucks of logic in a single file. Separate concerns into their dedicated files. That way you can limit the context switching that happens when reading a single file. It's also very useful when merging to master often because it's much less prone to cause merge conflicts.
To enforce rules like this across your team you can also set up a linter to tell you when you go over a set limit of lines in a file, as well as if a single line is above 100 characters long. One of my favorite settings, by the way.
How to Improve Express.js Performance and Reliability
Express.js has a few well known best practices you should adhere to. Below are a few I think are the most important.
Set NODE_ENV=production
Here's a quick hint to improve performance. Would you believe that only by setting the NODE_ENV environment variable to production will make your Express.js application three times faster!
In the terminal you can set it with:
export NODE_ENV=production
Or, when running your server.js file you can add like this:
NODE_ENV=production node server.js
Enable Gzip Compression
Moving on, another important setting is to enable Gzip compression. First, install the compression npm package:
npm i compression
Then add this snippet below to your code:
const compression = require('compression')
const express = require('express')
const app = express()
app.use(compression())
If you're using a reverse proxy with Nginx, you can enable it at that level instead. That's covered in the Enabling Gzip Compression with Nginx section a bit further down.
Always Use Asynchronous Functions
The last thing you want to do is to block the thread of execution. Never use synchronous functions! Like, seriously, don't. I mean it.
What you should do instead is use Promises or Async/Await functions. If you by any chance only have access to sync functions you can easily wrap them in an Async function that will execute it outside of the main thread.
(async () => {
const foo = () => {
...some sync code
return val
}
async const asyncWrapper = (syncFun) => {
const val = syncFun()
return val
}
// the value will be returned outside of the main thread of execution
const val = await asyncWrapper(foo)
})()
If you really can't avoid using a synchronous function then you can run them on a separate thread. To avoid blocking the main thread and bogging down your CPU you can create child processes or forks to handle CPU intensive tasks.
An example would be that you have a web server that handles incoming requests. To avoid blocking this thread, you can spawn a child process to handle a CPU intensive task. Pretty cool. I explained this in more detail here.
Make Sure To Do Logging Correctly
To unify logs across your Express.js application, instead of using console.log(), you should use a logging agent to structure and collect logs in a central location.
You can use any SaaS log management tool as the central location, like Sematext, Logz.io, Datadog, and many more. Think of it like a bucket where you keep logs so you can search and filter them later, but also get alerted about error logs and exceptions.
I'm part of the integrations team here at Sematext, building open-source agents for Node.js. I put together this tiny open-source Express.js agent to collect logs. It can also collect metrics, but about that a bit further down. The agent is based on Winston and Morgan. It tracks API request traffic with a middleware. This will give you per-route logs and data right away, which is crucial to track performance.
Note: Express.js middleware functions are functions that have access to the request object (req), the response object (res), and the next middleware function in the application’s request-response cycle. The next middleware function is commonly denoted by a variable named next. - from Using middleware, expressjs.com
Here's how to add the logger and the middleware:
const { stLogger, stHttpLoggerMiddleware } = require('sematext-agent-express')
// At the top of your routes add the stHttpLoggerMiddleware to send API logs to Sematext
const express = require('express')
const app = express()
app.use(stHttpLoggerMiddleware)
// Use the stLogger to send all types of logs directly to Sematext
app.get('/api', (req, res, next) => {
stLogger.info('An info log.')
stLogger.debug('A debug log.')
stLogger.warn('A warning log.')
stLogger.error('An error log.')
res.status(200).send('Hello World.')
})
Prior to requiring this agent you need to configure Sematext tokens as environment variables. In the dotenv section below, you will read more about configuring environment variables.
Here's a quick preview of what you can get.

Handle Errors and Exceptions Properly
When using Async/Await in your code, it's a best practice to rely on try-catch statements to handle errors and exceptions, while also using the unified Express logger to send the error log to a central location so you can use it to troubleshoot the issue with a stack trace.
async function foo() {
try {
const baz = await bar()
return baz
} catch (err) {
stLogger.error('Function \'bar\' threw an exception.', err);
}
}
It's also a best practice to configure a catch-all error middleware at the bottom of your routes.js file.
function errorHandler(err, req, res, next) {
stLogger.error('Catch-All error handler.', err)
res.status(err.status || 500).send(err.message)
}
router.use(errorHandler)
module.exports = router
This will catch any error that gets thrown in your controllers. Another last step you can do is to add listeners on the process itself.
process.on('uncaughtException', (err) => {
stLogger.error('Uncaught exception', err)
throw err
})
process.on('unhandledRejection', (err) => {
stLogger.error('unhandled rejection', err)
})
With these tiny snippets you'll cover all the needed precautions for handling Express errors and log collection. You now have a solid base where you don't have to worry about losing track of errors and logs. From here you can set up alerts in the Sematext Logs UI and get notified through Slack or E-mail, which is configured by default. Don't let your customers tell you your application is broken, know before they do.
Watch Out For Memory Leaks
You can't catch errors before they happen. Some issues don't have root causes in exceptions breaking your application. They are silent and like memory leaks, they creep up on you when you least expect it. I explained how to avoid memory leaks in one of my previous tutorials. What it all boils down to is to preempt any possibility of getting memory leaks.
Noticing memory leaks is easier than you might think. If your process memory keeps growing steadily, while not periodically being reduced by garbage collection, you most likely have a memory leak. Ideally, you’d want to focus on preventing memory leaks rather than troubleshooting and debugging them. If you come across a memory leak in your application, it’s horribly difficult to track down the root cause.
This is why you need to look into metrics about process and heap memory.
Adding a metrics collector to your Express.js application, that will gather and store all key metrics in a central location where you can later slice and dice the data to get to the root cause of when a memory leak happened, and most importantly, why it happened.
By importing a monitoring agent from the Sematext Agent Express module I mentioned above, you can enable the metric collector to store and visualize all the data in the Sematext Monitoring UI.

Here's the kicker, it's only one line of code. Add this snippet in your app.js file.
const { stMonitor, stLogger, stHttpLoggerMiddleware } = require('sematext-agent-express')
stMonitor.start() // run the .start method on the stMonitor
// At the top of your routes add the stHttpLoggerMiddleware to send API logs to Sematext
const express = require('express')
const app = express()
app.use(stHttpLoggerMiddleware)
...
With this you'll get access to several dashboards giving you key insight into everything going on with your Express.js application. You can filter and group the data to visualize processes, memory, CPU usage and HTTP requests and responses. But, what you should do right away is configure alerts to notify you when the process memory starts growing steadily without any increase in the request rate.
Moving on from Express.js-specific hints and best practices, let's talk a bit about JavaScript and how to use the language itself in a more optimized and solid way.
How to Set Up Your JavaScript Environment
JavaScript is neither object-oriented or functional. Rather, it's a bit of both. I'm quite biased towards using as many functional paradigms in my code as possible. However, one surpasses all others. Using pure functions.
Pure Functions
As the name suggests, pure functions are functions that do not mutate the outer state. They take parameters, do something with them, and return a value.
Every single time you run them they will behave the same and return a value. This concept of throwing away state mutations and only relying on pure functions is something that has simplified my life to an enormous extent.
Instead of using var or let only use const, and rely on pure functions to create new objects instead of mutating existing objects. This ties into using higher-order functions in JavaScript, like .map(), .reduce(), .filter(), and many more.
How to practice writing functional code? Throw out every variable declaration except for const. Now try writing a controller.
Object Parameters
JavaScript is a weakly typed language, and it can show its ugly head when dealing with function arguments. A function call can be passed one, none, or as many parameters as you want, even though the function declaration has a fixed number of arguments defined. What's even worse is that the order of the parameters are fixed and there is no way to enforce their names so you know what is getting passed along.
It's absolute lunacy! All of it, freaking crazy! Why is there no way to enforce this? But, you can solve it somewhat by using objects as function parameters.
const foo = ({ param1, param2, param3 }) => {
if (!(param1 && param2 && param3)) {
throw Error('Invalid parameters in function: foo.')
}
const sum = param1 + param2 + param3
return sum
}
foo({ param1: 5, param2: 345, param3: 98 })
foo({ param2: 45, param3: 57, param1: 81 }) // <== the same
All of these function calls will work identically. You can enforce the names of the parameters and you're not bound by order, making it much easier to manage.
Freaking write tests, seriously!
Do you know what's the best way to document your code, keep track of features and dependencies, increase community awareness, gain contributors, increase performance, increase developer productivity, have a nicer life, attract investors, raise a seed round, make millions selling your startup!?.... wait that got out of hand.
Yes, you guessed it, writing tests is the answer.
Let's get back on track. Write tests based on the features you want to build. Then write the feature. You will have a clear picture of what you want to build. During this process you will automatically start thinking about all the edge cases you would usually never consider.
Trust me, TDD works.
How to get started? Use something simple like Mocha and Chai. Mocha is a testing framework, while Chai is an assertion library.
Install the npm packages with:
npm i mocha chai
Let's test the foo function from above. In your main test.js file add this snippet of code:
const chai = require('chai')
const expect = chai.expect
const foo = require('./src/foo')
describe('foo', function () {
it('should be a function', function () {
expect(foo).to.be.a('function')
})
it('should take one parameter', function () {
expect(
foo.bind(null, { param1: 5, param2: 345, param3: 98 }))
.to.not.throw(Error)
})
it('should throw error if the parameter is missing', function () {
expect(foo.bind(null, {})).to.throw(Error)
})
it('should throw error if the parameter does not have 3 values', function () {
expect(foo.bind(null, { param1: 4, param2: 1 })).to.throw(Error)
})
it('should return the sum of three values', function () {
expect(foo({ param1: 1, param2: 2, param3: 3 })).to.equal(6)
})
})
Add this to your scripts section in the package.json:
"scripts": {
"test": "mocha"
}
Now you can run the tests by running a single command in your terminal:
npm test
The output will be:
> test-mocha@1.0.0 test /path/to/your/expressjs/project
> mocha
foo
✓ should be a function
✓ should take one parameter
✓ should throw error if the parameter is missing
✓ should throw error if the parameter does not have 3 values
✓ should return the sum of three values
5 passing (6ms)
Writing tests gives you a feeling of clarity. And it feels freaking awesome! I feel better already.
With this out of my system I'm ready for DevOps topics. Let's move on to some automation and configuration.
Use DevOps Tools To Make Running Express.js in Production Easier
Apart from the things you can do in the code, like you saw above, some things need to be configured in your environment and server setup. Starting from the basics, you need an easy way to manage environment variables, you also need to make sure your Express.js application restarts automatically in case it crashes.
You also want to configure a reverse proxy and load balancer to expose your application, cache requests, and load balance traffic across multiple worker processes. The most important step in maintaining high performance is to add a metrics collector so you can visualize data across time and troubleshoot issues whenever they occur.
Managing Environment Variables in Node.js with dotenv
Dotenv is an npm module that lets you load environment variables easily into any Node.js application by using a file.
In the root of your project create a .env file. Here you'll add any environment variables you need.
NODE_ENV=production
DEBUG=false
LOGS_TOKEN=xxx-yyy-zzz
MONITORING_TOKEN=xxx-yyy-zzz
INFRA_TOKEN=xxx-yyy-zzz
...
Loading this file is super simple. In your app.js file require dotenv at the top before anything else.
// dotenv at the top
require('dotenv').config()
// require any agents
const { stLogger, stHttpLoggerMiddleware } = require('sematext-agent-express')
// require express and instantiate the app
const express = require('express')
const app = express()
app.use(stHttpLoggerMiddleware)
...
Dotenv will load a file named .env by default. If you want to have multiple dotenv files, here's how you can configure them.
Make Sure the Application Restarts Automatically With Systemd or PM2
JavaScript is a scripting language, obviously, the name says so. What does this mean? When you start your server.js file by running node server.js it will run the script as a process. However, if it fails, the process exits and there's nothing telling it to restart.
Here's where using Systemd or PM2 comes into play. Either one works fine, but the Node.js maintainers urge us to use Systemd.
Ensure Application Restarts with Systemd
In short, Systemd is part of the building blocks of Linux operating systems. It runs and manages system processes. What you want is to run your Node.js process as a system service so it can recover from crashes.
Here's how you do it. On your VM or server, create a new file under /lib/systemd/system/ called app.service.
# /lib/systemd/system/fooapp.service
[Unit]
Description=Node.js as a system service.
Documentation=https://example.com
After=network.target
[Service]
Type=simple
User=ubuntu
ExecStart=/usr/bin/node /path/to/your/express/project/server.js
Restart=on-failure
[Install]
WantedBy=multi-user.target
The two important lines in this file are ExecStart and Restart. The ExecStart says that the /usr/bin/node binary will start your server.js file. Make sure to add an absolute path to your server.js file. The Restart=on-failure makes sure to restart the application if it crashes. Exactly what you're looking for.
Once you save the fooapp.service file, reload your daemon and start the script.
systemctl daemon-reload
systemctl start fooapp
systemctl enable fooapp
systemctl status fooapp
The status command will show you the application is running as a system service. The enable command makes sure it starts on boot. That was easier than you thought, am I right?
Ensure Application Restarts with PM2
PM2 has been around for a few years. They utilize a custom-built script that manages and runs your server.js file. It is simpler to set up, but comes with the overhead of having another Node.js process that acts as a Master process, like a manager, for your Express.js application processes.
First you need to install PM2:
npm i -g pm2
Then you start your application by running this command in the root directory of your Express.js project:
pm2 start server.js -i max
The -i max flag will make sure to start the application in cluster-mode, spawning as many workers as there are CPU cores on the server.
Mentioning cluster-mode is the perfect segue into the next section about load balancing and reverse proxies and caching.
Enable Load Balancing and Reverse Proxies
Load balancing can be done with both the Node.js cluster module or with Nginx. I'll show you my preferred setup, which is also what the peeps over at Node.js think is the right way to go.
Load Balancing with the Cluster Module
The built-in cluster module in Node.js lets you spawn worker processes that will serve your application. It's based on the child_process implementation and, luckily for us, is very easy to set up if you have a basic Express.js application.
You only really need to add one more file. Create a file called cluster.js and paste this snippet of code into it:
const cluster = require('cluster')
const numCPUs = require('os').cpus().length
const app = require('./src/app')
const port = process.env.PORT || 3000
const masterProcess = () => Array.from(Array(numCPUs)).map(cluster.fork)
const childProcess = () => app.listen(port)
if (cluster.isMaster) {
masterProcess()
} else {
childProcess()
}
cluster.on('exit', () => cluster.fork())
Let's break down what's happening here. When you start the cluster.js file with node cluster.js the cluster module will detect that it is running as a master process. In that case it invokes the masterProcess() function. The masterProcess() function counts how many CPU cores the server has and invokes the cluster.fork() function that many times. Once the cluster.fork() function is invoked the cluster module will detect it is running as a child process and invoke the childProcess() function, which then tells the Express.js server to .listen() on a port. All these processes are running on the same port. It's possible due to something called an IPC connection. Read more about that here.
The cluster.on('exit') event listener will restart a worker process if it fails.
With this setup you can now edit the ExecStart field in the fooapp.service Systemd service file to run the cluster.js file instead.
Replace:
ExecStart=/usr/bin/node /path/to/your/express/project/server.js
With:
ExecStart=/usr/bin/node /path/to/your/express/project/cluster.js
Reload the Systemd daemon and restart the fooapp.service:
systemctl daemon-reload
systemctl restart fooapp
There you have it. You've added load balancing to your Express.js application. Now it will scale across all the CPUs on your server.
However, this will only work for a single-server setup. If you want to have multiple servers, you need Nginx.
Adding a Reverse Proxy with Nginx
One of the primal laws of running Node.js applications is to never expose them on port 80 or 443. You should always use a reverse proxy to direct traffic to your application. Nginx is the most common tool you use with Node.js to achieve this. It's a web server that can act as both a reverse proxy and load balancer.
Installing Nginx is rather straightforward, for Ubuntu it would look like this:
apt update
apt install nginx
Make sure to check the Nginx installation instructions if you're using another operating system.
Nginx should start right away, but just in case make sure to check:
systemctl status nginx
[Output]
nginx.service - A high performance web server and a reverse proxy server
Loaded: loaded (/lib/systemd/system/nginx.service; enabled; vendor preset: enabled)
Active: active (running) since Fri 2018-04-20 16:08:19 UTC; 3 days ago
Docs: man:nginx(8)
Main PID: 2369 (nginx)
Tasks: 2 (limit: 1153)
CGroup: /system.slice/nginx.service
├─2369 nginx: master process /usr/sbin/nginx -g daemon on; master_process on;
└─2380 nginx: worker process
If it is not started, go ahead and run this command to start it.
systemctl start nginx
Once you have Nginx running, you need to edit the configuration to enable a reverse proxy. You can find the Nginx configuration file in the /etc/nginx/ directory. The main configuration file is called nginx.conf, while there are additional snippets in the etc/nginx/sites-available/ directory. The default server configuration is found here and is named default.
To just enable a reverse proxy, open up the default configuration file and edit it so it looks like this:
server {
listen 80;
location / {
proxy_pass http://localhost:3000; # change the port if needed
}
}
Save the file and restart the Nginx service.
systemctl restart nginx
This configuration will route all traffic hitting port 80 to your Express.js application.
Load Balancing with Nginx
If you want to take it a step further, and enable load balancing, here's how to do it.
Now, edit the main nginx.conf file:
http {
upstream fooapp {
server localhost:3000;
server domain2;
server domain3;
...
}
...
}
Adding this upstream section will create a server group that will load balance traffic across all the servers you specify.
You also need to edit the default configuration file to point the reverse proxy to this upstream.
server {
listen 80;
location / {
proxy_pass http://fooapp;
}
}
Save the files and restart the Nginx service once again.
systemctl restart nginx
Enabling Caching with Nginx
Caching is important to reduce response times for API endpoints, and resources that don't change very often.
Once again edit the nginx.conf file, and add this line:
http {
proxy_cache_path /data/nginx/cache levels=1:2 keys_zone=STATIC:10m
inactive=24h max_size=1g;
...
}
Open up the default configuration file again. Add these lines of code as well:
server {
listen 80;
location / {
proxy_pass http://fooapp;
proxy_set_header Host $host;
proxy_buffering on;
proxy_cache STATIC;
proxy_cache_valid 200 1d;
proxy_cache_use_stale error timeout invalid_header updating
http_500 http_502 http_503 http_504;
}
}
Save both files and restart the Nginx service once again.
Enabling Gzip Compression with Nginx
To improve performance even more, go ahead and enable Gzip. In the server block of your Nginx configuration file add these lines:
server {
gzip on;
gzip_types text/plain application/xml;
gzip_proxied no-cache no-store private expired auth;
gzip_min_length 1000;
...
}
If you want to check out more configuration options about Gzip compression in Nginx, check this out.
Enabling Caching with Redis
Redis in an in-memory data store, which is often used as a cache.
Installing it on Ubuntu is rather simple:
apt update
apt install redis-server
This will download and install Redis and its dependencies. There is one important configuration change to make in the Redis configuration file that was generated during the installation.
Open up the /etc/redis/redis.conf file. You have to change one line from:
supervised no
To:
supervised systemd
That’s the only change you need to make to the Redis configuration file at this point, so save and close it when you are finished. Then, restart the Redis service to reflect the changes you made to the configuration file:
systemctl restart redis
systemctl status redis
[Output]
● redis-server.service - Advanced key-value store
Loaded: loaded (/lib/systemd/system/redis-server.service; enabled; vendor preset: enabled)
Active: active (running) since Wed 2018-06-27 18:48:52 UTC; 12s ago
Docs: http://redis.io/documentation,
man:redis-server(1)
Process: 2421 ExecStop=/bin/kill -s TERM $MAINPID (code=exited, status=0/SUCCESS)
Process: 2424 ExecStart=/usr/bin/redis-server /etc/redis/redis.conf (code=exited, status=0/SUCCESS)
Main PID: 2445 (redis-server)
Tasks: 4 (limit: 4704)
CGroup: /system.slice/redis-server.service
└─2445 /usr/bin/redis-server 127.0.0.1:6379
Next you install the redis npm module to access Redis from your application.
npm i redis
Now you can require it in your application and start caching request responses. Let me show you an example:
const express = require('express')
const app = express()
const redis = require('redis')
const redisClient = redis.createClient(6379)
async function getSomethingFromDatabase (req, res, next) {
try {
const { id } = req.params;
const data = await database.query()
// Set data to Redis
redisClient.setex(id, 3600, JSON.stringify(data))
res.status(200).send(data)
} catch (err) {
console.error(err)
res.status(500)
}
}
function cache (req, res, next) {
const { id } = req.params
redisClient.get(id, (err, data) => {
if (err) {
return res.status(500).send(err)
}
// If data exists return the cached value
if (data != null) {
return res.status(200).send(data)
}
// If data does not exist, proceed to the getSomethingFromDatabase function
next()
})
}
app.get('/data/:id', cache, getSomethingFromDatabase)
app.listen(3000, () => console.log(`Server running on Port ${port}`))
This piece of code will cache the response from the database as a JSON string in the Redis cache for 3600 seconds. You can change this based on your own needs.
With this, you've configured key settings to improve performance. But, you've also introduced additional possible points of failure. What if Nginx crashes or Redis overloads your disk space? How do you troubleshoot that?
Enable VM/Server-Wide Monitoring and Logging
Ideally, you'd configure an Infrastructure Agent on your VM or server to gather metrics and logs and send them to a central location. That way you can keep track of all infrastructure metrics like CPU, memory, disk usage, processes, etc.
This way you can keep an eye on your whole infrastructure, including CPU, memory and disk usage, as well as all the separate processes while running your application in cluster-mode.
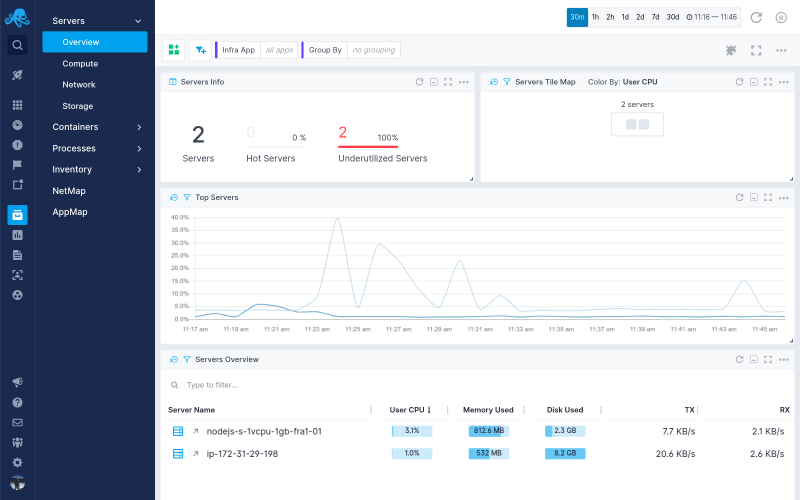
But, we do need to know what's going on with Nginx first. You can configure the stub_status to show Nginx metrics, but that doesn't really give you any actionable insight. But, you can install an Nginx Integration and get insight into Nginx metrics alongside your Express.js Integration in Sematext Cloud.
Why is monitoring Nginx important? Nginx is the entry point to your application. If it fails, your whole application fails. Your Node.js instance can be fine, but Nginx stops responding and your website goes down. You'll have no clue it's down because the Express.js application is still running without any issues.
You have to keep an eye on all the points of failure in your system. That's why having proper alerting in place is so crucial. If you want to learn more about alerting you can read this.
Same goes for Redis. To keep an eye on it, check out ways to monitor Redis, here or here.
That wraps up the DevOps tools and best practices you should stick to. What a ride that was! If you want to delve deeper into learning about DevOps and tooling, check out this guide my co-worker wrote.
Wrapping Up
It took me the better part of four years to start using proper tooling and adhering to best practices. In the end, I just want to point out the most important part of your application is to be available and performant. Otherwise, you won't see any users stick around. If they can't use your application, what's the point?
The idea behind this article was to cover best practices you should stick to, but also the bad practices to stay away from.
You've learned many new things in this Express.js tutorial. From optimizing Express.js itself, creating an intuitive project structure and optimizing for performance to learning about JavaScript best practices and test-driven development. You've also learned about error handling, logging and monitoring.
After all this, you can say with certainty that you've had an introduction to DevOps culture. What does that mean? Well, making sure to write reliable and performant software with test coverage, while maintaining the best possible developer productivity. That's how we as engineers continue loving our job. Otherwise, it's all mayhem.
Hope you all enjoyed reading this as much as I enjoyed writing it. If you liked it, feel free to hit the share button so more people will see this tutorial. Until next time, be curious and have fun.
Posted on April 28, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related
