Machine Learning - Transfer Learning

Sandeep Balachandran
Posted on April 5, 2020

Hey there,
Let us start with a quote.
The trials you encounter will introduce you to your strengths remain steadfast and one day you will build something that endures something worthy of your potential. - Epictetus
Main Content From here
In 2012, AlexNet revolutionized the machine learning world and popularized CNN-based image classifiers by winning ImageNet Large Scale Visual recognition challenge.
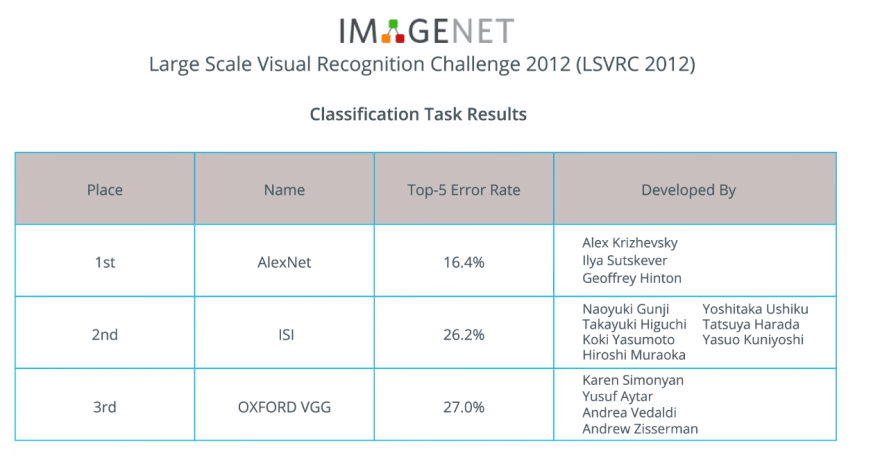
After that, the race was on to make even better and more accurate neural networks that could outperform AlexNet when classifying images on the ImageNet dataset.
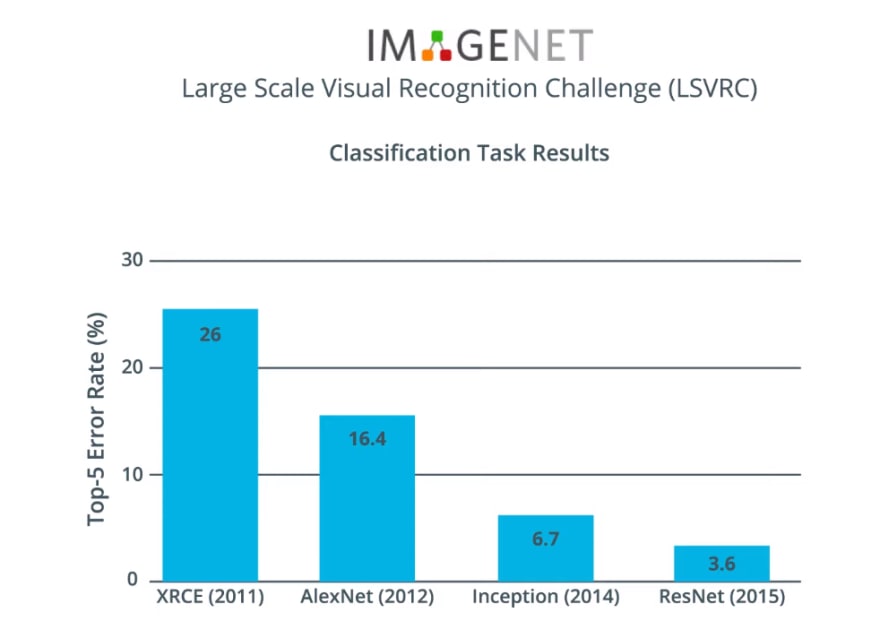
Over the years, several models have been developed that have performed better than AlexNet.
Two of which are
- Inception
- resonant
Wouldn't it be great if we could take advantage of pre-trained neural networks such as these, that have been developed by expert researchers and use them for our own purposes? As it turns out, we can take advantage of these high-performance neural networks by using a technique called transfer learning. The idea behind transfer learning is that a neural network that has been trained on a large dataset can apply its knowledge to a dataset it has never seen before.
That's why it's called transfer learning because we transfer the learning of an existing model to a new dataset.
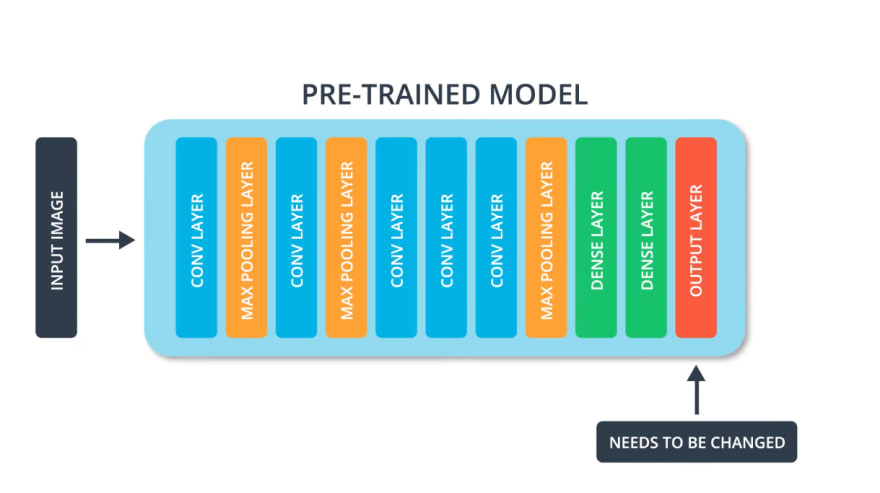
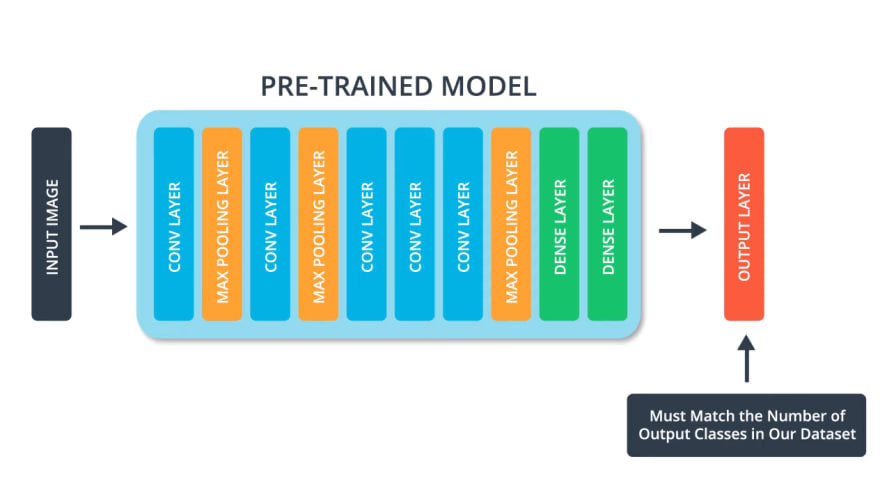
In order to perform transfer learning, we need to change the last layer of the pre-trained model.
This is because each dataset has a different number of output classes.
For example, the ImageNet dataset has a 1000 different output classes.
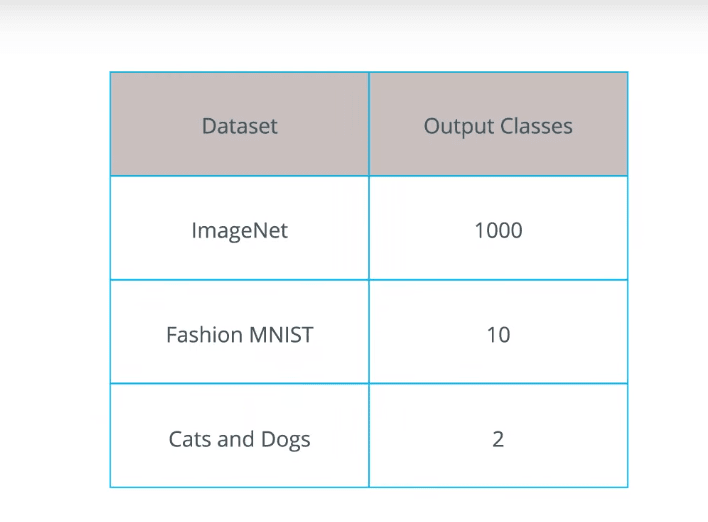
While the fashion in this dataset has 10 classes, and our cats and dogs dataset has only two classes. Therefore, we need to change the last layer of an existing model, so that it has the same number of classes that we have in our dataset.
Also, we have to make sure that we don't change the pre-trained part of the model during the training process. This is done by setting the variables of the pre-trained model to non-trainable.
This is also called freezing the model.
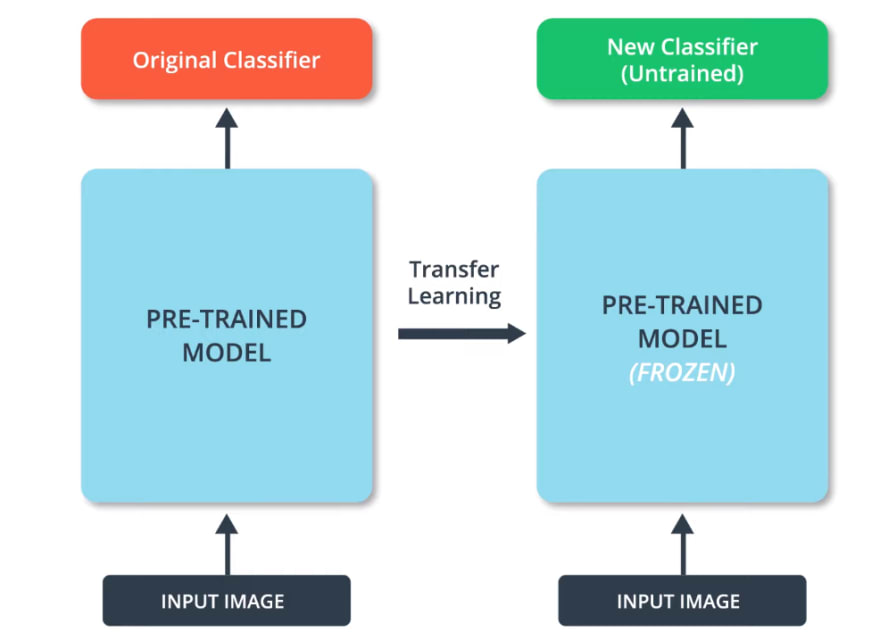
By freezing the perimeters, we'll ensure that only the variables of the last classification layer get trained.

Well, the variables from the other layers of the pre-trained model are kept the same.
- A nice additional benefit from this is they will also reduce the training time significantly because we're only training the variables of our last classification layer and not the entire model.
- If we don't freeze the pre-trained model, the features learned by it will change during training.
- This is because our new classification layer will be untrained.
- Therefore, at the beginning of the training, its weights will be initialized randomly.
- Due to the random initialization of the weights, our model will initially make large errors.
- These in turn, would be propagated backwards through our pre-trained model causing erroneously large updates to the already useful weights of the pre-trained model, and that's undesirable.
- Therefore, we must always remember to freeze the parameters of our pre-trained model when we perform transfer learning.
- Now that we know how transfer learning works, we need to decide which pre-trained network we're going to use. We'll do that in the next lesson.
Have you heard about the MobileNet? Let us see that in the next post.
Posted on April 5, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related

May 28, 2022
