
Sam Zhang
Posted on July 21, 2020

Crawling websites are always fun. Have you ever thought about crawling Google search results? Well, in this tutorial, you'll create a dead-simple web spider to crawl Google's search results using Python. I assume that you know the basics about Python, BeautifulSoup and requests.
WARNING: Don't ever use this spider to scrape lots of data. As of Google provides a public API that allows you to call 100 times for free, your IP will be banned if Google noticed the unusual traffic from your computer. This spider is built only for learning purposes, and it shouldn't be used in real projects. So keep that in mind, and we'll get started.
Getting Ready
First of all, install BeautifulSoup and requests using pip. I'll just skip that here 'cause I guess you guys know how to install them. Leave a comment if you are having trouble with installation.
Analyzing the Web Page
Search Google for something, for example, Python, and right-click to view the source code:
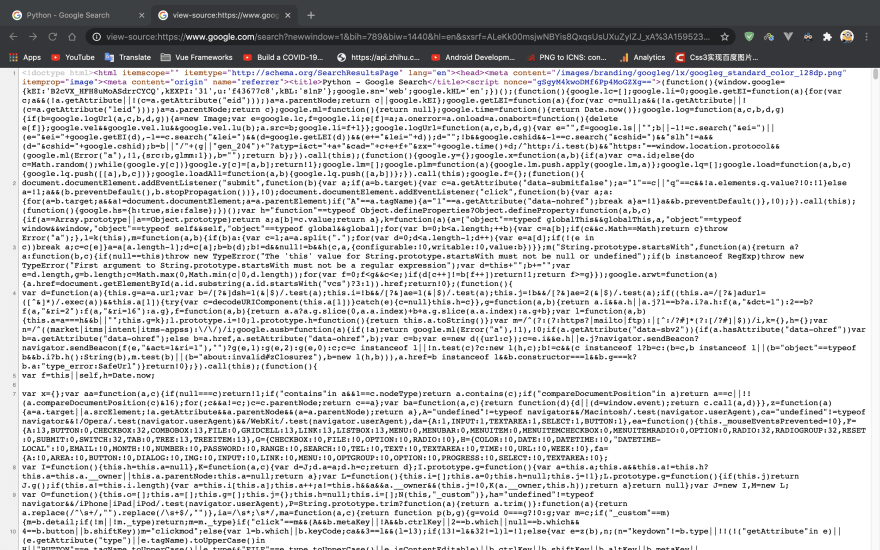
It's really a mess. Let's format it and remove the script tags and the style tags:
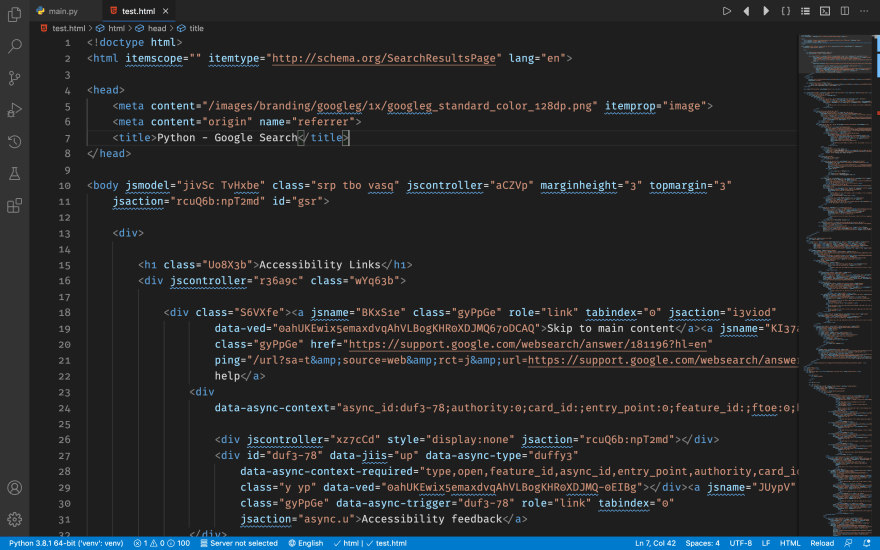
Wow, still 2000 lines of code! Let's see what's really important.
Important Things
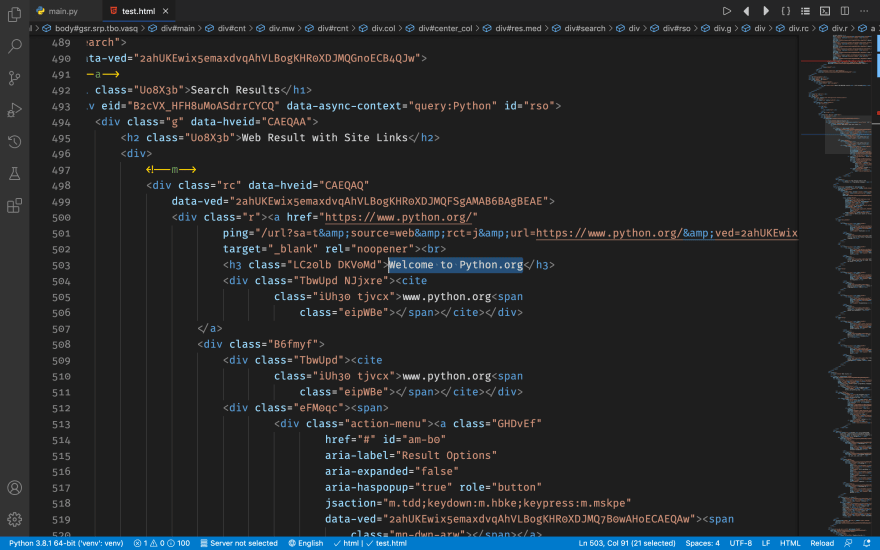
Search for Welcome to Python.org (the first result when searching Python):

Then, search for Python (programming language) (the second result):

We can see that the two results are styled by the class rc. Great, now we've found the important class name - let's move on.
Notice that most of the class names in Google are generated randomly by a script. Never analyze these class names: your work might be wasted after you refresh the page!
Going Further
So now we've got the result container, let's work on the details. Take a look at the result container, and you can see that the link is right in an a element inside a div styled with the class r:

And the title in h3:
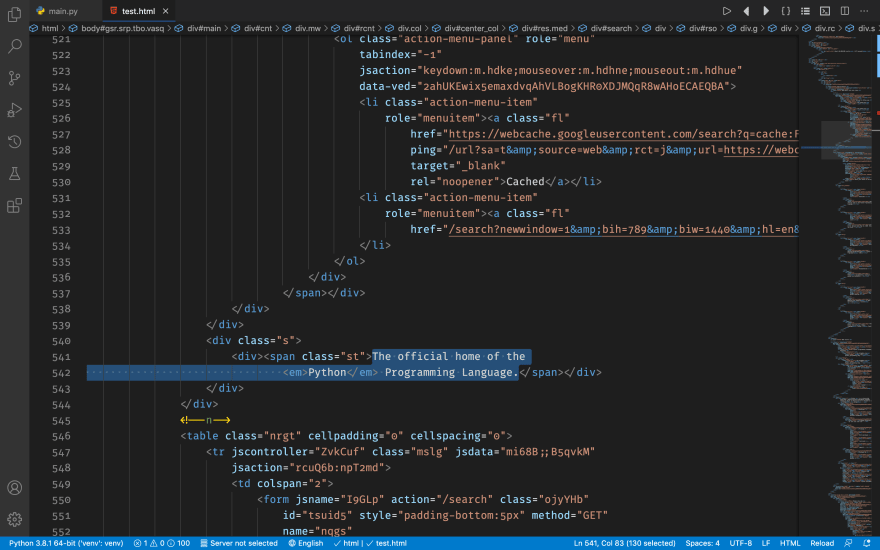
...and finally the description in a span with class st and surrounded by two divs. The outer one is styled by the class s:
Great! Now we've got the structure of the web page, and let's get to code!
Let's Code
Open your favorite code editor (I'm using VSCode), and open the folder you just created with the dependencies you just installed at the beginning of this tutorial. Create main.py and import the dependencies we needed:
# Import dependencies
from bs4 import BeautifulSoup
import requests
And let's create a class to put all of our code in it:
class GoogleSpider(object):
def __init__(self):
"""Crawl Google search results
This class is used to crawl Google's search results using requests and BeautifulSoup.
"""
super().__init__()
def __get_source(self, url: str) -> requests.Response:
"""Get the web page's source code
Args:
url (str): The URL to crawl
Returns:
requests.Response: The response from URL
"""
pass
def search(self, query: str) -> list:
"""Search Google
Args:
query (str): The query to search for
Returns:
list: The search results
"""
pass
First, let's get the web page source. Take a look at the URL at your browser's address bar: there's lots of strange code that humans can't understand, right? Let's take them out and only leave the necessary ones:
https://www.google.com/search?q=Python
If you visit it, you can see that the page is the same than you just visited! Alright, let's see what's in the URL.
Analyzing the URL
We can see that the URL above only has one query param: q. You can see it like the query you are going to search. But, there's a problem: when you enter special chars, like +, %, (, ), and so on, Google won't understand them. We need to quote them to the form that websites can understand. To quote them, we need to use the function quote from urllib.parse:
# Import dependencies
from bs4 import BeautifulSoup
import requests
from urllib.parse import quote
# ...
Great, now we are ready to crawl the webpage!
Crawling the Web Page
It's pretty simple, you just need to call get() method from requests:
class GoogleSpider(object):
# ...
def __get_source(self, url: str) -> requests.Response:
"""Get the web page's source code
Args:
url (str): The URL to crawl
Returns:
requests.Response: The response from URL
"""
return requests.get(url)
# ...
Let's test it:
# ...
class GoogleSpider(object):
# ...
def search(self, query: str) -> list:
"""Search Google
Args:
query (str): The query to search for
Returns:
list: The search results
"""
return self.__get_source('https://www.google.com/search?q=%s' % quote(query))
if __name__ == '__main__':
print(GoogleSpider().search('Python'))
After you run the program, you'll likely be seeing the message below:
<Response [200]>
It looks normal, right? But, when you look at its source code:
print(GoogleSpider().search('Python').text)
You'll see that all of the class names are randomly generated! Don't worry, it's all because of one thing: the headers.
Configuring Headers
We need to define headers first. But, let's talk about headers now rather than coding. User-Agent headers are a special type of header that tells the website who requested this request. You can think like it's a name of the request sender. By default, requests will use python-requests/x.x.x, where as x.x.x is your requests version. A browser will send the User-Agent like this:
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36
The UA above was sent by a Google Chrome browser on macOS 10.14. So, if we pretend that we are the browser, using the UA, we can easily go pass this "gate".
Alright, then let's get coding!
We need to define the headers as I said above. Let's define it in the __init__ method:
class GoogleSpider(object):
def __init__(self):
"""Crawl Google search results
This class is used to crawl Google's search results using requests and BeautifulSoup.
"""
super().__init__()
self.headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:79.0) Gecko/20100101 Firefox/79.0',
'Host': 'www.google.com',
'Referer': 'https://www.google.com/'
}
# ...
PS: I've added a few other headers to make us more "browser-like".
Then, we'll use the header to crawl Google:
class GoogleSpider(object):
# ...
def __get_source(self, url: str) -> requests.Response:
"""Get the web page's source code
Args:
url (str): The URL to crawl
Returns:
requests.Response: The response from URL
"""
return requests.get(url, headers=self.headers)
# ...
Now you run the program again, you'll see the normal source code. Next, we'll start the most important part of this spider: analyze the source code.
Using BeautifulSoup To Analyze the Source
Since I assume that you know BeautifulSoup basics, let's dive in and start coding.
First of all, we need to define a variable to store the response, instead of returning them:
class GoogleSpider(object):
# ...
def search(self, query: str) -> list:
"""Search Google
Args:
query (str): The query to search for
Returns:
list: The search results
"""
# Get response
response = self.__get_source('https://www.google.com/search?q=%s' % quote(query))
OK, then we'll initialize BS 4:
# Initialize BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')
Then, we'll have to locate the result containers using soup.findAll():
# Get the result containers
result_containers = soup.findAll('div', class_='rc')
Finally, loop through every result and get the details:
# Final results list
results = []
# Loop through every container
for container in result_containers:
# Result title
title = container.find('h3').text
# Result URL
url = container.find('a')['href']
# Result description
des = container.find('span', class_='st').text
results.append({
'title': title,
'url': url,
'des': des
})
At last, return the results:
return results
You can now run the program to see Google's search results. To search Google for different queries, you need to change the query param to the query you wanted to search for.
Full Code
The full code for this tutorial is below.
# Import dependencies
from bs4 import BeautifulSoup
import requests
from urllib.parse import quote
from pprint import pprint
class GoogleSpider(object):
def __init__(self):
"""Crawl Google search results
This class is used to crawl Google's search results using requests and BeautifulSoup.
"""
super().__init__()
self.headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:79.0) Gecko/20100101 Firefox/79.0',
'Host': 'www.google.com',
'Referer': 'https://www.google.com/'
}
def __get_source(self, url: str) -> requests.Response:
"""Get the web page's source code
Args:
url (str): The URL to crawl
Returns:
requests.Response: The response from URL
"""
return requests.get(url, headers=self.headers)
def search(self, query: str) -> list:
"""Search Google
Args:
query (str): The query to search for
Returns:
list: The search results
"""
# Get response
response = self.__get_source('https://www.google.com/search?q=%s' % quote(query))
# Initialize BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')
# Get the result containers
result_containers = soup.findAll('div', class_='rc')
# Final results list
results = []
# Loop through every container
for container in result_containers:
# Result title
title = container.find('h3').text
# Result URL
url = container.find('a')['href']
# Result description
des = container.find('span', class_='st').text
results.append({
'title': title,
'url': url,
'des': des
})
return results
if __name__ == '__main__':
pprint(GoogleSpider().search(input('Search for what? ')))
Conclusion
Of course, I know that this is really simple: it can't crawl video results, news results, picture results, and so on. But, it is a great template for learning web scraping in Python. Hope you enjoy this tutorial, and leave a comment if you are having trouble with anything in this tutorial.
Posted on July 21, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related




November 13, 2024