Data Pipelines with Great Expectations | Introduction

Samuel Earl
Posted on January 31, 2023
My background is mostly in web development, but I am learning data engineering because I am interested in business intelligence and want to level-up my knowledge. One of the things that I have recently discovered is data validation within a data pipeline. Let me share a quick example from a previous job I had that illustrates the need for data validation in a data pipeline.
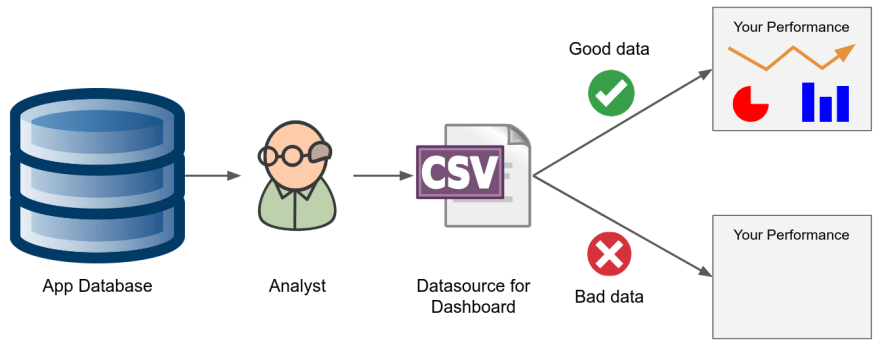
We had a web app that allowed our clients to log into an account and view performance data in a dashboard. That dashboard was the main landing page that users would see after they logged in. The dashboard pulled its data from a datasource that was managed by a group of analysts. The analysts would pull data from a database, perform some analyses, and update the data that was used in the dashboard.
The problem was that the analysts would accidentally change the structure of the data sometimes and the dashboard in our web app would fail silently. When we finally discovered the failures, then we had to figure out who changed the data and try to get it fixed before it affected too many of our users. (Clearly we had some automation issues, but this kind of problem exists even with automated data pipelines that are well architected.)
We could have really benefited from using Great Expectations. Let me show you why.
NOTE: Instead of writing out “Great Expectations” I will abbreviate it as “GX” from now on in this tutorial.
What does GX do and where does it fit in a data pipeline?
This is an example of a simple architecture that uses GX:
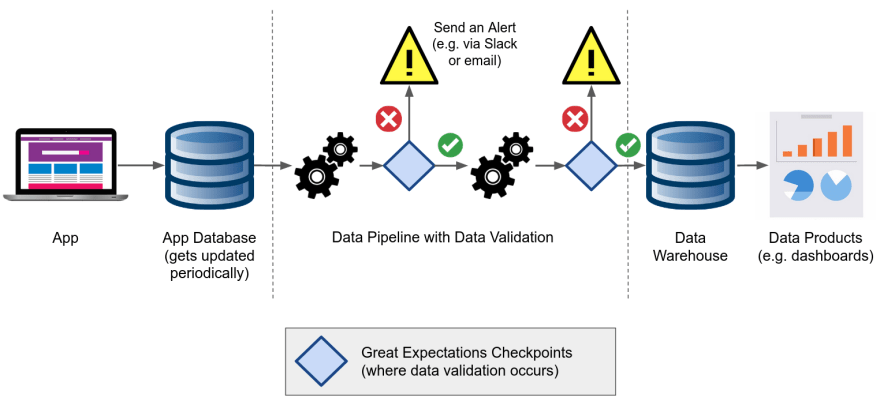
GX is used to validate data within a data pipeline. You can place GX Checkpoints at any stage in a pipeline where data needs to be checked for quality before it moves onto the next stage.
When using GX in a data pipeline, if the data passes validation, then it can move to the next stage in the pipeline. If the data does not pass validation, then we need to alert the proper stakeholders (e.g. data engineers) so they can fix the issues before end users are affected.
What will we be doing in this tutorial?
We are going to use some datasets from the NYC taxi data to demonstrate how GX works. Specifically, we are going to use two datasets: January 2019 and February 2019. Each dataset contains 10,000 records and each record represents one taxi ride with multiple columns of data (e.g. pick-up location, drop-off location, payment amount, number of passengers).
In our scenario, we know that the January data is clean and it matches what we expect. So we are going to use that dataset to create some validation rules. Then we are going to run the February dataset (i.e. batch) through our validation rules to see if the February data passes validation.
Posted on January 31, 2023
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.