Process & Thread Synchronisation

Sam Cullen
Posted on March 3, 2022

Introduction
Linux is a multitasking operating system, which means that many different processes can be running all while at the same time. This document will investigate how Linux manages processes in terms of effectiveness and how well the management system runs when creating and/or deleting processes.
This project will discuss the different types of processes within the Linux Operating System (OS). For this document, I will be discussing the concepts of Processes and Thread Synchronisation in two separate sections.
Section 1 will explain the processes under the following headings:
- Process Management
- Process Creation
- Process Scheduling
- Process Destruction
Section 2 will explain thread synchronisation under the following headings:
- Race Condition
- Mutex Locks
- Critical Section Problem
- Solutions to Critical Section Problems
- Deadlock and Starvation


Section 1
Process Management
Process management is a key factor that carries out various tasks like creating, scheduling, terminating processes, and a deadlock. The purpose of the OS is to manage all the running processes of the system. It handles all operations by performing tasks such as process scheduling and resource allocation.
A process needs specific resources to run, CPU time, memory, I/O devices, etc. to finish its given task. The resources are used by the process when they are required at that given time when the process is firstly being created or in the stage of processing. It is essential to note that a program and a process are not the same, a program is a passive entity, like the contents on a disk, whereas a process is an active entity.
A process is the unit of work in a system. A system consists of a collection of processes, some of which are OS processes. All these processes can execute simultaneously by multiplexing on a single CPU for example. The OS is responsible for the following activities in connection with process management:
• Scheduling processes and threads on the CPU
• Creating and deleting both user and system processes
• Suspending and resuming processes
• Providing mechanisms for process synchronization
• Providing mechanisms for process communication
A process can have many states ranging from creation to deletion. The 5 main states are known as the process life cycle: new, ready, running, ready, terminated. For the OS to keep track of what process is being carried out at a given time, it uses a context switch. A context switch is a process of storing the state of a process or thread so that it can restore and resume execution later at a given point when ready. A context switch saves the current state of the running process before it passes to another process. When it returns to the previous process, it loads the state from the PCB (Process Control Block). This can allow many processes to share one central processing unit (CPU) and is an essential feature for a multitasking OS.

Process architecture is the structural design of the general process systems. It applies in fields such as business processes (enterprise architecture, policy, and procedures, logistics, project management, etc.), and computers (software, hardware, networks, etc.), and any other process system with varying degrees of difficulty.
A process control block is a data structure used by a computer OS to store all sorts of information about a process. The OS creates a process control block when a process is initialized.
The process control block stores valuable data items that are needed for effective process management. See figure 2 below:
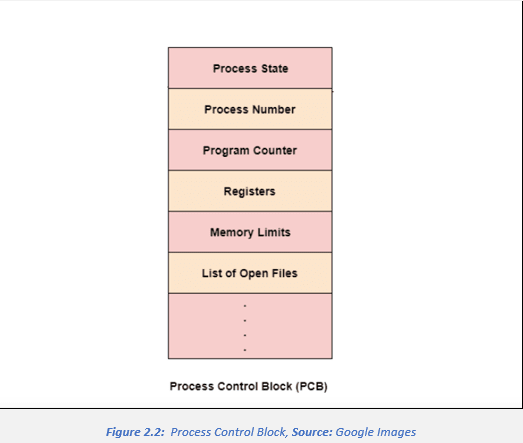
• Process State: Specifies the current state the process is in i.e., new, ready, running, ready, terminated
• Program Counter: This stores the address of the next instruction to be carried out that needs to be executed in the process
• CPU Registers: This specifies the registers which are used by the process. For example, it can include stack pointers, index registers, general-purpose registers, etc
• List of Open Files: List of the types of files that are related to the process
• CPU Scheduling Information: The process pointers, process priority, etc. is the CPU scheduling information which is enclosed in the PCB
• Memory Management Information: The memory management information includes page tables or segment tables depending on what memory storage is used. It can also contain the value of the limit registers, base registers, etc
• I/O Status Information: The I/O Status information includes a list of I/O devices that are used by the process
• Location of the Process Control Block: The PCB is kept inside a memory area which prevents normal user access. It is done so it can protect valuable process information from a user who may not be allowed given access to the information. Some of the OS places the PCB at the very beginning of the kernel stack for the process as it is a safe place to be stored
Process Creation
Whenever we run a program a process is created, and after the execution is completed, it is terminated. Using process creation, we can create a process within a program that is wanted to do a different task at a scheduled time.
Process creation is achieved when one of the functions are called: vfork, _Fork, posix_spawn, or fork. The newer processes are called the child process, and the process which initiates the child process is called the adult process. After you call the fork() system, you have two processes: parent and child. See figure 3 below:
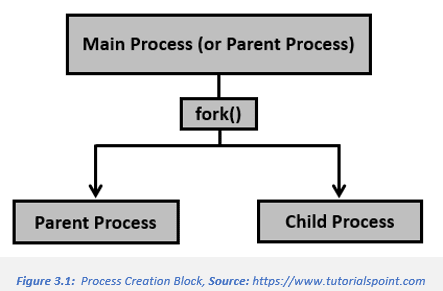
When the new process has been created it has to be changed from a copy of its parent process to represent the program it was made for. An exec system call is used to carry out this task. The exec system can perform many different functions e.g., execl() function: “A call to execl() replaces the current process image with a new one by loading into memory the program pointed at by path”, (Love, 2007).

For a process to be created, four principal events need to happen first:
• System Initialisation
• Execution of process creation system call by a running process
• A user requests to create a new process
• Initiation of a batch file/job
When an OS is started, many processes are created in the process and work either as foreground processes or background processes.
Foreground refers to a task, application, window, etc. that requires the user to start them or interact with them in some way.
E.g., An internet web browser open on a window is an active foreground application.
Background processes are processes that can run independently without the user having to start or interact with them.
E.g., Have a program like YouTube, for example, having a video running in the background even after minimizing the page and/or being on a different website in the meantime.
Process Scheduling
The purpose of multiprogramming is to have one or more processes always running to maximize CPU utilization. Time-sharing works in a way to switch the CPU among processes so frequently and efficiently that users can interact with any programs while still running. For this objective to succeed, the process scheduler selects an available process for execution on the CPU.
There are six types of Process schedules:
- First Come First Serve (FCFS) / First In First Out (FIFO)
- Scheduling
- Shortest Job First (SJF)
- Round Robbin
- Shortest Remaining Time
- Multi-level queue scheduling
Scheduling Queues
Processes that belong to the main memory and are ready and waiting to be executed are kept on a list called the ready queue. This queue is commonly stored as a linked list.
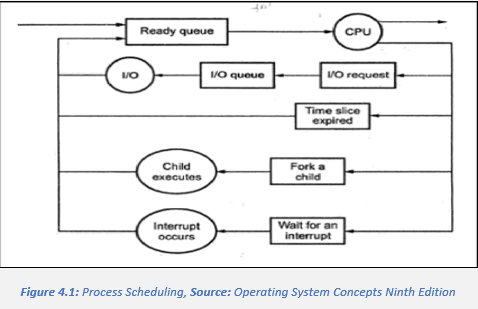
As processes enter the system, (Silberschatz, 2018) they are put into a job queue which consists of all processes in the system. A ready-queue header contains pointers to the first and last PCBs (process control blocks) in the list. With every PCB there is a pointer that points to the next PCB that is ready and waiting to be executed. When the process is allocated to the CPU, the system executes for a while and is eventually either interrupted, stops, quits, or waits for a certain call or occurrence to happen. Sometimes when there are many processes in a system, the disk may be busy with the I/O request for some processes, meaning some processes must wait for the disk. The list of processes waiting for a particular I/O device is called a device queue.

Process Destruction
On most computer operating systems, a computer process terminates its execution by making some type of exit/abort system call. An exit in a multithreading environment means that a thread of execution has stopped running. The OS then recovers its resources like memory or files that were used by the process when it was being carried out. When a program is said to be terminated, it is known as a dead process.
Most operating systems allow the terminating process to provide a specific exit status to the system. Usually, this is done with an integer value (0), or with some languages, it is done with a character or string. For the final steps of termination, a primitive system exit call is started, telling the OS that the process has terminated, allowing the OS to reclaim the resources that were used during the process. Process termination occurs when a process is terminated. The exit() system call is used by most operating systems for process termination, usually indicated in the top right of the screen an(X)s.

Examples of some causes of process termination are:
• A child process can be terminated if its parent process requests for its termination
• If an I/O failure occurs for a process, it can be terminated, for example, if a process required a printer and it is not working, the process will terminate itself
• In many but not all cases, when a parent process is terminated any child processes linked to that parent process will also be terminated with it
• A process may terminate itself if it has completed its execution or objective, then releases all its resources
The four types of process terminations which are
Voluntary
- Normal exit
- Error Exit
Involuntary
- Killed by another process
- Fatal Error
Section 2
Race Condition
A race condition is an unwanted situation that occurs when a device or system attempts to perform two or more operations at the same time as each other. But due to the nature of the system, the operations cannot be carried out at the same time and must be done in the proper order to be done correctly.
Several processes access and process the manipulations over the same data simultaneously, the outcome depends on the order that the access is taking place. These race conditions can be avoided if the critical section is treated as an atomic instruction. Also, proper thread synchronization using locks or atomic variables can prevent race conditions.

Critical section is a code segment that can be accessed by only one process at a time. The critical section contains shared variables that need to be synchronized to maintain consistency of data variables. Any solution to the critical section problem must satisfy three requirements:
• Mutual Exclusion: If a process is executing in its critical section, then no other process is allowed to execute in the critical section
• Bounded Waiting: A bound must exist several times so that other processes are allowed to enter their critical sections after a process has made a request to enter its critical section and before that request is granted
• Progress: If no process is executing in the critical section and other processes are waiting outside the critical section, then only those processes that are not executing in their remained section can participate in deciding which will enter the critical section next, and the selection cannot be postponed indefinitely


Mutex Locks
Operating-systems designers build software tools to solve the critical section problem. The simplest of these tools is the mutex lock. A mutex lock is a locking mechanism used to synchronize access to a particular resource. Only one task can obtain a mutex lock at one given time and only the owner can release the lock. They are used to ensure exclusive access to data shared between threads. For an example of acquire() call, see figure 6 below:

With a mutex lock, a Boolean variable is available whose value indicates if the lock is available or not. The acquire() function acquires the lock, and the release() function releases the lock. If the lock is available, a call to acquire() succeeds, and the lock is then noted as unavailable. A process that attempts to acquire an unavailable lock is blocked until the lock is released. The acquire() and release() calls both must be performed atomically.
While a process is in its critical section, any other process that tries to enter its critical section will have to loop continuously in the call to acquire() until ready to be called. This type of mutex lock is called a spinlock because the process “spins” while waiting for the lock to become ready. This continuous looping can be a problem in a real multiprogramming system where a single CPU is shared among many processes. Busy waiting wastes CPU cycles that some other processes might be able to use productively.
With a spinlock, a context switch is not required when a process waits on a lock, therefore, when a lock is expected to be held just for a short time, spinlocks are useful. They are usually employed on multiprocessor systems where one thread can “spin” on one processor while another thread performs its critical section on another process.
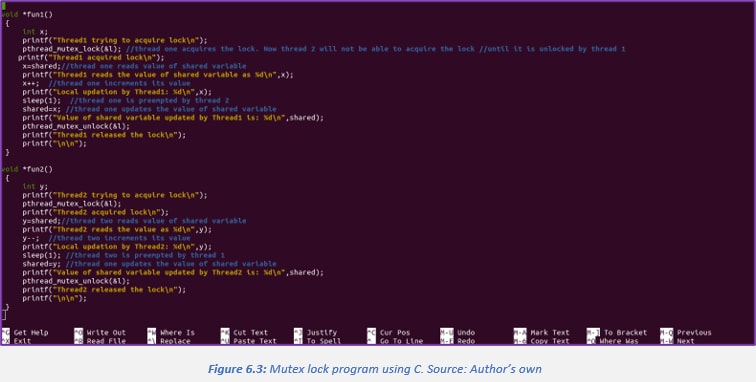
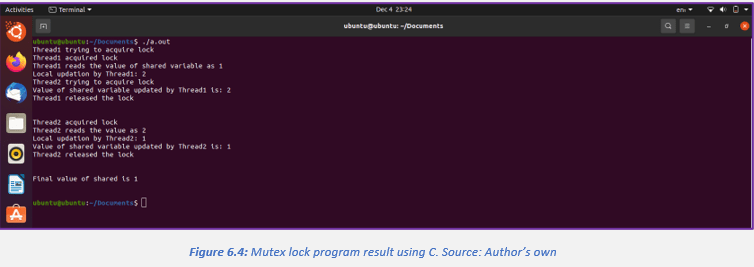
Critical Section Problem
Each process has a segment of code called a critical section, in which the process may be doing different processes like changing common variables, updating a table, writing a file, and so on. The important feature of the system is that when one process is executing in its critical section, no other process is allowed to execute in its critical section. The critical-section problem is to design a protocol that the processes can use to cooperate. Each process must request permission to enter its critical section if it wants to be called. The section of code implementing this request is the critical section. The critical section may be followed by an entry section, which then may be followed by the exit section, and finally, any code left over is the remainder section. (Tanenbaum, 2015)
The two general approaches that are used to handle critical sections in operating systems: pre-emptive kernels and non-pre-emptive kernels. A pre-emptive kernel allows a process to be pre-empted while it is running in kernel mode, while a non-pre-emptive kernel does not allow a process running in kernel mode to be pre-empted; a kernel-mode process will run until it exits kernel mode, blocks, or yields control of the CPU. Therefore, a pre-emptive kernel is more suitable for real-time programming, as it will allow a real-time process to pre-empt a process currently running in the kernel.
Solutions to Critical Section Problems
In Process Synchronisation, the critical section plays the main role so that the problem must be solved.
A solution to the critical section problem must satisfy the following three requirements:
Mutual exclusion
Mutual exclusion property of concurrency control, which is introduced to prevent race condition. It is the requirement that one thread of execution is never entering the critical section while a coexisting thread of execution is already accessing critical section, which refers to an interval of time during which a thread of execution accesses a shared resource, e.g., shared memory or shared data objects.
This race condition problem can be avoided by using the requirement of mutual exclusion to ensure that simultaneous updates to the same part of the list cannot occur.
Progress
If no process is executing in its critical section and some processes wish to enter their critical sections, then only those processes that are not in their remainder section can take part in deciding which will enter its critical section next, and this selection cannot be postponed indefinitely.
Bounded Waiting
After a process has requested getting into its critical section, there is a set limit for how many other processes can also get into their critical section, before this current process’ request is granted.
Another commonly used method for solving the critical section problem is Peterson’s Solution
Peterson’s Solution
Peterson’s algorithm is a programming algorithm for mutual exclusion that allows two or more processes to share a single-use resource without conflict using only shared memory for communication. His solution is a widely used solution to critical section problems, this algorithm got its name from its developer computer scientist Peterson. In this solution, if a process is executing in a critical state, then the other may execute the rest of the code and the opposite can happen.

This algorithm also satisfies the three essential criteria for solving the critical section problem mentioned above; mutual exclusion, progress, and bounded waiting.
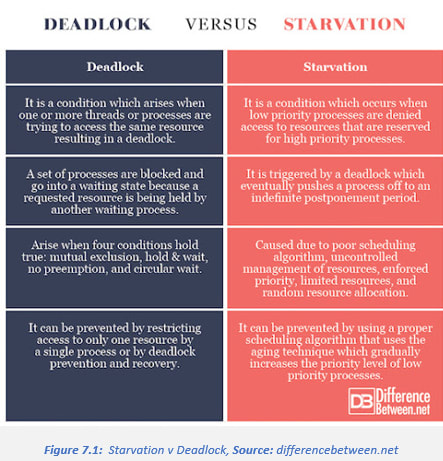
Deadlock and Starvation
Deadlock
Deadlock is a situation that happens in OS when a process enters a waiting stage because another waiting process is holding onto the needed resource, or when two or more transactions block each other by holding onto resources that each transaction needs. It is a common problem in multi-processing when you have several processes sharing the same type of resource known as a soft lock or software. The four main conditions of deadlock are mutual exclusion, hold and wait, No pre-emption, and circular wait.
Mutual exclusion: At least one process must be held in a non-sharable mode.
Hold and wait: There must be a process holding one resource and waiting for another.
No pre-emption: Resources cannot be pre-empted.
Circular wait: There must exist a set of processes.
Starvation
Starvation is the problem that occurs when high priority processes keep executing and low priority processes get blocked for an indefinite time. A steady stream of higher priority processes can prevent a low-priority process from even getting the CPU. In starvation, resources are utilised by high priority processes. It is usually caused by an overly simplistic scheduling algorithm, for example, if a poorly designed multi-tasking system always switches between the first two tasks while a third never gets to run, then the third task is being starved of CPU time.
The problem of starvation can be resolved by using Aging. In Aging, the priority of long waiting processes is gradually increased. Aging is a technique of gradually increasing the priority of processes that wait in the system for a long time to avoid starvation. It is used to increase the priority of a task based on its waiting time in the ready queue.
For example, (Silberschatz, 2006) suppose a system with a priority range of 0-512. In this system, 0 means highest priority. Consider a process with priority 127. If we increase its priority by 1 every 15 minutes, then in more than 32 hours the process will age to 0 priority and be executed.
Conclusion
To conclude this document. We have discussed in detail the Linux Operating System processes with example of code under the headings: Process Management, Process Creation, Process Scheduling and Process Destruction, Race Condition, Mutex Locks, Deadlock and Starvation. These topics were demonstrated using C and C++ code with references throughout the document from online sources and books.
Bibliography
List 1
Love 2007, p129 Craig Lawlor, 2020. | Example Project for Editing in Class, Accessed on 13/11/2021
Silberschatz, A, Galvin, P.B and Gagne, G. 2006. Operating System Principles, John Wiley & Sons.
Silberschatz, Abraham and Gagne, G, 2018. I PB Galvin. Operating System Concepts
Tanenbaum, Pearson, A.S and Bos, H., 2015. Modern operating systems.
List 2
https://dextutor.com/process-synchronization-using-mutex-locks/
https://dextutor.com/program-to-create-deadlock-using-c-in-linux/
https://www.geeksforgeeks.org/
https://www.sciencedirect.com/science/article/pii/S0743731510000304
https://www.stackoverflow.com/
https://www.w3schools.com/cpp/cpp_switch.asp
https://www.youtube.com/watch?v=dIkmqS2wAFE
Silberschatz, Abraham and Gagne, G, 2018. I PB Galvin. Operating System Concepts
Posted on March 3, 2022
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related