
ryanfiller
Posted on April 28, 2020
Last year, my friend Josh brought up the idea of starting a development blog together. He even went through all the trouble buying a url and setting us each our own subdomain. This seemed like a fun idea, but since I already had my own blog about development writing a second one seemed like more work than I would have time for.

But, since I did already have a blog, it made me curious to see if I could syndicate my posts from one site to the other. I put together a quick site with Material-UI and started trying to figure out how to get data out of one Gatsby site and into the other.
Gatsby has GraphQL, right?
Yes, it does - and trying to directly query that endpoint was my first thought. localhost:8000/ __graphiqlis a thing, so ryanfiller.com/__ graphiql probably is too, right?
Well, no.
Gatsby has a long section of their docs about Graphql, but the short version of it is that Gatsby is a static site generator, not a server side application. This means that while running locally, or during build time, a queryable graph exists and is used to gather data and generate pages. Once the production site is built from that data, that graph goes away and the generated site is sent to production, and therefore there is no live GraphQL endpoint on a deployed Gatsby site.
Getting Data Out
Since accessing GraphQL directly at run time is not an option, the next step is to set up a custom API endpoint and have one site make a fetch call to the other.
Two Competing Data Types
For scenarios like this there are two obvious ways to format the endpoint - JSON and RSS. There are pros and cons to both approaches (and I even went down a route on my old site using the JSON Feed standard), but it seems like RSS is still the most common type for syndicating data to sites such as dev.to or Medium. JSON seems to be the standard for posting and grabbing complex data, and RSS for content. I ended up settling on an RSS endpoint, but the same principles should apply to a JSON feed.
Getting Gatsby to Format Data
The easiest way to do add any functionality in Gatsby is to look for a plugin, and luckily for RSS feeds there's one built by the Gatsby team. To look into how this plugin works, the magic happens in its src/gatsby-node.js file. The plugin either uses its default serialize function or takes one from its configuration object, and uses this function to query the appropriate posts, map through them, and format them into a new shape for the feed. For blogs with a LOT of content, this can be a slow process. Luckily, I came across this Kent C. Dodds Twitter thread outlining how this problem could be fixed. My biggest takeaways:
- Limit the number of posts, RSS feeds will check for updates often and heavily cache old posts
- Don't rely on complex image transformations (like
gatsby-transformer-sharp) - Content doesn't need to be posted full in its original form, it can be transformed in the
serializefunction.
Since I'm not using Gatsby's image processing, the only thing I really needed to worry about was making sure that my images would point to the correct url instead of trying to look for the relative path at whichever new site I was sharing posts to. I also wasn't too concerned with limiting the number of post since I'm fine with a "Read More on My Full Site" button at the bottom of my second Gatsby site.
gatsby-plugin-feed takes a serialize function which eventually ends up running in Gatsby's node process. (link?) This function will run a GraphQL query against the markdown content and then return an object that will be used to create XML for RSS. Mine looks something like this:
query: `
{
site {
siteMetadata {
siteUrl
}
},
allMdx (
limit: 12,
sort: { order: DESC, fields: [frontmatter ___meta___ date]},
) {
edges {
node {
fields {
slug
}
frontmatter {
title
meta {
excerpt
date
categories
tags
}
}
generatedExcerpt: excerpt
internal {
content
}
}
}
}
}
`
serialize: ({query: {site, allMdx }}) => {
return allMdx.edges.map(edge => {
const body = edge.node.internal.content.replace(/<img src="\//g, `<img src="${site.siteMetadata.siteUrl}/`)
const url = `${site.siteMetadata.siteUrl}/${edge.node.fields.slug}`
return {
title: edge.node.frontmatter.title,
date: edge.node.frontmatter.meta.date,
url: url,
categories: [...categories, ...tags],
custom_elements: [
{'excerpt': excerpt || generatedExcerpt},
{'content:encoded': body}
],
}
})
}
These might seem obvious, but there's a couple of things I wanted to make sure and call out in the serialize function in regards to making sure links would be handled correctly on different domains. Both the post slugs (/blog/post-name) and image urls (/images/uploads/image-name.jpg) use relative paths, meaning that their urls are relative to the current domain. For things like posting images or doing links back to the original url of the post, I needed to query the url of the original site and append it to the beginning of my relative paths in the serialize function.
Also worth noting, gatsby-plugin-feed will automatically parse some fields, like title, date, and url, but anything extra can be passed in as objects into the custom_elements array.
Getting Data In
Much like getting data out of Gatsby, the easiest way to get data in is to also use a plugin. Gatsby has a ton of first and third party source plugins, and the benefit of this is that they can all be used in conjunction to synthesize many points of data into one GraphQL endpoint. That means that on my syndicated blog I could have some content, like an About Me page for example, in regular markdown while still having the blog post come from an external RSS source. This is the opposite of what I was trying to do, though. I wanted all data, even metadata about the blog, to be accessible in my rss.xml file.
gatsby-source-rss-feed was the plugin that I found that was the closest to what I needed, but to get the correct metadata as part of the file I had to submit a pull request to the plugin repo. This was fairly easy to figure out as it works almost exactly the opposite was as the process done in the gatsby-node.js file in the plugin used to create the feed. Instead of doing a query and transforming nodes into xml, this process makes it own request against a url passed to it and uses Gatsby's createNode action to well, create nodes. It then takes these nodes and assigns them to a type that can be queried elsewhere in the site during build time. The original plugin was only mapping through the item data of the feed to build the posts, so it was pretty straightforward to use the rest operator to get the rest of the data and pass it on to its own metadata type.
The plugin still needed to know what extra data to grab, so my config object looked like this:
{
resolve: `gatsby-source-rss-feed`,
options: {
name: `RyanBlog`,
url: `https://www.ryanfiller.com/blog/code.rss.xml`,
parserOption: {
customFields: {
feed: ['siteTitle', 'siteUrl', 'headshot', 'about'],
item: ['content:encoded', 'excerpt'],
}
}
}
}
Formatting Generic Data Back Into Gatsby
From here, creating posts worked just like it would on most any other Gatsby site. Whatever value is passed into the name option of the plugin gets concatenated into a type that can be queried and transformed into pages.
{
meta: feedRyanBlogMeta {
siteUrl
}
posts: allFeedRyanBlog {
edges {
node {
fields {
id
slug
}
title
pubDate
link
categories
excerpt
content {
encoded
}
}
}
}
}
Most data is already in the format that it needs to be, with the exception of the post slug. The full url, including my original domain name that I tacked on during the feed construction, comes through as the post's link data, so when creating that field for Gatsby I made sure to strip that part off.
exports.onCreateNode = ({ node, actions }) => {
const { createNodeField } = actions
if (node.internal.type === 'FeedRyanBlog') {
createNodeField({
node,
name: 'slug',
value: node.link.split('.com')[1]
})
}
}
Telling the Sites When To Build
Now that one site is able to pull data directly from the other, I need a mechanism for that site to let the other one know that new content exists and a new build needs to be started. Luckily, Netlify has a very straightforward way to add build hooks to any site!
This works by configuring two things. First, on the auto-deploying site, a new build hook needs to be added. This is a url that can be POSTed to that will notify Netlify to start a new build. It lives at Settings > Deploys > Build Hooks.
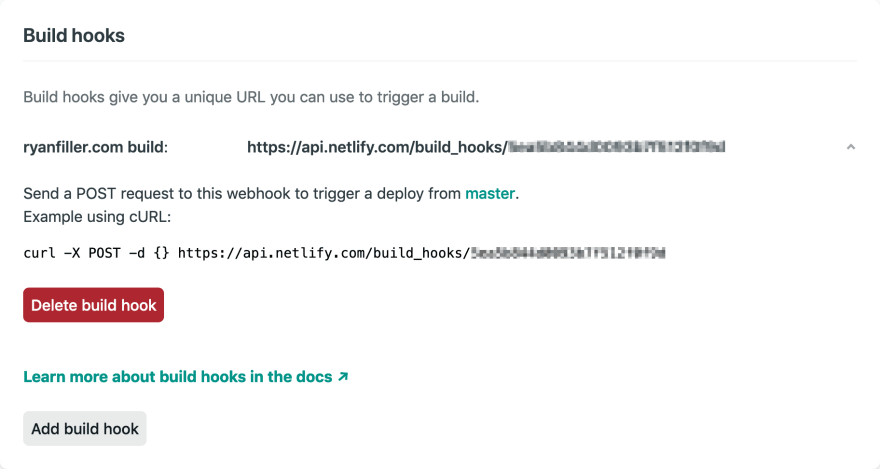
Once that url has been created, a matching Deploy Notification needs to be created on the original site. It lives at Settings > Deploys > Deploy Notifications.

Ta-da! Now when the first site successfully completes a build, magic will happen on the internet and the second site automatically will to!
Quick SEO Notes
I'm far from an SEO expert, but I do know that having the same content live on multiple urls across the web can sometimes confuse search engines. For this situation exactly, a rel="canonical" link can be added to any syndicated posts and point back to the main blog domain. This Google Webmaster article does a good job elaborating exactly why this is important.
If all goes well with this post, who knows - you might even be reading it on ryan.beardedrobots, or dev.to, or an RSS app right now!
Posted on April 28, 2020
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.