Computed Tomography (CT) Diagnosis of COVID-19 using Supervised Learning

Ruthvik Raja M.V
Posted on April 28, 2021

During the Corona Virus outbreak, CT(Computed Tomography) is widely used for diagnosing COVID-19 patients. Due to many privacy concerns the CT images are not publicly available to implement Machine Learning and Deep Learning techniques for research and development of the AI-enabled algorithms to classify the CT images. To address this problem some researchers has created an open source dataset COVID- CT, which consists of 349 COVID-19 diagnosed CT images from 216 patients and 397 Non COVID-19 CT images. The usage of this dataset is confirmed by the senior Radiologist who has been treating and diagnosing COVID-19 patients since the outbreak of the novel Corona Virus. We also performed Machine Learning models like K-Nearest Neighbours, Support Vector Machine, Logistic regression and Deep Learning techniques like Convolutional Neural Network on the dataset to diagnose COVID-19.
The number of CT-Covid and CT-Non Covid images available publicly were only 349 and 397. There are so many images that are available online in various database repositories but due to so many restrictions imposed by the hospitals we were unable to retrieve the images. So, to train the CNN or Machine Learning model we used Data Augmentation to generate all kind of possible images from a pre-defined training set. This helps the model to not overfit and to produce high accuracy score by training under all possible scenarios. Initially we used Machine Learning models like K-Nearest Neighbours (KNN), Support Vector Machines (SVM), Logistic Regression, Decision Trees etc but these models failed to produce high accuracy even after performing Hyper parameter tuning. The KNN model produced a highest accuracy score of 64% when k=7 and distance metric is Manhattan. The Logistic Regression achieved a highest accuracy score of 60% when we set the hyper-parameter number of iterations to 1000. The SVM algorithm achieved a accuracy score of 63% and finally the Decision Trees failed to execute in the allowed time because the size of each input image is 480x480, there are nearly 2000 images so the model failed to create decision trees in the allowed time complexity.
Finally we have implemented the CNN model by loading all the original and generated images, then all the images are re- scaled to same shape because each image has different size and then the images are appended with the labels(0 for Non-Covid and 1 for Covid). After labelling the images we have split and shuffled the images for training(80%) and testing(20%) the CNN model.
The complete details about the Project and the Dataset can be found in the following link: https://github.com/ruthvikraja/COVID-19-CT
The Final Results are as Follows:
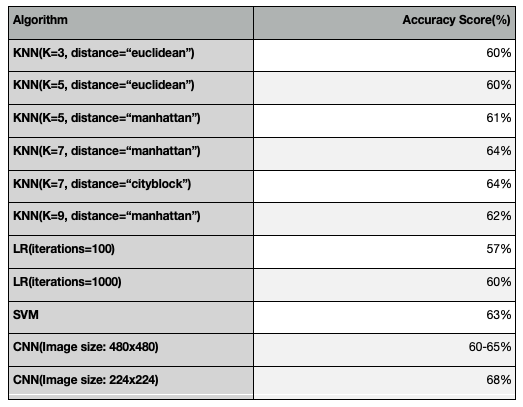
The accuracy score of the CNN model can be further increased by implementing Transfer Learning and Hyper Parameter Tuning.
import matplotlib.pyplot as plt # Importing all the necessary libraries
import cv2
import os
import tensorflow as tf
from tensorflow import keras
import numpy as np
import random
def read_txt(txt_path): # This function will return a list of data that is present in the text file.
with open(txt_path) as f:
lines = f.readlines()
txt_data = [line.strip() for line in lines]
return txt_data
def load_images_from_folder(folder,lst): # This function will return all the images that are matched with the names present in lst
images = []
for filename in os.listdir(folder):
#print(filename);
if(filename in lst):
img = cv2.imread(os.path.join(folder,filename),0) # consists of 3 channels so, converting it into a gray scale image
if img is not None:
images.append(img)
return images
# Non-COVID images for Training
x1=read_txt("/Users/ruthvikrajam.v/Desktop/text_files/trainCT_NONCOVID.txt");
x2=read_txt("/Users/ruthvikrajam.v/Desktop/text_files/valCT_NONCOVID.txt");
x3=x1+x2 # Combining training and validation text files
x1_images=load_images_from_folder("/Users/ruthvikrajam.v/Desktop/images/CT_NONCOVID",x3)
# All the images are reshaped to 224x224, initially all the images are reshaped to 480x480 but to achieve high accuracy score
# the images are reshaped to 224x224
x1_images_480=[]
for i in x1_images:
x1_images_480.append(cv2.resize(i,(224,224)));
# Non-COVID images for Testing
y1=read_txt("/Users/ruthvikrajam.v/Desktop/text_files/testCT_NONCOVID.txt");
y1_images=load_images_from_folder("/Users/ruthvikrajam.v/Desktop/images/CT_NONCOVID",y1)
y1_images_480=[]
for i in y1_images:
y1_images_480.append(cv2.resize(i,(224,224)));
# COVID-19 images for Training
x3=read_txt("/Users/ruthvikrajam.v/Desktop/text_files/trainCT_COVID.txt");
x4=read_txt("/Users/ruthvikrajam.v/Desktop/text_files/valCT_COVID.txt");
x5=x3+x4 # Combining training and validation text files
x3_images=load_images_from_folder("/Users/ruthvikrajam.v/Desktop/images/CT_COVID",x5)
x3_images_480=[]
for i in x3_images:
x3_images_480.append(cv2.resize(i,(224,224)));
# COVID-19 images for Testing
y2=read_txt("/Users/ruthvikrajam.v/Desktop/text_files/testCT_COVID.txt");
y2_images=load_images_from_folder("/Users/ruthvikrajam.v/Desktop/images/CT_COVID",y2)
y2_images_480=[]
for i in y2_images:
y2_images_480.append(cv2.resize(i,(224,224)));
# Data Augmentation(DA) STARTS:
# The following code is already executed and all the images are available in the folder CT_COVID_DA_224 and CT_NonCOVID_DA_224
from keras.preprocessing.image import ImageDataGenerator
datagen=ImageDataGenerator(width_shift_range=0.2, height_shift_range=0.2,shear_range=0.2,zoom_range=0.2,fill_mode="nearest")
x1_images_480_array=np.array(x1_images_480) # converting list of images to array of images
x3_images_480_array=np.array(x3_images_480)
x1_images_480_array_reshape = x1_images_480_array.reshape((x1_images_480_array.shape[0],224,224,1)) # Denotes: Number of images, shape of each image, no of channels
x3_images_480_array_reshape = x3_images_480_array.reshape((x3_images_480_array.shape[0],224,224,1))
i=0
for batch in datagen.flow(x1_images_480_array_reshape,batch_size=1,save_to_dir="/Users/ruthvikrajam.v/Desktop/images/CT_NONCOVID_DA_224", save_format="png",save_prefix="non_covid"):
i=i+1;
if i>1000:
break;
i=0
for batch in datagen.flow(x3_images_480_array_reshape,batch_size=1,save_to_dir="/Users/ruthvikrajam.v/Desktop/images/CT_COVID_DA_224", save_format="png",save_prefix="covid"):
i=i+1;
if i>1000:
break;
# Data Augmentation ENDS:
# Defining a function to load the newly generated images:
def load_images_from_folder_da(folder):
images = []
for filename in os.listdir(folder):
#print(filename);
img = cv2.imread(os.path.join(folder,filename),0)
if img is not None:
images.append(img)
return images
imgs1=load_images_from_folder_da("/Users/ruthvikrajam.v/Desktop/images/CT_NonCOVID_DA_224") # Newly generated Non-Covid images
imgs2=load_images_from_folder_da("/Users/ruthvikrajam.v/Desktop/images/CT_COVID_DA_224") # Newly generated Covid images
# Combining old and newly generated images:
noncovid_train=[]
noncovid_train=x1_images_480 + imgs1
covid_train=[]
covid_train=x3_images_480 + imgs2
# Assigning y values i.e labels 0 and 1 for non-covid and covid images:
# Training
noncovid_training=[]
j=0
for i in noncovid_train:
noncovid_training.append([noncovid_train[j],0]) # Assigning 0 for Non-COVID images
j=j+1
covid_training=[]
j=0
for i in covid_train:
covid_training.append([covid_train[j],1]) # Assigning 1 for COVID-19 images
j=j+1
training=noncovid_training+covid_training # Combining training and testing data
random.shuffle(training) # Shuffling the entire training set
# Testing
noncovid_testing=[]
j=0
for i in y1_images_480:
noncovid_testing.append([y1_images_480[j],0])
j=j+1
covid_testing=[]
j=0
for i in y2_images_480:
covid_testing.append([y2_images_480[j],1])
j=j+1
testing=noncovid_testing+covid_testing
random.shuffle(testing) # Shuffling the entire test set
# Splitting the data and reshaping it for training and testing the CNN model
X_train_CNN=[]
y_train_CNN=[]
for features,labels in training:
X_train_CNN.append(features)
y_train_CNN.append(labels)
X_train_CNN=np.array(X_train_CNN).reshape(-1,224,224,1) # -1 denotes the number of images, (480,480)->Denotes the size of the image
y_train_CNN=np.array(y_train_CNN)
X_test_CNN=[]
y_test_CNN=[]
for features,labels in testing:
X_test_CNN.append(features)
y_test_CNN.append(labels)
X_test_CNN=np.array(X_test_CNN).reshape(-1,224,224,1)
y_test_CNN=np.array(y_test_CNN)
###############################################################################
## CNN
import tensorflow as tf # Importing necessary libraries for CNN model
from tensorflow.keras.models import Sequential # Sequential is a class
from tensorflow.keras.layers import Dense, Dropout, Activation, Flatten, Conv2D, MaxPooling2D
X_train_CNN=X_train_CNN/255.0 # Normalizing the input values for faster computation
X_test_CNN=X_test_CNN/255.0
model= Sequential() # This will create models layer by layer, the sequential model is a linear stack of layers
model.add(Conv2D(256, (3, 3), input_shape=X_train_CNN.shape[1:]))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(256, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2))) # These are done for feature extraction
model.add(Flatten()) # This converts our 3D feature maps to 1D feature vectors
model.add(Dense(64))
model.add(Dense(1))
model.add(Activation('sigmoid'))
model.compile(loss="binary_crossentropy", optimizer="adam", metrics=["accuracy"]);
model.fit(X_train_CNN, y_train_CNN, batch_size=32, steps_per_epoch=10, epochs=100)
# epochs, validation_split = 0.2
from sklearn.metrics import accuracy_score # Predicting the accuracy score for the CNN model
y_pred = model.predict(X_test_CNN)
y_pred = (y_pred > 0.5)
score=accuracy_score(y_pred,y_test_CNN)
print(score)
################################################################################
# MACHINE LEARNING MODELS::
# let us try KNN classification
# for this we got the X and y from above for training the data
# for testing let us consider X_test and y_test
X_train=[]
y_train=[]
for features,labels in training:
X_train.append(features)
y_train.append(labels)
# For training and testing the Machine Learning models each image in the X_train, X_test has to be flattened:
X_train_ML=[]
for i in X_train:
X_train_ML.append(i.flatten())
X_train_ML=np.array(X_train_ML)
y_train_ML=np.array(y_train)
X_test=[]
y_test=[]
for features,labels in testing:
X_test.append(features)
y_test.append(labels)
X_test_ML=[]
for i in X_test:
X_test_ML.append(i.flatten())
X_test_ML=np.array(X_test_ML) # X_test_ML and y_test_ML are inputs and outputs for ML model
y_test_ML=np.array(y_test)
# knn 5 manhattan 61%
# knn 5 euclidean 60%
# knn 3 euclidean 60%
# knn 7 manhattan 64%
# knn 7 cityblock 64%
# knn 9 manhattan 62%, for high k values the accuracy is almost same and sometimes it is low
from sklearn.neighbors import KNeighborsClassifier
# This is used to implement KNN classifier
from sklearn.metrics import accuracy_score
# Used to check the goodness of our model
KNN_classifier1=KNeighborsClassifier(n_neighbors=7,metric="manhattan",n_jobs=-1) # Try for different k values and metric
KNN_classifier1.fit(X_train_ML,y_train_ML)
predict=KNN_classifier1.predict(X_test_ML)
accuracyscore1=accuracy_score(y_test_ML,predict)
print(accuracyscore1*100)
# XG BOOST
# This has took more time than CNN but failed to produce the output
# So, decision trees wont work for for image classification
import xgboost as xgb
xgb_clf=xgb.XGBClassifier(max_depth=5,n_estimators=1000,learning_rate=0.01,n_jobs=-1)
xgb_clf.fit(X_train_ML,y_train_ML)
print(accuracy_score(y_test_ML,xgb_clf.predict(X_test_ML)))
### LOGISTIC REGRESSION # 100 iterations -->57%, 1000 -->60%, 60% only for higher iterations also.....
from sklearn.linear_model import LogisticRegression
logistic=LogisticRegression(max_iter=1000)
logistic.fit(X_train_ML,y_train_ML)
print(accuracy_score(y_test_ML,logistic.predict(X_test_ML)))
## Support vector machines (SVM) for binary image classification
# accuracy score --> 63%
from sklearn.svm import SVC #(support vector classifier)
clf=SVC()
clf.fit(X_train_ML,y_train_ML)
print(accuracy_score(y_test_ML,clf.predict(X_test_ML)))
Posted on April 28, 2021
Join Our Newsletter. No Spam, Only the good stuff.
Sign up to receive the latest update from our blog.
Related